Python pandas-数据筛选与赋值升级版详解
作者:数据人阿多
数据筛选背景
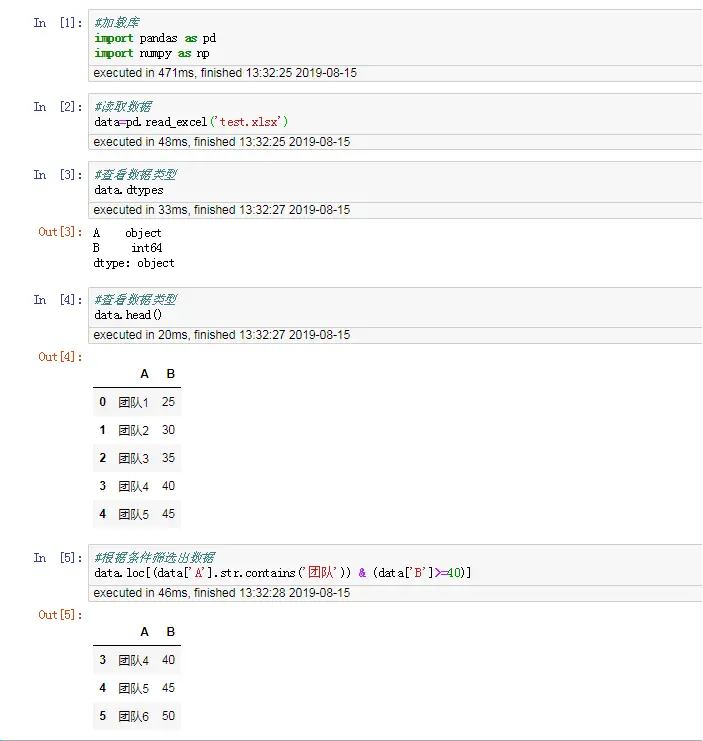
在处理数据时,我们可能希望从数据库里面筛选出符合特定条件的记录(个案或样本,不同的行业叫法不一样),平常大家对Excel筛选很熟悉,比如从A字段(变量或特征)包含“团队”,B字段大于等于40,筛选出符合这两个条件的记录,如下图所示:

pandas处理
- 正确代码
#加载库
import pandas as pd
import numpy as np
#读取数据
data=pd.read_excel('test.xlsx')
#查看数据类型
data.dtypes
#查看数据前5行
data.head()
#根据条件筛选出数据
data.loc[(data['A'].str.contains('团队')) & (data['B']>=40)]
#data[(data['A'].str.contains('团队')) & (data['B']>=40)] #这两行都可以
- 错误代码
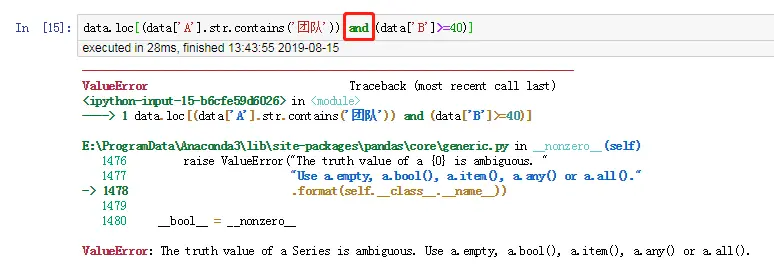
- 位运算符
&与|,而不是逻辑运算符and与or,两者是有区别的
data.loc[(data['A'].str.contains('团队')) and (data['B']>=40)]
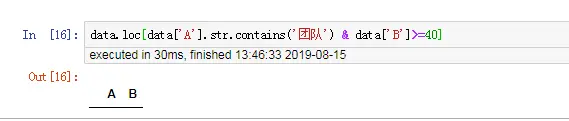
- 缺少括号
(),导致筛选不出数据,但是不报错
data.loc[data['A'].str.contains('团队') & data['B']>=40]
经过多方查找原因,动手实践,这个问题貌似没有帖子仔细进行解释,那这是为什么筛选不出来数据呢,加了括号就可以,可能有同学一下子就明白了,运算符的顺序,对,位运算符&的优先级 高于 比较运算符>=,其实也就是只对后面的条件加上括号即可,但是考虑到逻辑严谨性,最好把所有条件都括起来,详情参考这篇文章Python 3 的运算符及优先级
pandas赋值操作
- 正确代码
注意避免链式操作导致SettingwithCopyWarning ,最详细的解释,请参考这篇文章Pandas 中 SettingwithCopyWarning 的原理和解决方案
#赋值操作
data.loc[(data['A'].str.contains('团队')) & (data['B']>=40),'C']='是'
data
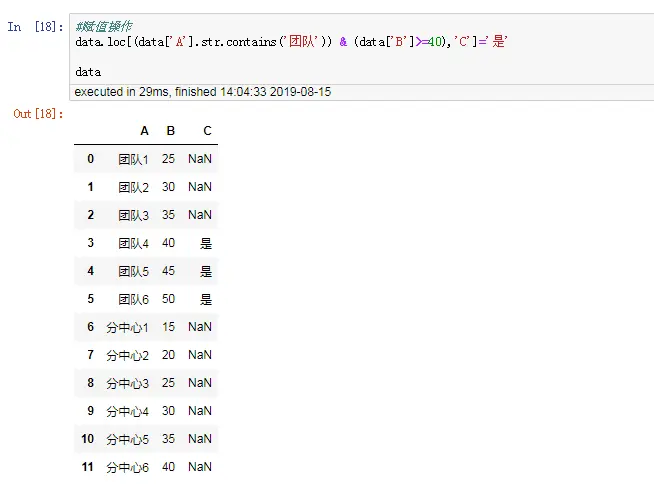
及时原来的数据框里面没有C列变量,但是在赋值时可以直接指定,数据框会自动生成这一列变量
- 错误代码
- 缺少
.loc导致报错提示不可哈希,对这个不是很懂
data[(data['A'].str.contains('团队')) & (data['B']>=40),'C']='是'
 建议为了使代码规范,在根据条件筛选时就把
建议为了使代码规范,在根据条件筛选时就把.loc带上,防止后期出错
- 链式操作,提示
SettingwithCopyWarning
data.loc[(data['A'].str.contains('团队')) & (data['B']>=40)]['C']='是'
data
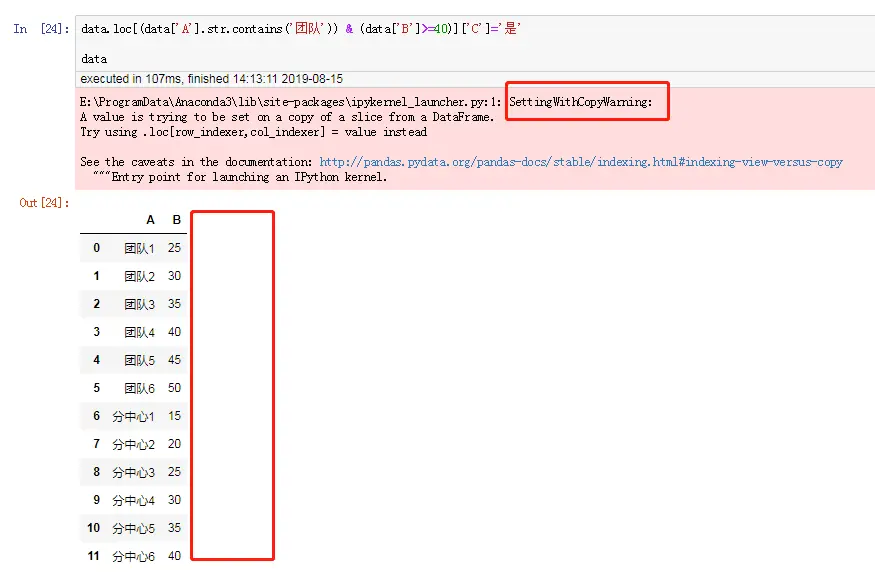
为什么会出现这种情况,请详细阅读这篇文章Pandas 中 SettingwithCopyWarning 的原理和解决方案
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货