Python-利用数据分布直方图来确定合适的阈值
作者:数据人阿多
背景
在数据分析中总会碰见 阈(yu)值 这个问题,有人可能就是拍脑袋,根据自己的经验随便确定一个值,而且效果还不错。但既然是在分析数据,那就要确定一个合适的值来作为阈值,这样比较有说服力,更 make sense。
工作中要确定阈值的场景有很多:
案例1: 声纹相似度
人的声纹信息可以说是自己的另一个身份ID,可以根据声纹信息确定是否是同一个人,比如:微信app登陆时让用户读一个6位数,验证是否是该用户的声音,那微信是怎么来确定这个声音就是你呢?这里简化一下问题,假如微信服务器存的是根据你的声音提取出来的一个特征向量,那就是从你这次读的语音提取的特征向量与微信服务器存的特征向量的相似度问题,由于每次说话的音调不同,两个向量可能不完全相同,所以两个向量达到80%相似,还是90%相似,还是99%相似,微信让你登录呢,这里的相似度就是一个阈值。
案例2: NLP训练语句长度
在进行NLP模型训练时,提供的语料里面的每句话长度均不一样,那么在训练时应该怎么选取这个长度呢?如果用最大的长度,那么内存可能会暴增,如果用的语句长度太短,那么可能会遗漏一部分有用的信息,所以这里的句子长度就是一个阈值。
数据分布直方图
可以先利用数据分布直方图来确定数据的一个大概分布情况,
-
如果数据是服从标准正态分布,那么阈值可以定义为 x ± 3sigma 或者 x ± 6sigma;

-
如果数据是一个偏分布,那么可以取一个分位数值90%或者95%,这个要视具体情况而定
下面列举一个偏分布的情况:
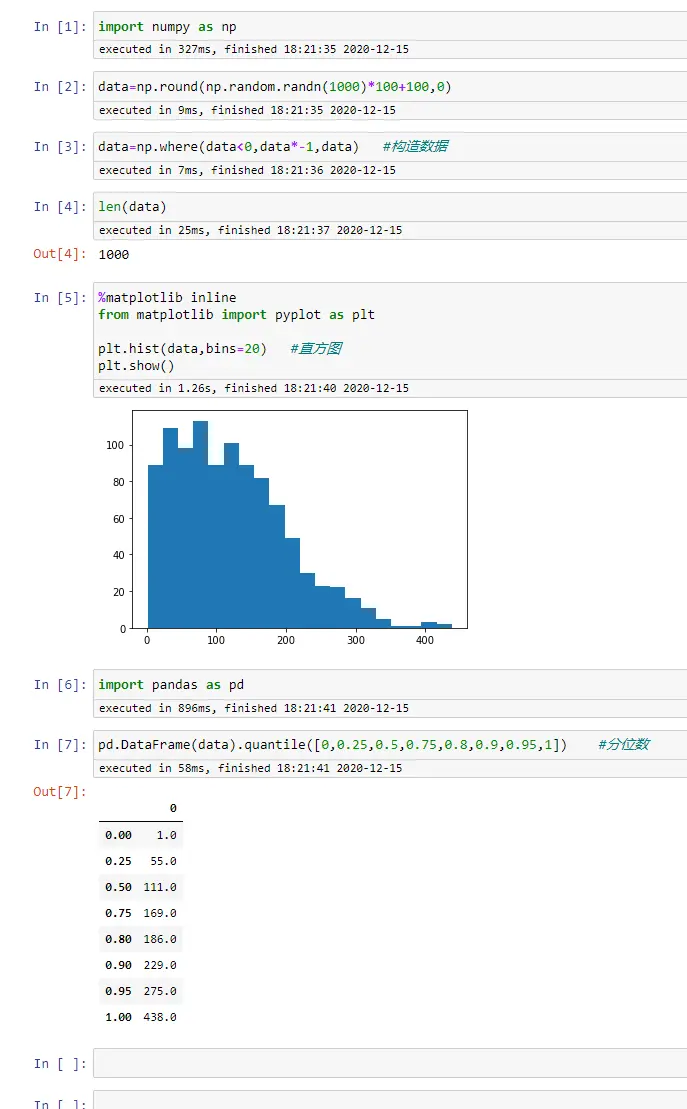
import numpy as np
data=np.round(np.random.randn(1000)*100+100,0)
data=np.where(data<0,data*-1,data) #构造数据
len(data)
%matplotlib inline
from matplotlib import pyplot as plt
plt.hist(data,bins=20) #直方图
plt.show()
import pandas as pd
pd.DataFrame(data).quantile([0,0.25,0.5,0.75,0.8,0.9,0.95,1]) #分位数
上面的模拟数据是一个偏分布情况,那么可以用一个分位数来确定,如果阈值取300,那么就可以包括最少95%的情况,如果想要更精确一些,那么阈值可以取400等更大的一个值
以上是在项目中的一个小分析
往期相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货