Python加载txt数据乱码问题升级版解决方法
作者:数据人阿多
- 确定文件编码
当不知道别人给的txt文件不知道是什么编码时,可以通过chardet模块来判断是属于什么编码 chardet模块是第三方模块,需要手动安装
import chardet
data= open('111.TXT','rb').readline()
#读取一行数据即可,不用全部读取,节省时间,'rb' 指定打开文件时用二进制方法
print(data) #预览一下二进制数据
chardet.detect(data) #判断编码
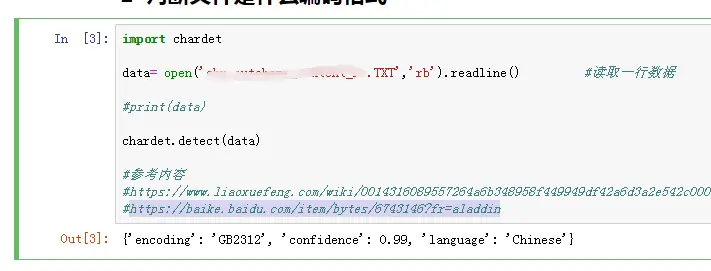
由输出结果可以判定,该txt是'GB2312'编码概率是99%,confidence: 0.99 ,所以可以确定该txt编码格式就是'GB2312'
- 用判断出来的编码打开txt文件
f = open('111.TXT','r',encoding='gb2312') #gb2312<gbk<gb18030
data=f.readlines() #把数据读取到列表里面
f.close()
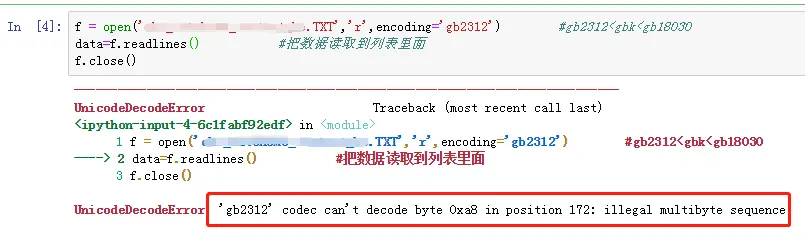
这时出现错误,为什么已经判断文件就是'GB2312',打开还是报错呢???
难道是判断的编码错误的,然后再去读取原txt文件,多读取了一些数据再判断是什么编码,结果还是'GB2312',这是为什么呢???
- 设置忽略非法字符参数
查看了open函数的参数后,里面有个errors参数,有三个级别可选,一般选择ignore即可
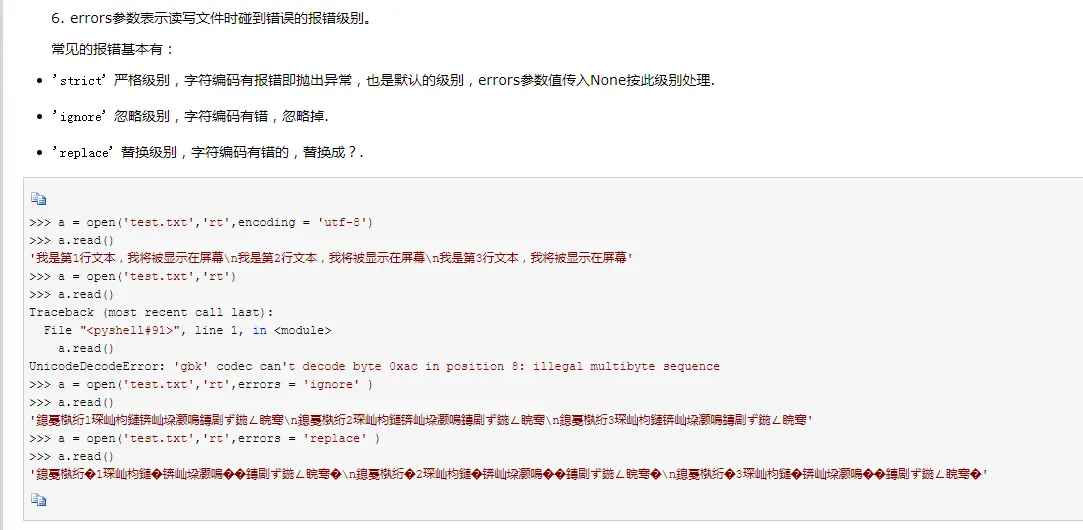
- 再次去打开文件
设置errors='ignore'后,成功打开文件
f = open('111.TXT','r',encoding='gb2312',errors='ignore')
#忽略非法字符 gb2312<gbk<gb18030
data=f.readlines() #把数据读取到列表里面
f.close()
- 思考:为什么会有不能识别的字符呢
- 网络爬取的文字,里面有一些表情、其他语言,例如:韩语、日语,不是中文的所能包含的,在再次解码时可能会报错
- 由于文件比较大,在文件拷贝时由于磁盘原因,可别字符被修改或遗漏
- 网络爬取时,信息包里面的字符错误,众所周知信息在传输时是1或0,在网线里面是波形或者激光,如果在较远传输过程中,有可能会丢失信息等一些情况,能确保99%的信息量已经很好了
参考
- https://www.cnblogs.com/sesshoumaru/p/6047046.html
- https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001510905171877ca6fdf08614e446e835ea5d9bce75cf5000
- https://baike.baidu.com/item/bytes/6743146?fr=aladdin
以上是自己在处理数据时遇到的一些阻碍,分享出来供大家参考,欢迎指正与交流