简介
笔名:数据人阿多
小编拥有超过十余年的数据领域工作经验,技术路径从最初的 Excel 数据处理开始,逐步走向基于分布式集群的 Hive 数据开发与分析
- 接触的技术范畴也在不断扩展
早期从 Excel 中的统计与数据分析起步,随后逐渐深入机器学习领域,实践过决策树、聚类分析等经典算法,并进一步涉足自然语言处理(NLP)与计算机视觉(CV),尝试将多种智能技术应用于实际业务问题
- 工具与编程语言层面也持续演进
从借助 Excel VBA 实现办公自动化,到系统学习并运用 Python、Hive、Tableau 等专业工具,逐渐成长为一名兼具数据分析与数据开发能力的技术实践者
- 使用的操作系统环境也从 Windows 逐步拓展至 Linux
从最初的学习基本命令与系统操作,到能够在 Linux 环境中部署和维护自己的轻量级服务
一路走来,虽然工具在迭代、技术在演进,但是不变的是围绕数据价值的持续探索与务实构建
其他平台
- 微信公众号:DataShare
- QQ群:581146525
作者:数据人阿多
背景
NumPy(Numerical Python)诞生已经过去了 15 年,前一段时间NumPy 核心开发团队的论文终于发表,详细介绍了使用 NumPy 的数组编程(Array programming),并且登上了Nature 。
NumPy 是什么?它是大名鼎鼎的使用 Python 进行科学计算的基础软件包,是 Python 生态系统中数据分析、机器学习、科学计算的主力军,极大简化了向量与矩阵的操作处理。
- 功能强大的 N 维数组对象
- 精密广播功能函数
- 集成 C/C++ 和 Fortran 代码的工具
- 强大的线性代数、傅立叶变换和随机数功能
在平时数据处理中,大部分人用的都是Pandas,用Numpy的场景可能比较少,但是Pandas是基于Numpy实现的更高级的库,使大家用起来更方便。但在做深度学习时用Numpy比较多,比如:图像处理,图片里面其实都是Numpy数组;音频处理;文本处理等等。
下面为大家介绍一些Numpy的常用基础
Numpy基础
- 安装
由于Numpy是第三方库,默认是不集成在Python里面,所以就需要手动安装一下: 如果你安装的是Anaconda,那么就不用再安装了,请忽略 如果你是从官方网站下载的Python,那么你就需要手动安装一下这个库
#指定阿里云镜像,安装更快
pip install numpy -i https://mirrors.aliyun.com/pypi/simple/
- 导入
默认成规,numpy导入后命名为np,所以在python脚本(程序)里面看见np一般都是代表numpy
import numpy as np
- 认识Ndarray
计算机里面能计算的就是数字,也就是数学里面的各种数字,我们都知道数学里面的数组可以有多层,也就是多维,1维就是向量,2维就是矩阵,3维就是$x y z$坐标轴构成的空间(形象理解),但体现在numpy中就是N 维数组对象ndarray,它是一系列同类型数据的集合。
1维:
>>> import numpy as np
>>> a=np.array([1,2,3,4])
>>> print(a)
[1 2 3 4]
>>> type(a)
<class 'numpy.ndarray'>
>>> a.ndim
1
2维:
>>> import numpy as np
>>> b=np.array([[1,2,3],[4,5,6]])
>>> print(b)
[[1 2 3]
[4 5 6]]
>>> type(b)
<class 'numpy.ndarray'>
>>> b.ndim
2
- 切片和索引
切片、索引与python内置的列表、字符串的切片和索引基本一样,如果理解了列表的切片和索引,那么ndarray对象就不在话下
>>> import numpy as np
>>> a=np.arange(10)
>>> print(a)
[0 1 2 3 4 5 6 7 8 9]
>>> type(a)
<class 'numpy.ndarray'>
>>> a.ndim
1
>>> a[:5]
array([0, 1, 2, 3, 4])
>>> a[7:]
array([7, 8, 9])
>>> a[3:6]
array([3, 4, 5])
>>> a[::2]
array([0, 2, 4, 6, 8])
>>> a[::-1]
array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
>>> a[0]
0
>>> a[5]
5
- 数组操作
修改数组形状
>>> import numpy as np
>>> a=np.arange(10)
>>> print(a)
[0 1 2 3 4 5 6 7 8 9]
>>> type(a)
<class 'numpy.ndarray'>
>>> a.ndim
1
>>> b=a.reshape(5,2)
>>> print(b)
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
>>> b.ndim
2
>>> c=a.reshape(2,5)
>>> print(c)
[[0 1 2 3 4]
[5 6 7 8 9]]
>>> c.ndim
2
数组转置
>>> import numpy as np
>>> a=np.arange(12).reshape(3,4)
>>> print(a)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
>>> np.transpose(a)
array([[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]])
>>> a.T
array([[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]])
数组连接
concatenate、stack、hstack、vstack这个几个函数均是数组连接,原理基本都一样,只要理解了其中一个,其他的都很好理解,这里只介绍concatenate
>>> import numpy as np
>>> a=np.array([[1,2],[3,4]]
... )
>>> b=np.array([[5,6],[7,8]])
>>> np.con
np.concatenate( np.conj( np.conjugate( np.convolve(
>>> np.concatenate([a,b],axis=0) #沿着0轴拼接
array([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
>>> np.concatenate([a,b],axis=1) #沿着1轴拼接
array([[1, 2, 5, 6],
[3, 4, 7, 8]])
修改数组维度
>>> import numpy as np
>>> x=np.array([1,2])
>>> np.expand_dims(x,axis=0)
array([[1, 2]])
>>> np.expand_dims(x,axis=1)
array([[1],
[2]])
>>> y=np.array([[1,2]])
>>> np.squeeze(y) #从给定数组的形状中删除一维,当前维必须等于1
array([1, 2])
- 数组计算
>>> import numpy as np
>>> a1=np.array([1,2,3,4])
>>> a2=np.array([5,5,5,5])
>>> a1+a2
array([6, 7, 8, 9])
>>> np.add(a1,a2)
array([6, 7, 8, 9])
>>> a1-a2
array([-4, -3, -2, -1])
>>> np.subtract(a1,a2)
array([-4, -3, -2, -1])
>>> a1*a2
array([ 5, 10, 15, 20])
>>> np.multiply(a1,a2)
array([ 5, 10, 15, 20])
>>> a1/a2
array([0.2, 0.4, 0.6, 0.8])
>>> np.divide(a1,a2)
array([0.2, 0.4, 0.6, 0.8])
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号DataShare,不定期分享干货
作者:数据人阿多
背景
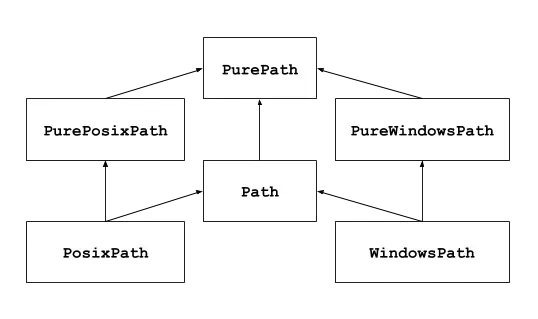
pathlib 标准库是在 Python3.4 引入,到现在最近版 3.11 已更新了好几个版本,主要是用于路径操作,相比之前的路径操作方法 os.path 有一些优势,有兴趣的同学可以学习下
小编环境
import sys
print('python 版本:',sys.version.split('|')[0]) #python 版本: 3.11.4
主要方法、函数
该模块中主要使用的是 Path 类
from pathlib import Path
Path.cwd() #WindowsPath('D:/桌面/Python/标准库')
Path.home() #WindowsPath('C:/Users/admin')
file = Path('pathlib_demo1.py')
print(file) #WindowsPath('pathlib_demo1.py')
file.resolve() #WindowsPath('D:/桌面/Python/标准库/pathlib_demo1.py')
file = Path('pathlib_demo1.py')
print(file) #WindowsPath('pathlib_demo1.py')
file.stat()
'''
os.stat_result(st_mode=33206, st_ino=1970324837176895, st_dev=2522074357,
st_nlink=1, st_uid=0, st_gid=0, st_size=273,
st_atime=1695642854, st_mtime=1695611301, st_ctime=1695611241)
'''
#文件大小
file.stat().st_size #273B
#最近访问时间 access ,It represents the time of most recent access
file.stat().st_atime #1695625134.9083948
#创建时间 create,It represents the time of most recent metadata change on Unix and creation time on Windows.
file.stat().st_ctime #1695611241.5981772
#修改时间 modify,It represents the time of most recent content modification
file.stat().st_mtime #1695611301.1193473
for f in path.iterdir():
print(f)
print('is_file:',f.is_file()) #判断是否为文件
print('is_dir:',f.is_dir()) #判断是否为文件夹
print('='*30)
'''
D:\桌面\Python\标准库\.ipynb_checkpoints
is_file: False
is_dir: True
==============================
D:\桌面\Python\标准库\pathlib.ipynb
is_file: True
is_dir: False
==============================
D:\桌面\Python\标准库\pathlib_demo1.py
is_file: True
is_dir: False
==============================
'''
file=Path('D:\桌面\Python\标准库\pathlib_demo1.py')
file.name #'pathlib_demo1.py'
file.stem #'pathlib_demo1'
file.suffix #'.py'
file.parent #WindowsPath('D:/桌面/Python/标准库')
file.anchor #'D:\\'
file.parent.parent #WindowsPath('D:/桌面/Python')
#获取所有的父级路径,层层递进
list(file.parents)
'''
[WindowsPath('D:/桌面/Python/标准库'),
WindowsPath('D:/桌面/Python'),
WindowsPath('D:/桌面'),
WindowsPath('D:/')]
'''
支持2种方式
#第1种方式:使用 /
Path.home() / 'dir' / 'file.txt' #WindowsPath('C:/Users/admin/dir/file.txt')
#第2种方式:使用方法
Path.home().joinpath('dir', 'file.txt') #WindowsPath('C:/Users/admin/dir/file.txt')
#当前文件件里面是否存在 子目录 archive/demo.txt 文件
Path("archive/demo.txt").exists() #False
#当前文件件里面是否存在 二级子目录 dir/subdir
Path('dir/subdir').exists() #True
#当前文件件里面是否存在 pathlib_demo1.py 文件
Path("pathlib_demo1.py").exists() #True
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
注:本文章由ChatGPT gpt-3.5-turbo 生成,小编进行略微调整 提出的问题:heapq详细讲解
背景
最近小编在读《Python Cookbook》书籍时,遇到一个新的标准库heapq,该库主要涉及堆数据结构,自己之前没有用过,所以就问了一下 ChatGPT,给出的内容非常详细且容易理解,分享出来供大家参考
heapq介绍
heapq 是 Python 标准库中的一个基于堆的优先队列实现。它提供了一些函数来实现对列表中的元素进行加入、弹出、替换等操作,同时也支持对列表中的元素进行建堆、堆排序等高级功能。本文将详细介绍 heapq 的使用方法和内部实现原理。
基本用法
1、heapq.heappush 和 heapq.heappop
heapq.heappush(lst, item):将元素 item 加入到列表 lst 中,并保持 lst 始终为一个堆。
heapq.heappop(lst):从列表 lst 中弹出最小的元素,并保持 lst 始终为一个堆。
下面是一个示例:
import heapq
lst = [10, 30, 2, 20, 50] # 初始列表
heapq.heapify(lst) # 建堆
print(lst) # 输出 [2, 20, 10, 30, 50]
heapq.heappush(lst, 5) # 将 5 加入到 lst 中
print(lst) # 输出 [2, 5, 10, 30, 50, 20]
min_item = heapq.heappop(lst) # 弹出最小元素
print(min_item, lst) # 输出 2 [5, 20, 10, 30, 50]
2、heapq.heapreplace
heapq.heapreplace(lst, item):将最小元素替换为 item,并保持 lst 始终为一个堆。
这个函数相当于先执行 heapq.heappop(lst),再执行 heapq.heappush(lst, item)。使用该函数可以避免在先弹出再加入元素时,列表中出现不合法的状态。例如:
import heapq
lst = [10, 30, 2, 20, 50] # 初始列表
heapq.heapify(lst) # 建堆
print(lst) # 输出 [2, 20, 10, 30, 50]
heapq.heapreplace(lst, 5) # 用 5 替换最小元素 2
print(lst) # 输出 [5, 20, 10, 30, 50]
3、heapq.nlargest 和 heapq.nsmallest
heapq.nlargest(n, lst):返回列表 lst 中前 n 个最大的元素,按照从大到小的顺序排序。
heapq.nsmallest(n, lst):返回列表 lst 中前 n 个最小的元素,按照从小到大的顺序排序。
这两个函数的实现都是先使用 heapq.heappush 和 heapq.heappop 对列表进行处理,之后返回前 n 个元素。示例:
import heapq
lst = [10, 30, 2, 20, 50] # 初始列表
heapq.heapify(lst) # 建堆
print(lst) # 输出 [2, 20, 10, 30, 50]
print(heapq.nlargest(3, lst)) # 输出 [50, 30, 20]
print(heapq.nsmallest(3, lst)) # 输出 [2, 10, 20]
内部实现原理
Heap 是一种树形数据结构,通常用二叉树来实现。堆树的最上面是根节点,根节点下面的每个节点都比它自己所有的子节点都大(称为大根堆)或者都小(称为小根堆)。根据这个性质,堆树可以快速地找到最大或者最小元素。
Python 中的 heapq 模块实现是使用了一种叫做“二叉堆”的数据结构。二叉堆由固定数量的元素组成,堆的根节点包含所有能够在其中的元素中具有最小或者最大关键字的元素。我们称这个根节点为“最小堆”或者“最大堆”。堆中的每一个其他的节点都符合堆的性质:最小堆中的每一个节点都比它的子节点小;最大堆中的每一个节点都比它的子节点大。
这种数据结构可以直接用一个数组来实现,每个元素在数组中顺序存储,并按照堆的性质排列。数组的第一个元素是根节点,也就是堆的最小或最大元素。根据元素在数组中的位置,可以快速地用简单的数学运算找到它的子节点和父节点
二叉堆分为两种类型:最小堆和最大堆。在 Python 中的 heapq 模块中使用最小堆
Python 中,可以以列表的形式存储二叉堆,将列表作为二叉树,树的根节点即为第一个元素,树的子节点为列表中其左右孩子。具体来说,以第 k 个节点为例,其左孩子为第 2k+1 个节点,右孩子为第 2k+2 个节点,其父节点为第(k-1)//2 个节点
通过使用 heapq 模块提供的高效的堆算法,可以快速地实现对列表中元素的排序、寻找最大/最小值等常见操作
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
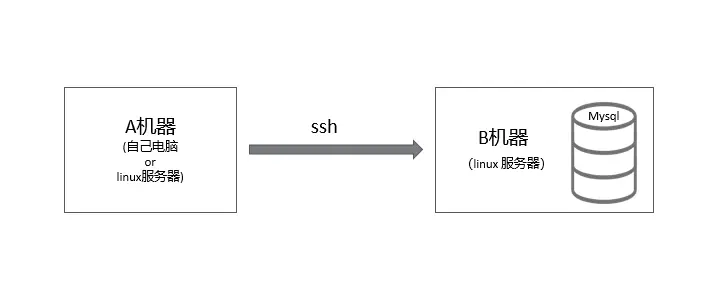
如果需要访问远程服务器的Mysql数据库,但是该Mysql数据库为了安全期间,安全措施设置为只允许本地连接(也就是你需要登录到该台服务器才能使用),其他远程连接是不可以直接访问,并且相应的端口也做了修改,那么就需要基于ssh来连接该数据库。这种方式连接数据库与Navicat里面界面化基于ssh连接一样。
安装支持库
- 如果要连接Mysql,首先需要安装pymysql
pip install pymysql
- 安装基于ssh的库sshtunnel
pip install sshtunnel #当前最新 0.3.1版
建议安装最新的sshtunnel库,旧版本库有一些bug
连接Mysql
基于ssh连接Mysql可以查看sshtunnel的文档,里面有一些案例
with SSHTunnelForwarder(
('192.168.1.1', 2222),
ssh_password='123456',
ssh_username='root',
remote_bind_address=('127.0.0.1', 3306)) as server:
print('SSH连接成功')
conn = pymysql.connect(host='127.0.0.1',
port=server.local_bind_port,
user='root',
database='data',
charset='utf8')
print('mysql数据库连接成功')
cursor = conn.cursor()
... #获取数据操作,此处省略
cursor.close()
conn.close()
自定义查询函数
可以对上面的连接进行封装为一个函数,方便其他地方使用
def mysql_ssh(sql,args=None):
with SSHTunnelForwarder(
('192.168.1.1', 2222),
ssh_password='123456',
ssh_username='root',
remote_bind_address=('127.0.0.1', 3306)) as server:
print('SSH连接成功')
conn = pymysql.connect(host='127.0.0.1',
port=server.local_bind_port,
user='root',
database='data',
charset='utf8')
print('mysql数据库连接成功')
cursor = conn.cursor()
print('游标获取成功')
try:
print(f'执行查询语句:{sql} 参数:{args}')
cursor.execute(sql,args)
print('数据查询成功')
conn.commit()
print('事务提交成功')
datas = cursor.fetchall()
success = True
except:
print('数据查询失败')
datas = None
success = False
print('正在关闭数据库连接')
cursor.close()
conn.close()
return datas, success
注意点:
- 在使用数据库时,
conn.commit()、cursor.close()、conn.close()这些一定要规范使用,防止不必要的bug - 传入参数时建议用这种方式
cursor.execute(sql,args),防止sql注入的风险
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注 DataShare (同微),不定期分享干货
作者:数据人阿多
前言
小编第一次了解正则,是在VBA编程时用到,当时看了很多的学习资料,来了解和学习正则。因为现在数据录入、数据存放相对都比较规范,使用正则的场景越来越少,但运用正则在杂乱的数据中提取一些有用数据还是很方便,最近阅读书籍时又看到了正则相关的内容,于是总结了一下,分享出来,供大家参考学习
官方文档:https://docs.python.org/zh-cn/3/library/re.html
Excelhome精选正则文章
正则文章:正则表达式入门与提高---VBA平台的正则学习参考资料
地址:https://club.excelhome.net/thread-1128647-1-3.html
环境与正则库版本
import sys
import re
print('python 版本:',sys.version.split('|')[0]) #python 版本: 3.11.4
print('re 正则库版本:',re.__version__) #re 正则库版本: 2.2.1
正则模块中的函数/方法
- re.compile 将正则表达式模式编译为一个正则表达式对象,方便多次使用
import re
text='Does this text match the pattern?'
regexes=re.compile('this')
print(regexes) #re.compile('this')
print(regexes.search(text)) #<re.Match object; span=(5, 9), match='this'>
- re.search
在给定的字符串中 查找/匹配 正则表达式模式,首次出现的位置,如果能匹配到,则返回相应的正则表达式对象;如果匹配不到,则返回
None
import re
pattern='this'
text='Does this text match the text pattern?'
match=re.search(pattern,text)
print(match) #<re.Match object; span=(5, 9), match='this'>
print(match.re) #re.compile('this')
print(match.re.pattern) #this
print(match.string) #Does this text match the text pattern?
print(match.start()) #5
print(match.end()) #9
- re.match
在给定的字符串开头进行匹配,如果在开头能与给定的正则表达式模式匹配,则返回相应的正则表达式对象;如果匹配不到,则返回
None
import re
text='Does this text match the text pattern?'
match1=re.match('Does',text)
print(match1) #<re.Match object; span=(0, 4), match='Does'>
print(match1.span()) #(0, 4)
match2=re.match('this',text)
print(match2) #None
- re.fullmatch
如果整个字符串需要与给定的正则表达式模式匹配,则返回相应的相应的正则表达式对象;如果匹配不到,则返回
None
import re
text='Does this text match the text pattern?'
match1=re.fullmatch('Does this text match the text pattern\?',text)
print(match1) #<re.Match object; span=(0, 38), match='Does this text match the text pattern?'>
match2=re.fullmatch('Does this text',text)
print(match2) #None
match3=re.fullmatch('Does .* pattern\?',text)
print(match3) #<re.Match object; span=(0, 38), match='Does this text match the text pattern?'>
- re.findall 对字符串与给定的正则表达式模式,从左至右进行查找,匹配结果按照找到的顺序进行返回,返回结果是以字符串列表或字符串元组列表的形式,如果匹配不到,返回空列表的形式
import re
text='Does this text match the text pattern?'
matches1=re.findall('text',text)
print(matches1) #['text', 'text']
matches2=re.findall('regexes',text)
print(matches2) #[]
- re.finditer
与
findall方法类似,结果返回的是一个迭代器,并且每个元素是匹配到的正则表达式对象
import re
text='Does this text match the text pattern?'
matches1=re.finditer('text',text)
print(matches1) #<callable_iterator object at 0x0000024D0E9018D0>
for match in matches1:
print(match)
#<re.Match object; span=(10, 14), match='text'>
#<re.Match object; span=(25, 29), match='text'>
matches2=re.findall('regexes',text)
print(matches2) #[]
本篇文章只介绍了几个常用的方法,重点是方法的含义,而没有介绍元字符相关的内容,如果对正则表达式感兴趣,可以深入学习拓展知识范围
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
介绍
bisect模块提供了一种只针对 已排序的序列 的方法,快速找到插入元素的位置,这个模块使用二分查找算法,算法的时间复杂度相对更低一些,可以用于程序优化提升性能
官方文档:https://docs.python.org/3/library/bisect.html#module-bisect
函数分为 bisect、insort 两大块
各函数详解
- bisect、bisect_right
这两个函数功能一模一样,
bisect是对bisect_right的引用,用于查找元素在已经排序的序列中应该插入的位置,返回值为最靠右 or 最大的索引位置
l = [1, 23, 45, 12, 23, 42, 54, 123, 14, 52, 3]
l.sort()
print(l) #[1, 3, 12, 14, 23, 23, 42, 45, 52, 54, 123]
print(bisect.bisect(l, 3)) #2
- bisect_left 返回值为最靠左 or 最小的索引
l = [1, 23, 45, 12, 23, 42, 54, 123, 14, 52, 3]
l.sort()
print(l) #[1, 3, 12, 14, 23, 23, 42, 45, 52, 54, 123]
print(bisect.bisect_left(l, 3)) #1
- insort、insort_right
这两个函数功能一模一样,
insort是对insort_right的引用,用于将一个元素插入到已经排序的序列中,并且保持序列的排序状态,插入位置为最靠右 or 最大的索引位置
l = [1, 23, 45, 12, 23, 42, 54, 123, 14, 52, 3]
l.sort()
print(l) #[1, 3, 12, 14, 23, 23, 42, 45, 52, 54, 123]
bisect.insort(l, 3.0)
print(l) #[1, 3, 3.0, 12, 14, 23, 23, 42, 45, 52, 54, 123]
- insort_left 插入位置为最靠左 or 最小的索引位置
li = [1, 23, 45, 12, 23, 42, 54, 123, 14, 52, 3]
li.sort()
print(li) #[1, 3, 12, 14, 23, 23, 42, 45, 52, 54, 123]
bisect.insort_left(li, 3.0)
print(li) #[1, 3.0, 3, 12, 14, 23, 23, 42, 45, 52, 54, 123]
官方文档案例
def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
i = bisect.bisect(breakpoints, score)
return grades[i]
[grade(score) for score in [33, 99, 77, 70, 89, 90, 100]]
#['F', 'A', 'C', 'C', 'B', 'A', 'A']
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近在看《Python - 100天从新手到大师》时,运行了一下代码,感觉挺有意思。一个简单的小游戏,包含了pyhon的很多知识,分享出来,供大家参考学习
小编对扑克牌的排序进行了简单修改,使相同大小的牌放在一起
《Python - 100天从新手到大师》,感兴趣的同学可以去学习该教程
地址:https://github.com/jackfrued/Python-100-Days
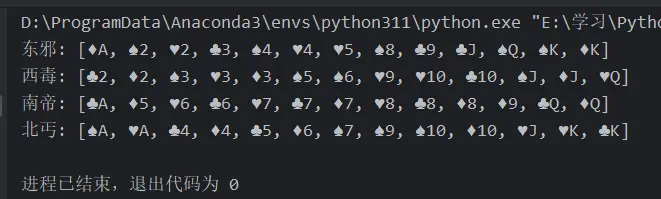
发牌结果
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.4
完整代码
"""
===========================
@Software: PyCharm
@Platform: Win10
@Author : DataShare
===========================
"""
from enum import Enum, unique
import random
@unique
class Suite(Enum):
"""花色"""
SPADE, HEART, CLUB, DIAMOND = range(4)
def __lt__(self, other):
return self.value < other.value
class Card:
"""牌"""
def __init__(self, suite, face):
"""初始化方法"""
self.suite = suite
self.face = face
def show(self):
"""显示牌面"""
suites = ['♠︎', '♥︎', '♣︎', '♦︎']
faces = ['', 'A', '2', '3', '4', '5', '6',
'7', '8', '9', '10', 'J', 'Q', 'K']
return f'{suites[self.suite.value]}{faces[self.face]}'
def __repr__(self):
return self.show()
class Poker:
"""扑克"""
def __init__(self):
self.index = 0
self.cards = [Card(suite, face)
for suite in Suite
for face in range(1, 14)]
def shuffle(self):
"""洗牌(随机乱序)"""
random.shuffle(self.cards)
self.index = 0
def deal(self):
"""发牌"""
card = self.cards[self.index]
self.index += 1
return card
@property
def has_more(self):
return self.index < len(self.cards)
class Player:
"""玩家"""
def __init__(self, name):
self.name = name
self.cards = []
def get_one(self, card):
"""摸一张牌"""
self.cards.append(card)
def sort(self, comp=lambda card: (card.face, card.suite)):
"""整理手上的牌"""
self.cards.sort(key=comp)
def main():
"""主函数"""
poker = Poker()
poker.shuffle()
players = [Player('东邪'), Player('西毒'),
Player('南帝'), Player('北丐')]
while poker.has_more:
for player in players:
player.get_one(poker.deal())
for player in players:
player.sort()
print(player.name, end=': ')
print(player.cards)
if __name__ == '__main__':
main()
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
简介
gihub地址: https://github.com/DQinYuan/chinese_province_city_area_mapper
cpca---chinese province city area,一个用于提取简体中文字符串中省,市和区并能够进行映射,检验和简单绘图的python模块
["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区"]
↓
省 市 区 地址 上海市 上海市 徐汇区 虹漕路461号58号楼5楼 福建省 泉州市 洛江区 万安塘西工业区 “地址”列:代表去除了省市区之后的具体地址
安装介绍
该库目前仅支持Python3,在命令行直接进行安装即可:
pip install cpca
windows 中需要C/C++编译环境的支持,需要下载另外的软件,然后再进行安装 http://go.microsoft.com/fwlink/?LinkId=691126
编译环境的安装教程: https://o7planning.org/11467/install-microsoft-visual-cpp-build-tools
基本使用方法
常规用法
会自动补全相应的省、市、区
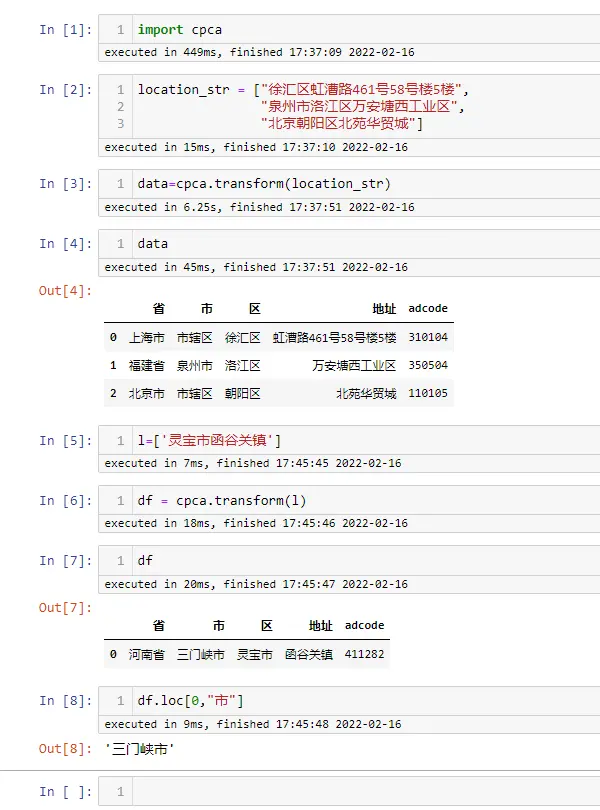
import cpca
location_str = ["徐汇区虹漕路461号58号楼5楼",
"泉州市洛江区万安塘西工业区",
"北京朝阳区北苑华贸城"]
data=cpca.transform(location_str)
data
l=['灵宝市函谷关镇']
df = cpca.transform(l)
df
df.loc[0,"市"]
重名情况
中国的区级行政单位非常的多,经常有重名的情况,比如“北京市朝阳区”和“吉林省长春市朝阳区”,当有上级地址信息的时候,cpca 能够根据上级地址 推断出这是哪个区,但是如果没有上级地址信息,单纯只有一个区名的时候, cpca 就没法推断了,只能随便选一个了, 通过 umap 参数你可以指定这种情况下该选择哪一个
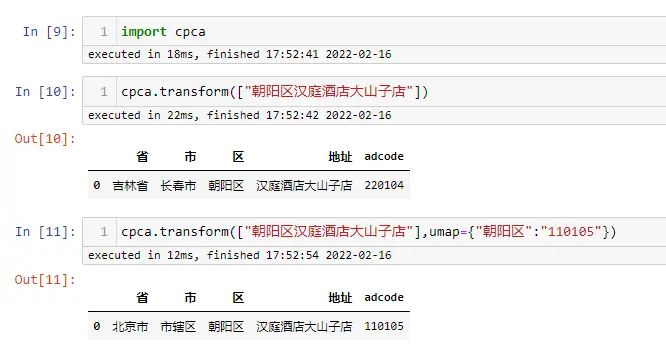
从例子可以看出,umap 字典的 key 是区名,value 是区的 adcode,这里 110105 就是北京市朝阳区的 adcode,具体的 adcode 可以去全国行政区划查询平台上查询
全国行政区划查询平台: http://xzqh.mca.gov.cn/map
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
随着Python版本的更新,背后的一些数据结构会进行不断优化迭代,重新进行架构设计,以实现内存减少、性能提升。其中字典的底层数据结构在Python3.6版本时,重新进行了设计,从而优化了字典的内存占用
具体的底层细节这里不做过多介绍,感兴趣的同学可以看一下这篇文章: 《为什么Python 3.6以后字典有序并且效率更高?》 地址:https://zhuanlan.zhihu.com/p/73426505
该文章的评论精彩评论: 一句话解释:从Python3.6开始,dict的实现由 哈希表 改成 链式哈希表
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.4
测试代码
#创建测试数据
keys=[chr(i) for i in range(97,123)]
values=range(1,27)
#生成字典
dic={}
for key,value in zip(keys,values):
dic[key]=value
#打印字典
print(dic)
#{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6,
#'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12,
# 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17,
#'r': 18,'s': 19, 't': 20, 'u': 21, 'v': 22,
# 'w': 23, 'x': 24, 'y': 25, 'z': 26}
#遍历字典
for key,value in dic.items():
print(key,':',value,end=',')
#a : 1,b : 2,d : 4,e : 5,f : 6,g : 7,h : 8,j : 10,
#k : 11,l : 12,n : 14,o : 15,p : 16,q : 17,r : 18,
#s : 19,t : 20,u : 21,v : 22,w : 23,x : 24,z : 26,
#删除测试
del dic['c']
del dic['y']
del dic['i']
del dic['m']
print(dic)
#{'a': 1, 'b': 2, 'd': 4, 'e': 5, 'f': 6, 'g': 7,
#'h': 8, 'j': 10, 'k': 11, 'l': 12, 'n': 14, 'o': 15,
#'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20,
#'u': 21, 'v': 22, 'w': 23, 'x': 24, 'z': 26}
结论
经过添加、删除操作可以看出,字典是按添加键值对时的先后顺序保存数据,是有序的
历史相关文章
- Python 标准库之pathlib,路径操作
- Python 记录re正则模块,方便后期查找使用
- Python 内建模块 bisect,数组二分查找算法
- Python 标准库heapq,堆数据结构操作详解
- Python math模块详解
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
概述
math模块是内置模块,提供了许多对浮点数的数学运算函数,提供类似C语言标准定义的数学函数(This module provides access to the mathematical functions defined by the C standard)
包含以下 七部分 函数:
- 算术函数(Number-theoretic and representation functions)
- 幂函数与对数函数(Power and logarithmic functions)
- 三角函数(Trigonometric functions)
- 角度转换函数(Angular conversion)
- 双曲函数(Hyperbolic functions)
- 特殊函数(Special functions)
- 常量(Constants)
math模块常用函数
虽然math模块提供的函数很多,但是现阶段工作中使用的很少,下面就列出一些实际工作中常用的函数:
注意:虽然math是内置模块,但使用前需要先import导入该库
import math
- math.ceil(x)----------向上取整
>>> math.ceil(2.1)
3
>>> math.ceil(3.7)
4
>>> math.ceil(-1.5)
-1
>>> math.ceil(-3.1)
-3
- math.floor(x)----------向下取整
>>> math.floor(1.2)
1
>>> math.floor(4.8)
4
>>> math.floor(-0.1)
-1
>>> math.floor(-2.8)
-3
- math.exp(x)----------e的x次方,其中 e = 2.718281… 是自然对数的基数
>>> math.exp(1)
2.718281828459045
>>> math.exp(2)
7.38905609893065
>>> math.exp(0)
1.0
- math.log(x,base=e)---------- 默认返回x 的自然对数,默认底为 e,如果指定底,返回指定底的对数
>>> math.log(math.exp(1))
1.0
>>> math.log(math.exp(0))
0.0
>>> math.log(math.exp(2))
2.0
>>> math.log(4,base=2)
2.0
>>> math.log(9,base=3)
2.0
>>> math.log(100,base=10)
2.0
- math.pow(x, y)---------- x 的 y 次幂
>>> math.pow(2,3)
8.0
>>> math.pow(4,2)
16.0
>>> math.pow(-5,2)
25.0
- math.sqrt(x)---------- x 的算术平方根,也就是正数的平方根
>>> math.sqrt(25)
5.0
>>> math.sqrt(4)
2.0
>>> math.sqrt(10)
3.1622776601683795
- math.pi---------- 常量π,15位小数
>>> math.pi
3.141592653589793
- math.e---------- 常量e,15位小数
>>> math.e
2.718281828459045
- math.sin(x)---------- x弧度的正弦值
>>> math.sin(math.pi/2)
1.0
>>> math.sin(math.pi/3)
0.8660254037844386
>>> math.sin(math.pi/6) #近似0.5
0.49999999999999994
>>> math.sin(math.pi/4)
0.7071067811865476
- math.cos(x)---------- x弧度的余弦值
>>> math.cos(0)
1.0
>>> math.cos(math.pi/3) #近似0.5
0.5000000000000001
>>> math.cos(math.pi/4)
0.7071067811865476
- math.degrees(x)----------将角度 x 从弧度转换为度数
>>> math.degrees(math.pi)
180.0
>>> math.degrees(math.pi/2)
90.0
>>> math.degrees(math.pi/6) #近似30
29.999999999999996
- math.radians(x)----------将角度 x 从度数转换为弧度
>>> math.radians(90)
1.5707963267948966
>>> math.radians(180)
3.141592653589793
>>> math.radians(360)
6.283185307179586
度数、弧度概念可参考历史相关文章,有详细说明
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号,不定期分享干货
作者:数据人阿多
介绍
偏函数(functools.partial),主要用来解决函数中某些参数是已知的固定值。利用偏函数的概念,可以生成一些新的函数,在调用这些新函数时,不用再传递固定值的参数,这样可以使代码更简洁
下面列举一些偏函数的巧妙使用方法,在使用偏函数时,需要从标准库functools中导入
from functools import partial
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.4
生成不同的聚合函数
1. 创建底层的元函数、函数类
from functools import partial
def aggregation_fn_meta(aggregation_fn, values):
return aggregation_fn(values)
def aggregation_fn_class(aggregation_fn):
return partial(aggregation_fn_meta, aggregation_fn)
2. 基于函数类,来生成不同的聚合函数
- 基于内建函数创建(python中可以直接使用的函数)
sum_fn=aggregation_fn_class(sum)
sum_fn([1,2,3,4,5,1,2,10]) #28
max_fn=aggregation_fn_class(max)
max_fn([1,2,3,4,5,1,2,10]) #10
min_fn=aggregation_fn_class(min)
min_fn([1,2,3,4,5,1,2,10])
- 基于自定义函数创建
def count(values):
return len(values)
count_fn=aggregation_fn_class(count)
count_fn([1,2,3,4,5,1,2,10]) #8
def distinct_count(values):
return len(set(values))
distinct_count_fn=aggregation_fn_class(distinct_count)
distinct_count_fn([1,2,3,4,5,1,2,10]) #6
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
前言
无论是在自己Windows、MacOS电脑,还是在Linux服务器,在操作文件时,多多少少都会涉及到文件的管理。
Python里面有个自带的 os 模块,专门是用来对文件、路径等进行管理的工具,下面列出一些自己在工作中常用的函数、方法,供大家参考学习。
路径的正确表示,三种都可以
- 由于
\是转义的意思,所以路径都用\\表示,例如:'C:\\Users\\abc\\Desktop' - 如果想用单个
\,可以在前面加个r,例如:r'C:\Users\abc\Desktop' - 也可以用
/来表示,例如:'C:/Users/abc/Desktop'
点点们的介绍
./ 当前你所编辑的这个脚本所在目录
../ 当前你所编辑的这个脚本所在目录的上一级目录
os 模块常用函数、方法
- 无需pip安装,可以直接导入
import os
- 获取当前工作路径 也就是你编写的这个脚本所在的文件夹位置
os.getcwd() #C:\\Users\\abc\\Desktop\\Python\\python库
- 获取绝对路径
path='./111.xlsx'
os.path.abspath(path) #C:\\Users\\abc\\Desktop\\Python\\python库\\111.xlsx
- 获取文件的完整路径里面的文件名字
a='C:\\Users\\abc\\Desktop\\Python\\python库\\111.xlsx'
os.path.basename(a) #111.xlsx
- 获取文件的完整路径里面的路径
a='C:\\Users\\abc\\Desktop\\Python\\python库\\111.xlsx'
os.path.dirname(a) #C:\\Users\\abc\\Desktop\\Python\\python库
- 判断是否存在相应的文件或文件夹
a='./111.xlsx'
b='C:\\Users\\abc\\Desktop\\Python\\python库\\111'
os.path.exists(a) #True
os.path.exists(b) #False
- 分隔文件的完整路径为:路径、文件名字
相对上面的方法,这样可以一次都获取到,但是也有缺点,os.path.split只识别
/,不识别\\,因此在用该方法时,需要先进行替换
a='C:\\Users\\abc\\Desktop\\Python\\python库\\111.xlsx'
b,c=os.path.split(a.replace('\\','/'))
#b C:/Users/abc/Desktop/Python/python库
#c 111.xlsx
- 删除存在的文件
a='./111.xlsx'
os.remove(a) #无返回值,直接删除该文件
- 创建文件夹 建议用makedirs方法,这样即可以直接创建单级文件夹,有可以创建多层级文件夹
os.makedirs('./a')
os.makedirs('./1/2')
以上这些方法是在工作中经常使用的,如有新的路径的需求可以在其他一些网站进行查找
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
有时写的Python程序需要交给业务人员使用,但业务人员电脑上基本都没有安装Python,并且业务人员也不会使用命令行,所以就需要把Python程序打包成exe可执行程序,让业务人员无需安装Python,可以直接使用。
这里只针对Windows操作系统的打包,以及只针对业务人员使用场景。(Linux系统基本都是技术开发人员在使用,基本都用的是命令行;而Mac系统不知是否有相关的打包库,可以打包为dmg)
打包过程(以下均为在cmd命令行执行)
- 首先安装第三方库:
pyinstaller
pip install pyinstaller
- 打包
需要先切换到打包程序目录,cd c:\xxx\xxx然后对Python程序进行打包
pyinstaller -F xxx.py
- 结果
如果打包成功,当前目录下会增加一个新的dist文件夹,打开该文件夹,会发现打包好的exe文件:xxx.exe,文件名与Python程序文件相同 - 其他
打包大概流程如上所示,除此之外pyinstaller支持其他一些功能,比如打包时指定自定义图标,首先需要下载一张正常的ico,不能用直接修改后缀的,然后进行打包,一定是先图标文件路径,再是程序路径,如下所示:
pyinstaller -F -i xxx.ico xxx.py
注意事项!!!
- 运行报错
虽然经过一番折腾,终于打包好exe可执行程序,但是双击运行时总是报错,无法成功运行,这种情况大多数是因为缺少第三方库造成的。
解决方法:
在打包之前先在cmd运行一次Python程序看是否成功运行
python xxx.py
- 如果能成功运行,那么打包后基本没什么问题
- 如果运行失败,那么查看报错信息,是否缺少第三方库,然后进行
pip安装,确保能成功运行
- 文件太大
以上打包过程是不是很简单,但是有没有注意打包的exe文件有时会很大,有时几百兆大小,但是自己的Python程序也就几KB,这个问题也是自己之前遇到的难题(使用的是Anaconda),即使另外建立了新的环境也不行(conda create -n 环境名)
解决方法:
一定要使用Python官网下载的原生Python程序,并且确保系统环境变量里面只有这一个Python路径,只有这一个Python路径,只有这一个Python路径!!!
亲测自己的打包程序从200M降到50M大小
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号DataShare,不定期分享干货
作者:数据人阿多
背景
最近小编利用业余时间充电,细读了《Python 编程从新手到高手》这本书的部分章节,作者:【美】贾森·C. 麦克唐纳,其中确实藏了不少干货!一些之前未曾涉猎的知识点,这次也被一一解锁。整理出来部分内容,分享给大家一起学习交流,共同进步呀~ 📚✨
该书中文版的翻译还是差点意思,读起来不是很通顺
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
Python中的变量:名称和值
原文中关于 变量 的描述:Python 用name(名称)和 value(值)来代替variable(变量)
- 一个name指向一个value或object(对象),就像你的名字指向你一样。可能有多个name指向同一个value,就像你可能有一个名字和一个昵称
- 一个value是内存中一个特定的数据实例
- “变量”这个术语指代这两者的组合:一个name指向一个value
- 名称有作用域,它们随着函数的出现而出现,随着函数的消失而消失,但是它们没有类型
- 值有类型,但是没有作用域
- 名称被绑定到值,而这些值存在于内存中,且有一些引用指向它们。你可以把一个名称绑定到任何你想要的值上,但是你只能对特定的值执行一些有限的操作
作者强调:虽然Python是一种动态类型的语言,但是Python仍然是一种强类型的语言。名称可以随意绑定到不同类型的值上面,但是任何值都是有类型的
类属性与类方法
- 类属性属于类本身,而不属于某个实例。实际上,这意味着所有相关的类实例“共享”类属性。即使没有任何实例,类属性也依然存在
- 类方法属于类,而不属于类的某个实例
@classmethod
def inform(cls, codeword):
cls._codeword = codeword
以上代码在类方法上使用了@classmethod装饰器。类方法将类作为其第一个参数接收,因此第一个参数被命名为cls。该inform()类方法既可以直接在SecretAgent类上调用,也可以在任何SecretAgent实例(如fox)上调用。inform()对类属性_codeword所做的更改会出现在类本身及其所有实例上
流
要想处理任何数据文件,你需要获得一个流(又称文件对象或类文件对象),其提供读取和写入内存中的特定文件的方法。一般存在两种流:
- 二进制流是所有流的基础,用来处理二进制数据(0和1)
- 文本流则处理二进制文本的编码和解码
print 刷新
- 指定参数:
print('.', end='', flush=True),大家一般使用的方法 - 全局的方法:如果需要所有的print()调用默认每次都刷新,可以在非缓冲模式下运行Python,只需要在调用程序时将-u选项传递给Python解释器即可,如
python3 -u test.py
并发与并行
- 并发(concurrency)是编程中的多任务处理:在多个任务之间快速分配程序的注意力
- 并行(parallelism),并行是指多个任务同时发生
- 有两种方法可以在Python中实现并发:线程、异步
重点是记住这2个英文单词,比如在hive sql中,任务在集群中运行,可以启动并行,set hive.exec.parallel=true;,中文翻译有时会忽略两者差异
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
你是否听说过 Python 中的 单实例模式(Singleton Pattern)? ,小编之前在阅读别人代码的时候曾经遇到过,一直不知道那段代码什么含义,后来在搜索资料时,才知道那段代码的含义是创建单实例,也正是从那之后,才知道这个名词 “单实例”,是 Python 中的一种设计模式,用大白话说就是类的实例对象在内存中只有一个
单实例模式代码
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
return cls._instance
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
借助大模型进行详细解释
首次创建实例对象时,类的属性 _instance = None,然后程序会进入 if 条件进行执行,重点语句:
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
# cls._instance = super().__new__(cls, *args, **kwargs)
1. super(Singleton, cls) 的作用
- super函数:用于获取父类(基类)的方法,继承父类,进行父类初始化的用法
- 参数含义:
Singleton:当前类cls:当前类的引用(在类方法中,cls代表类本身)
这种写法明确指定了从Singleton类开始,在MRO(Method Resolution Order)中查找父类。在Python 3中可以简化为super(),但这种写法更清晰地展示了继承关系
2. .__new__(cls, *args, **kwargs)
- 调用父类的
__new__方法:这是实际创建对象实例的关键步骤
super(Singleton, cls).__new__(cls) → 实际调用object.__new__(Singleton)
在 CPython(Python 的官方实现)中,object.__new__ 是用 C 语言实现的底层函数。它的核心工作是:
- 内存分配:为新对象分配适当的内存空间
- 对象初始化:设置对象的基本结构
- 返回原始对象:返回一个"空"的、未初始化的对象实例
object.__new__ 是底层实现,它不会触发 Python 层面的 __new__ 方法调用
当 object.__new__ 执行时:
- 它直接操作内存分配,不经过 Python 的方法查找机制
- 它是解释器内置的 C 函数,不是 Python 函数
- 它的工作就是创建原始对象,不会检查或调用任何
__new__方法
object.__new__(Singleton) 的工作原理:
- 内存分配:为 Singleton 实例分配适当大小的内存
- 对象初始化:设置基本对象头(类型指针、引用计数等)
- 返回原始对象:返回一个"空"的、未初始化的对象实例
3. 返回赋值 cls._instance=
经过第2步之后,会将原始对象赋值给 cls._instance,其实是类在内存中的地址/指针,这样类的属性不再为None,后续如果再次创建实例时,直接返回第一次创建好的实例对象
单例模式的核心优点
- 节省内存资源:在内存中只有一个对象,避免了重复创建实例带来的内存浪费
- 减少系统开销:单例可长驻内存,避免频繁的创建和销毁对象,减少系统开销
- 全局访问点:提供一个全局访问点,允许在应用程序中轻松访问该唯一实例
- 数据同步控制:全局只有一个接入点,可以更好地进行数据同步控制,避免多重占用
单例模式的实际应用场景
- 日志记录器:应用程序通常只需要一个日志记录器实例,避免多个日志文件冲突
- 数据库连接池:数据库连接是稀缺资源,使用单例模式可以统一管理连接,避免资源浪费
- 配置管理:应用程序的全局配置通常只需要一个实例,保证配置的一致性,比如大模型在内存/GPU中只初始化一次,来处理所有的用户请求
- 缓存系统:全局缓存需要统一管理,避免多个缓存实例导致数据不一致
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在Python编程中,函数参数的设计直接影响代码的健壮性和可预测性。**一个需要警惕的实践是:避免将可变对象(尤其是列表)作为函数参数的默认值。**这样做可能导致极其隐蔽且令人困惑的bug
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
现象:一个诡异的“记忆”功能
想象你设计了一个函数,用来记录新添加的学生姓名到某个班级列表。如果列表为空,则创建一个新列表:
def add_student(name, student_list=[]):
student_list.append(name)
return student_list
# 第一次调用:添加Alice
class1 = add_student("Alice")
print(class1) # 输出: ['Alice']
# 第二次调用:添加Bob
class2 = add_student("Bob")
print(class2) # 输出: ['Alice', 'Bob']
问题来了: 第二次调用add_student("Bob")时,并没有传递student_list参数,期望的是生成一个只包含**"Bob"的新列表。但结果却包含了第一次添加的"Alice"**!这个函数似乎“记住了”之前的调用
原因揭秘:列表是引用类型
要理解这个问题的本质,必须明白Python中变量的工作方式:
-
列表是引用类型 在Python中,变量存储的是对象的引用(内存地址),而不是对象本身。当你将一个列表赋值给变量时,实际上是在创建一个指向列表对象的引用。
-
默认参数的创建时机 当Python解释器遇到函数定义时,它会立即创建默认参数对象。对于列表这样的可变对象,这意味着只有一个列表对象被创建,并且这个对象会持续存在于整个程序的生命周期中。
-
函数调用时的陷阱 当你多次调用函数而不提供参数时,Python不会创建新的列表,而是重复使用同一个默认列表对象。因为列表是可变的,每次对它的修改都会永久改变这个共享对象。
-
引用传递的后果 由于函数操作的是指向同一个列表对象的引用,所有使用默认参数的调用实际上都在操作同一个物理列表。这就是为什么数据会"神奇地"在函数调用之间保留下来
解决方案:使用不可变默认参数
正确的做法是使用 None 作为哨兵值
def add_item(item, items=None):
if items is None:
items = [] # 每次调用都创建新列表
items.append(item)
return items
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
Python以其灵活性著称,这种特性在函数参数设计中尤为明显。本文将依据语言规范,系统阐述Python函数所支持的全部参数类型及其应用
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
完整函数参数示例1
def func(pos_only=None, /, pos_kw=None, *, kw_only=None):
- 仅位置参数 (Positional-only) :
/前面的参数 标识:使用/符号分隔 特点:只能通过位置传递,不能使用参数名
def func(a, b, /, c):
# a, b 是仅位置参数
pass
# 正确调用
func(1, 2, 3) # a=1, b=2, c=3
func(1, 2, c=3) # a=1, b=2, c=3
# 错误调用
func(a=1, b=2, c=3) # TypeError: 不能使用关键字传递a, b
- 位置或关键字参数 (Positional-or-keyword):
/和*之间的参数 位置:在/之后,*之前(如果没有/或*,则在所有参数中) 特点:既可以通过位置传递,也可以通过关键字传递
def func(a, b, c):
# 传统写法,所有参数都是位置或关键字参数
pass
# 两种方式都可以
func(1, 2, 3) # 位置传递
func(a=1, b=2, c=3) # 关键字传递
func(1, b=2, c=3) # 混合传递
- 仅关键字参数 (Keyword-only):
*后面的参数 标识:使用*符号分隔,或者单个*特点:必须使用关键字传递
def func(*, a, b):
# a, b 是仅关键字参数
pass
# 正确调用
func(a=1, b=2)
# 错误调用
func(1, 2) # TypeError: 必须使用关键字参数
完整函数参数示例2
def comprehensive(
pos_only_1, # 仅位置参数
pos_only_2=10, # 带默认值的仅位置参数
/, # 分隔符
pos_kw_1, # 位置或关键字参数
pos_kw_2=20, # 带默认值的位置或关键字参数
*args, # 可变位置参数
kw_only_1, # 仅关键字参数
kw_only_2=30, # 带默认值的仅关键字参数
**kwargs # 可变关键字参数
):
pass
# 调用示例
comprehensive(
1, # pos_only_1
2, # pos_only_2
3, # pos_kw_1
pos_kw_2=4, # pos_kw_2
5, 6, # 进入args
kw_only_1=7, # kw_only_1
kw_only_2=8, # kw_only_2
extra1=9, # 进入kwargs
extra2=10 # 进入kwargs
)
- 可变位置参数:
*args
def func(a, *args, b=10):
# args收集所有额外的位置参数
pass
func(1, 2, 3, 4) # a=1, args=(2,3,4), b=10
- 可变关键字参数:
**kwargs
def func(a, **kwargs):
# kwargs收集所有额外的关键字参数
pass
func(1, x=2, y=3) # a=1, kwargs={'x':2, 'y':3}
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
近2年随着Rust语言的大力发展,一些系统与软件开始逐渐使用Rust语言来实现,并且一些大型公司也开始逐渐转向Rust
因为在学习 Polars 库时,看到该库是使用Rust实现的,小编近一年也逐渐开始学习Rust语言,了解到其中的一些思想相对其他语言来说确实比较先进,所有权概念的引入,不仅可以提升性能,而且还保证了数据安全、准确,不会有数据竞争问题的产生
小编最近在处理加解密任务时,借助Rust语言实现了一个DES加解密库,借助Rust 中的 pyo3 包,在Python 中借助 maturin 库,可以把 Rust 实现的库转换为 Python 的包,供Python调用
DES加解密,Rust实现
#![allow(unused)] fn main() { use pyo3::prelude::*; use openssl::provider::Provider; use openssl::symm::{Cipher,encrypt,decrypt}; use hex; const KEY:&[u8; 8]=b"ABCD1234"; const IV:&[u8; 8]=b"ABCD1234"; #[pyfunction] fn des_encrypt(data:String)-> String { let _provider = Provider::try_load(None, "legacy", true).unwrap(); let cipher: Cipher = Cipher::des_cbc(); let ciphertext = encrypt(cipher, KEY, Some(IV), data.as_bytes()); hex::encode(&ciphertext.unwrap()).to_uppercase() } #[pyfunction] fn des_decrypt(data:String)-> String { let _provider = Provider::try_load(None, "legacy", true).unwrap(); let cipher: Cipher = Cipher::des_cbc(); match hex::decode(&data) { Ok(bytes) => { // println!("Decoded: {:?}", bytes); // 输出: [104, 101, 108, 108, 111] // println!("{:?}", des_decrypt(&bytes)); match decrypt(cipher, KEY, Some(IV), &bytes) { Ok(bytes) => { // println!("Decoded: {:#?}", bytes); // 输出: [104, 101, 108, 108, 111] match String::from_utf8(bytes) { Ok(string) => string, // 输出: "hello" Err(_) => "".to_string(), } }, Err(_) => "".to_string(), } }, Err(_) => "".to_string(), } } #[pymodule] fn des_rust(_py: Python, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(des_encrypt, m)?)?; m.add_function(wrap_pyfunction!(des_decrypt, m)?)?; Ok(()) } }
然后利用 Maturin 进行打包,可以生成 Python 的库/包/轮子,小编这里生成的是 des_rust-0.1.0-cp37-abi3-win_amd64.whl
然后安装该包后,即可在Python中进行使用
Python 使用
from des_rust import des_decrypt,des_encrypt
data=des_decrypt(des_encrypt('DataShare'))
print(data) #DataShare
通过性能测试,效率相对使用Python实现的包,性能有大幅提升
进一步思考
通过以上的案例,小编走通了从Python中调用Rust代码的流程,结合小编学习 Rust 的思考,那么Rust + Python 结合,是否会成为将来数据分析、机器学习领域的趋势?
-
Python 比较灵活,拿来即用,学习起来也容易,现在普及程度也很广,最重要的是能很快出成果,处在现阶段的社会,出成果很重要,有的老板恨不得第1天晚上想出了一个idea,第2天就想要成果,当然这个也不能怨老板,只能说现阶段竞争很激烈
-
Rust 内存安全、性能高,可以弥补Python 的不足,截止当前已经有很多Python 库是使用Rust 实现的,随着老板的想发愈发复杂,想提升数据处理性能,只能使用底层的语言实现,但也不能另起炉灶,否则前期的工作相当于白做,而且业务也需要快速迭代
Rust + Python 结合是否会成为将来数据领域的趋势呢?让我们拭目以待
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
Python 3.14 自2025年10月7日发布以来,已在技术社区中积累了丰富的实践与评测资料。目前国内的相关文章大多译自国外大神的博客文章,内容都很“高大上”,但在普遍适用性方面尚缺乏贴近实际的基础案例。为此,本文旨在提供一个通用的实践示例,作为后续深入研究和学习的baseline
名词解释
自由线程、无GIL与英文术语 Free-threaded 同义,均指代同一项核心语言特性,即代码在执行时不再受全局解释器锁(GIL)的约束
小编环境
#Win10 系统 安装uv
pip install uv
uv -V
#uv 0.9.0 (39b688653 2025-10-07)
python -VV
#Python 3.14.0 free-threading build (main, Oct 7 2025, 15:34:02) [MSC v.1944 64 bit (AMD64)]
测试结果图

安装python3.14无GIL解释器
目前,Python官方的标准构建版本仍默认包含全局解释器锁(GIL)。若需使用无GIL的解释器,开发者需从源代码自行构建,或选用由社区提供的预编译版本。值得注意的是,工具 uv 现已提供预编译的无GIL解释器,支持用户直接安装使用。
mkdir 314t && cd 314t #创建目录
uv init #初始化项目
uv python list #查看所有可用的python版本
uv python install cpython-3.14.0+freethreaded-windows-x86_64-none #安装无GIL版本
uv python pin 3.14t #切换项目解释器
测试代码
#test.py
import time
import threading
import queue
N = 3_0000_0000 #模拟任务量
def cpu_bound_task(n, thread_id, q):
count = 0
for i in range(n):
count += i * i
q.put(count)
def run_with_threads(num_threads):
threads = []
start = time.time()
q = queue.Queue()
for i in range(num_threads):
t = threading.Thread(
target=cpu_bound_task,
args=(N // num_threads, i, q) #每个线程计算 1/n
)
threads.append(t)
t.start()
for t in threads:
t.join()
end = time.time()
print(f"Total time taken with {num_threads} threads: {end - start:.2f} seconds")
if __name__ == "__main__":
for num in [1, 2, 4, 8, 16, 32]:
run_with_threads(num)
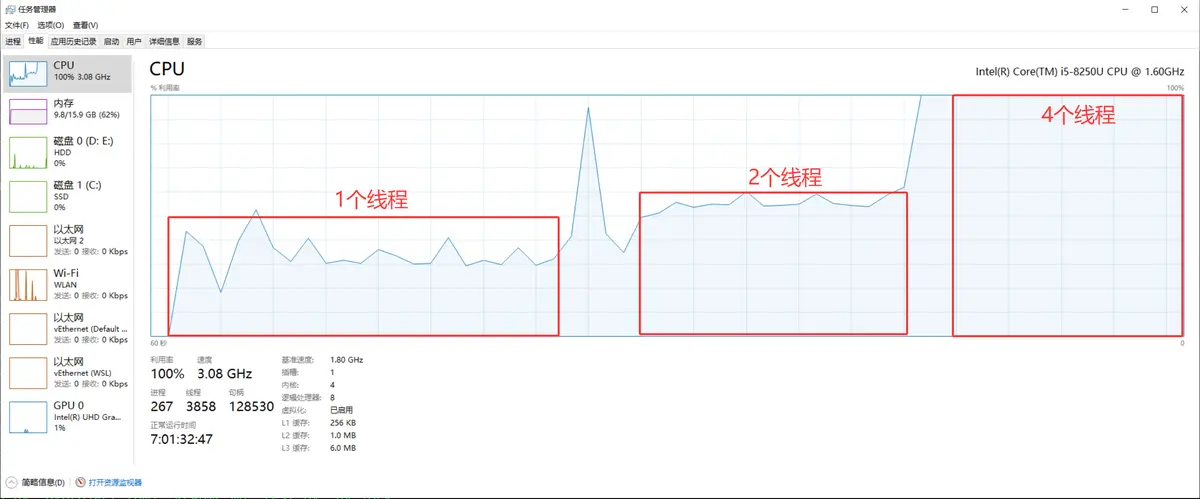
运行测试代码: 小编电脑是物理4核,启动4个线程时,CPU利用率达到100%
uv run test.py
#Total time taken with 1 threads: 27.00 seconds
#Total time taken with 2 threads: 15.08 seconds
#Total time taken with 4 threads: 9.39 seconds
#Total time taken with 8 threads: 8.72 seconds
#Total time taken with 16 threads: 9.74 seconds
#Total time taken with 32 threads: 9.55 seconds
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
装饰器:Python开发者的效率利器! 🛠️
在Python的世界里,装饰器绝对是一把强大的“瑞士军刀”。它能帮我们优雅地封装通用逻辑,大幅减少重复代码,真正实现事半功倍的开发效率。
如果你是第一次接触装饰器这个概念,强烈建议先找些基础资料了解一下它的核心思想和工作原理(别担心,小编当初也是一头雾水,看别人的代码完全摸不着头脑)。打好基础再往下看,理解起来会顺畅得多,相信小编!
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
计算耗时
想知道函数执行耗时?一个装饰器轻松搞定!⏱️
还在手动写 time.time() 包裹你的函数来计算耗时吗?太麻烦啦!只需几行代码定义一个计时装饰器,轻轻松松给任何函数“戴上”,就能自动获取精准的执行时间
def time_it(func):
@wraps(func) # 保留原始函数的元数据
def wrapper(*args, **kwargs):
print("开始执行---->")
start_time=datetime.datetime.now()
result = func(*args, **kwargs)
end_time=datetime.datetime.now()
print(f"结束执行,消耗时长为:{end_time - start_time}")
return result
return wrapper
重试机制
在程序中调用外部API、访问数据库或进行网络请求时,网络环境的不稳定性往往是导致程序“意外扑街”的头号元凶!面对这种不可控因素,与其祈祷网络永远畅通,不如主动出击——引入重试机制,来增加程序的健壮性
def retry(func=None,*,times=3):
if func is None:
return partial(retry,times=times)
@wraps(func)
def wrapper(*args,**kwargs):
for attempt in range(1,times+1):
try:
return func(*args,**kwargs)
except Exception as exc:
print(f"函数 {func.__name__} 进行第 {attempt} 次尝试,遇到错误:{exc}")
sleep(SLEEP_TIME * attempt)
print(f"所有尝试均失败!!!")
return None
return wrapper
完整代码
from time import sleep
import datetime
from functools import wraps,partial # 导入 wraps 装饰器
SLEEP_TIME=1
def time_it(func):
@wraps(func) # 保留原始函数的元数据
def wrapper(*args, **kwargs):
print("开始执行---->")
start_time=datetime.datetime.now()
result = func(*args, **kwargs)
end_time=datetime.datetime.now()
print(f"结束执行,消耗时长为:{end_time - start_time}")
return result
return wrapper
def retry(func=None,*,times=3):
if func is None:
return partial(retry,times=times)
@wraps(func)
def wrapper(*args,**kwargs):
for attempt in range(1,times+1):
try:
return func(*args,**kwargs)
except Exception as exc:
print(f"函数 {func.__name__} 进行第 {attempt} 次尝试,遇到错误:{exc}")
sleep(SLEEP_TIME * attempt)
print(f"所有尝试均失败!!!")
return None
return wrapper
if __name__=='__main__':
@retry
@time_it
def cal(x):
total=0
for i in range(x):
total += i
return total
print(cal(100000000))
print(cal('100000'))
运行测试结果
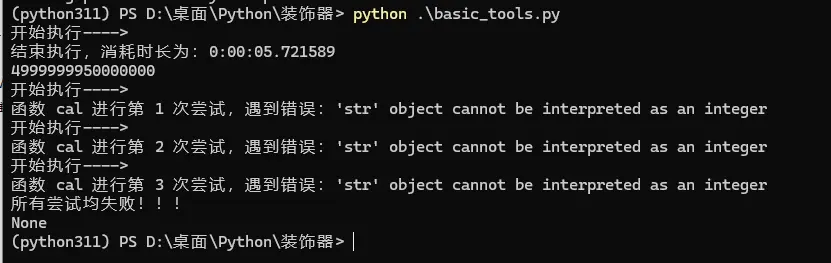
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
虽然 Python 中已提供了 列表、字典 等非常灵活的数据结构,但是**collections** 模块提供了高性能的容器数据类型,能大幅优化代码效率和可读性,本文将深入解析该模块中的六大核心工具,助你写出更优雅的Python代码,避免你重复造轮子
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
namedtuple:命名元组
传统元组通过索引访问元素,代码可读性差:
point = (2, 5)
print(f"X: {point[0]}, Y: {point[1]}") # 可读性低
namedtuple 赋予元组字段名
from collections import namedtuple
# 创建具名元组类型
Point = namedtuple('Point', ['x', 'y'])
p = Point(2, 5)
print(p.x, p.y) # 直观访问
print(p._asdict()) # 转为字典:{'x': 2, 'y': 5}
✅ 适用场景:数据库查询结果、坐标点等轻量级数据结构
deque:高效双端队列
列表(list)在头部插入/删除效率为 O(n),deque 在两端操作均为 O(1)
from collections import deque
d = deque([1, 2, 3])
d.appendleft(0) # 左侧添加 → deque([0, 1, 2, 3])
d.extend([4, 5]) # 右侧扩展 → [0,1,2,3,4,5]
d.rotate(2) # 向右旋转 → [4,5,0,1,2,3]
🔥 性能对比:千万元素头部插入
- list.insert(0, x):耗时2.1秒
- deque.appendleft(x):耗时0.02秒
Counter:元素统计利器
快速统计可迭代对象中元素频率
from collections import Counter
text = "python collections is powerful"
word_count = Counter(text.split())
print(word_count.most_common(2))
# 输出:[('python', 1), ('collections', 1)]
# 数学运算
c1 = Counter(a=3, b=1)
c2 = Counter(a=1, b=2)
print(c1 + c2) # Counter({'a': 4, 'b': 3})
💡 进阶技巧:elements()方法生成迭代器,subtract()实现减法操作
defaultdict:智能字典
避免KeyError异常,自动初始化默认值
from collections import defaultdict
# 值为列表的字典
dd = defaultdict(list)
dd['fruits'].append('apple') # 无需初始化
print(dd['animal']) # 访问不存在的key,返回空列表 []
# 值为计数的字典
count_dict = defaultdict(int)
for char in "abracadabra":
count_dict[char] += 1
支持任意可调用对象:defaultdict(lambda: 'N/A')
ChainMap:字典聚合器
合并多个字典而不创建新对象
from collections import ChainMap
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}
chain = ChainMap(dict1, dict2)
print(chain['b']) # 输出2(dict1优先)
print(chain['c']) # 输出4
# 动态添加字典
chain = chain.new_child({'d': 5})
🌟 特点:查找顺序可定制,原始字典修改实时同步
OrderedDict:有序字典
虽然Python3.7+的dict已有序,但OrderedDict提供额外功能
from collections import OrderedDict
od = OrderedDict()
od['z'] = 1
od['a'] = 2
print(list(od.keys())) # 保持插入顺序:['z', 'a']
# 特殊方法
od.move_to_end('z') # 移动键到末尾 ,OrderedDict([('a', 2), ('z', 1)])
od.popitem(last=False) # FIFO删除,删除 ('a', 2)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
小编之前写过一篇介绍 pathlib 标准库的文章,最近在做项目时,又发现其有一个更好用的功能,分享给大家,供大家参考学习
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
创建目录方法:Path.mkdir()
pathlib.Path.mkdir() 方法是 Python 中创建目录的核心方法,提供了灵活且安全的目录创建功能
方法签名:
Path.mkdir(mode=0o777, parents=False, exist_ok=False)
参数详解:
1. mode (可选)
- 作用: 设置目录权限(Unix/Linux/Mac 系统有效)
- 默认值: 0o777 (八进制,表示最大权限)
- 注意: 在 Windows 上此参数被忽略
常用权限值:
from pathlib import Path
# 创建用户可读/写/执行,组和其他用户只读/执行的目录
Path("my_dir").mkdir(mode=0o755) # drwxr-xr-x
# 创建只有用户可读/写/执行的目录
Path("private_dir").mkdir(mode=0o700) # drwx------
2. parents (可选)
- 作用: 是否自动创建父目录
- 默认值:
False - 当
False时: 父目录必须存在,否则抛出FileNotFoundError - 当
True时: 自动创建所有不存在的父目录
3. exist_ok (可选)
- 作用: 目录已存在时的处理方式
- 默认值:
False - 当
False时: 目录已存在会抛出FileExistsError - 当
True时: 目录已存在不会报错
基础用法示例
示例 1: 创建单级目录
from pathlib import Path
# 在当前目录下创建新文件夹
Path("new_folder").mkdir()
# 创建指定路径的目录
Path("/tmp/example").mkdir()
示例 2: 创建多级目录(使用 parents=True)
from pathlib import Path
# 传统方式 - 需要逐级检查创建
# 这里演示只判断父目录是否存在
path = Path("a/b/c/d/e")
if not path.parent.exists():
path.parent.mkdir()
path.mkdir()
# 简化方式 - 一次性创建所有层级
Path("a/b/c/d/e").mkdir(parents=True)
示例 3: 安全创建目录(使用 exist_ok=True)
from pathlib import Path
# 安全创建 - 目录存在也不报错
Path("my_project").mkdir(exist_ok=True)
# 等同于检查是否存在再创建
path = Path("my_project")
if not path.exists():
path.mkdir()
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
端口扫描技术广泛应用于网络运维、网络安全测试、以及黑客攻击服务器等领域。在网络运维中,管理员通过端口扫描来检查服务器或设备的开放端口,确保网络安全并及时发现潜在的漏洞。在网络安全测试中,端口扫描帮助识别网络中的弱点,进而制定防护措施,提升整体安全性。而在黑客攻击的情境下,攻击者通过端口扫描发现目标设备开放的服务,从而寻找攻击入口点,实施非法入侵。因此,端口扫描不仅是安全防护的一个重要工具,也常被黑客用作攻击手段。
本篇文章的目的是通过构建一个端口扫描工具,深入探讨如何在Python中利用协程进行高效的网络端口扫描。传统的端口扫描通常是串行的,效率较低,尤其在扫描大量IP时,耗时非常长。借助Python的协程特性,我们可以实现高并发的网络扫描,显著提高扫描速度,并且在处理多个任务时能够有效地节省系统资源。通过实践这一过程,读者不仅可以掌握端口扫描的基本原理,还能进一步理解如何在Python中高效地使用协程来解决实际问题。
小编环境
import sys
print('python 版本:',sys.version)
#python 版本: 3.11.11 | packaged by Anaconda, Inc. |
#(main, Dec 11 2024, 16:34:19) [MSC v.1929 64 bit (AMD64)]
效果
直接扫描IP地址:
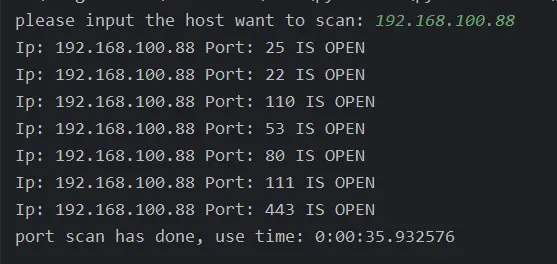
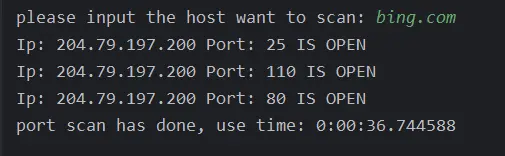
扫描域名:
完整代码
import asyncio
import socket
from datetime import datetime
class ScanPort:
def __init__(self, concurrency_limit=100):
self.ip = None
self.concurrency_limit = concurrency_limit # 并发限制,默认是 100
async def scan_port(self, port, semaphore):
try:
# 获取信号量
async with semaphore:
# 创建异步 TCP 连接
conn = asyncio.open_connection(self.ip, port)
reader, writer = await asyncio.wait_for(conn, timeout=1)
writer.close()
await writer.wait_closed()
print(f'Ip: {self.ip} Port: {port} IS OPEN')
except (asyncio.TimeoutError, ConnectionRefusedError, OSError):
pass # 忽略连接超时或端口未开启的错误
async def scan_ports(self):
semaphore = asyncio.Semaphore(self.concurrency_limit) # 限制最大并发数
tasks = []
for port in range(1, 65536): # 要扫描的端口范围
tasks.append(self.scan_port(port, semaphore)) # 为每个端口创建一个异步任务
await asyncio.gather(*tasks) # 并发执行所有任务
def start(self):
host = input("please input the host want to scan: ")
self.ip = socket.gethostbyname(host) # 获取主机的 IP 地址
start_time = datetime.now()
# 执行异步扫描
asyncio.run(self.scan_ports())
print("port scan has done, use time:", datetime.now() - start_time)
if __name__ == "__main__":
# 运行扫描程序
ScanPort(concurrency_limit=2000).start() # 设置并发量限制为2000
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
随着Python在Web开发、数据科学等领域的广泛应用,项目依赖管理与环境部署的效率直接影响着开发体验。传统的Python项目往往需要结合 virtualenv、pip 乃至 pipenv/poetry 等多种工具进行环境隔离、依赖安装与版本管理,步骤繁琐且容易因环境不一致导致运行问题
最近以来,一个名为 uv 的现代化、高性能 Python 包管理工具由 Astral 团队推出,它集成了虚拟环境管理、依赖解析与安装、项目初始化等核心功能,并以其极快的速度和简洁的命令受到开发者关注。uv 旨在简化 Python 项目的搭建与协作流程,通过一行命令即可完成从零开始的环境构建与依赖同步,大大提升了项目初始化与部署的效率
本文将基于一个实际的 FastAPI 项目案例,演示如何利用 uv 快速拉取现有项目、一键部署完整运行环境
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
拉取项目
这里以小编创建好的一个测试项目为案例进行操作,页面比较简单 github地址:https://github.com/DataShare-duo/uv_project
在本地终端或者git bash上执行:
git clone git@github.com:DataShare-duo/uv_project.git
uv 部署环境
前提:github上拉取的项目,必须是基于 uv 构建的
部署服务:
cd ./uv_project
uv sync
uv run main.py
在浏览器打开 http://0.0.0.0:8000 即可访问后端的服务,是不是很简单,可见 uv 工具是多么强大,通过一个命令 uv sync 构建好了项目的运行虚拟环境,即可启动服务,以往构建环境是多么的痛苦
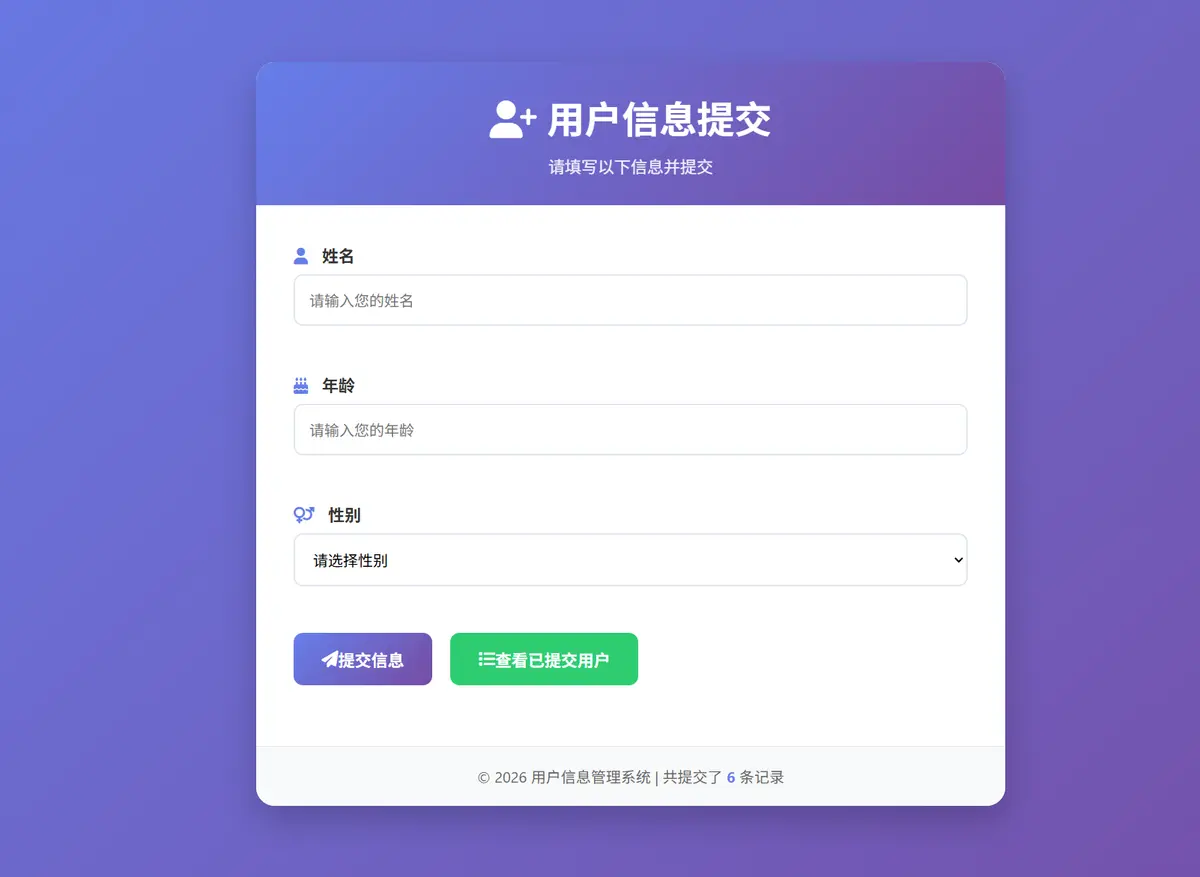
本地基于 uv 项目构建
以上的测试项目在本地通过 uv 构建的过程:
uv init uv_project --python 3.11
cd uv_project
uv add fastapi
uv add uvicorn
该项目的前、后端代码,均是利用 DeepSeek 生成,并调试运行成功
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
Python 不再是你记忆中的“弱类型”语言了! 随着类型注释的普及和高版本Python的演进,它正悄然蜕变为一门兼具灵活性与严谨性的现代语言
为什么使用类型注释?
1. 提升可读性 类型注释是代码的“自文档化”工具,明确参数和返回值的类型,让代码意图一目了然
def process_data(data: list[int], threshold: float) -> list[float]:
return [x * threshold for x in data if x > 0]
2. 错误早捕获 结合静态检查工具(如 mypy),在运行前发现类型错误,告别隐藏的 TypeError!
pip install mypy
mypy your_script.py # 静态检查
3. IDE智能支持 VS Code/PyCharm 等工具通过类型注释提供精准的代码补全和错误提示,开发效率翻倍
Python 已悄然“强类型化”
-
动态类型 ≠ 弱类型 Python 仍是动态类型语言,但类型注释的引入(PEP 484)和社区实践推动它向强类型风格演进
-
高版本特性加持(Python 3.10+)
- 联合类型简化:
int | str替代Union[int, str] - 类型守卫:用
isinstance()细化类型范围(PEP 647) - 模式匹配:
match/case中类型推断更智能
- 联合类型简化:
如何开始?
1. 升级Python版本
# 推荐使用 Python 3.10 或更高版本
python --version # 检查版本
2. 渐进式添加类型
- 从关键函数参数和返回值开始
- 无需一次性改造旧代码!
3. 常用类型示例
from typing import Optional, TypedDict
class UserProfile(TypedDict):
name: str
age: Optional[int]
def greet(user: UserProfile) -> None:
print(f"Hello, {user['name']}!")
拥抱改变,代码长青
类型注释不仅是“语法糖”,更是工程实践的进化。切换到 Python 高版本,用类型注释写出更健壮、更易维护的代码,迎接 Python 的强类型新时代!
你目前使用的是Python哪个版本?欢迎留言交流
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
上手 uv 一段时间后,真心觉得这款工具让 Python 项目管理变得省心不少!它不仅操作便捷,安装第三方包的速度更是快得飞起。
不过,在使用过程中也发现了一个小痛点:uv 默认会为每个项目创建独立的虚拟环境。这意味着,如果你同时开发多个项目,即使它们依赖相同的第三方包(比如常用的 requests、pandas),这些包也需要在每个项目的虚拟环境中重复安装。久而久之,宝贵的磁盘空间就这样被悄悄占用了不少。
难道只能忍受这种“甜蜜的负担”吗?当然不是!仔细翻阅 uv 的文档后发现,它其实贴心地提供了工作空间(Workspace)功能!通过工作空间,你可以让多个项目共享同一个虚拟环境。这样一来,公共依赖包只需安装一次,所有关联项目都能顺畅使用,大幅减少了重复安装带来的空间浪费,管理效率再上一个台阶!
在尝试获取 uv 工作空间(Workspace) 功能的相关信息时,小编注意到 DeepSeek 模型提供的回答有时存在不准确或偏离主题的情况。
这表明,uv 这一相对较新的功能细节,可能尚未被充分纳入 DeepSeek 当前模型版本的训练数据。这一现象也提醒我们,即使是强大的 AI 模型,其知识覆盖和能力也存在一定的边界与时效性局限
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
uv self version
# uv 0.8.2 (21fadbcc1 2025-07-22)
工作空间示例
- 创建根项目,并添加一个三方包
pandas在根项目的文件夹里面生成一个虚拟环境.venv,pandas被安装在该文件夹内
uv init workspace_project -p 3.11
cd workspace_project
uv add pandas
uv tree
workspace-project v0.1.0
└── pandas v2.3.1
├── numpy v2.3.1
├── python-dateutil v2.9.0.post0
│ └── six v1.17.0
├── pytz v2025.2
└── tzdata v2025.2
- 创建子项目1,并添加一个三方包
fastapi在子项目中添加的包,会被安装到根项目的虚拟环境.venv中
pwd # D:\桌面\Python\uv\workspace_project
uv init sub_project1 # 创建子项目1
cd sub_project1
uv add fastapi
uv tree
workspace-project v0.1.0
└── pandas v2.3.1
├── numpy v2.3.1
├── python-dateutil v2.9.0.post0
│ └── six v1.17.0
├── pytz v2025.2
└── tzdata v2025.2
sub-project1 v0.1.0
└── fastapi v0.116.1
├── pydantic v2.11.7
│ ├── annotated-types v0.7.0
│ ├── pydantic-core v2.33.2
│ │ └── typing-extensions v4.14.1
│ ├── typing-extensions v4.14.1
│ └── typing-inspection v0.4.1
│ └── typing-extensions v4.14.1
├── starlette v0.47.2
│ ├── anyio v4.9.0
│ │ ├── idna v3.10
│ │ ├── sniffio v1.3.1
│ │ └── typing-extensions v4.14.1
│ └── typing-extensions v4.14.1
└── typing-extensions v4.14.1
- 创建子项目2,并添加一个三方包
requests
pwd # D:\桌面\Python\uv\workspace_project
uv init sub_project2 # 创建子项目1
cd sub_project2
uv add requests
uv tree
workspace-project v0.1.0
└── pandas v2.3.1
├── numpy v2.3.1
├── python-dateutil v2.9.0.post0
│ └── six v1.17.0
├── pytz v2025.2
└── tzdata v2025.2
sub-project2 v0.1.0
└── requests v2.32.4
├── certifi v2025.7.14
├── charset-normalizer v3.4.2
├── idna v3.10
└── urllib3 v2.5.0
sub-project1 v0.1.0
└── fastapi v0.116.1
├── pydantic v2.11.7
│ ├── annotated-types v0.7.0
│ ├── pydantic-core v2.33.2
│ │ └── typing-extensions v4.14.1
│ ├── typing-extensions v4.14.1
│ └── typing-inspection v0.4.1
│ └── typing-extensions v4.14.1
├── starlette v0.47.2
│ ├── anyio v4.9.0
│ │ ├── idna v3.10
│ │ ├── sniffio v1.3.1
│ │ └── typing-extensions v4.14.1
│ └── typing-extensions v4.14.1
└── typing-extensions v4.14.1
所有的三方包都安装在根项目的虚拟环境内,path\workspace_project\.venv\Lib\site-packages,这样公共依赖包只需安装一次
以上的操作,其实是 uv 自动在根项目的配置文件 pyproject.toml 中,增加了如下配置,这样 uv 才识别所有项目同属于一个工作空间
[tool.uv.workspace]
members = [
"sub_project1",
"sub_project2",
]
- 在子项目2中使用同工作空间其它项目安装的包
import pandas as pd
import fastapi
def main():
print("Hello from sub-project2!")
if __name__ == "__main__":
main()
print('pandas版本:',pd.__version__)
print('fastapi版本:',fastapi.__version__)
运行:
pwd # D:\桌面\Python\uv\workspace_project\sub_project2
uv run .\main.py
# Hello from sub-project2!
# pandas版本: 2.3.1
# fastapi版本: 0.116.1
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
小编最近看公众号里面 uv 文章比较多,于是也尝试着用了一下,整体感觉对于开发项目人员来说很好,方便自动管理项目依赖,后期在部署时,可以根据 uv 自动构建的项目依赖来进行配置,省去各种包冲突麻烦
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
安装uv
自己本地已经安装了python,可以直接使用 pip 进行安装
pip install uv -i https://pypi.tuna.tsinghua.edu.cn/simple
uv --version
#uv 0.7.3 (3c413f74b 2025-05-07)
uv各命令
- 初始化项目
初始化项目时,可以指定python版本
uv init test1
uv init test2 -p 3.11
uv init test3 --python 3.11
- 添加依赖
用于安装包并自动更新项目配置文件(pyproject.toml)和锁定文件(uv.lock)
uv add 可以理解为 uv pip install的增强版,底层同样是利用了pip进行安装,但是uv add额外增加了更新项目配置文件的功能
uv add pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
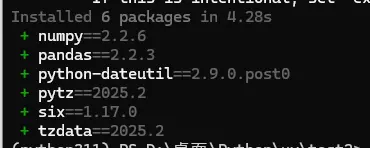
- 删除依赖 也会自动删除pandas依赖的其他包
uv remove pandas
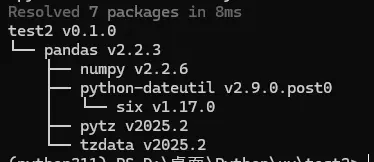
- 显示完整依赖树
uv tree
- uv python 命令
list 列出可用的Python安装版本
install 下载并安装Python版本
find 显示当前Python安装位置
pin 固定使用特定Python版本
dir 显示uv Python安装目录
uninstall 卸载Python版本
- uv 升级,自己升级
uv self update
- 设置全局默认python版本
uv python pin --global 3.11
- 安装python版本
uv python install 3.13
- 显示已安装的 Python 版本路径
uv python dir
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在公司内部的服务器中,安装三方库是需要经过层层审批,最后由运维人员进行安装,员工一般是没有权限去随意安装三方库,在审批之前需要进行测试验证可行性,那么这时就需要把三方库安装到自己有权限的目录中,然后再进行使用。小编这里经过亲身测试验证,分享出来供大家参考学习
指定文件夹下安装三方库
在python中安装三方库,默认使用 pip 命令进行安装,在该命令中可以通过 target 指定安装到的文件夹位置
pip3 install pyspark==2.4.3 \
--target=/mnt/disk1/datashare/python \
-i https://mirrors.aliyun.com/pypi/simple/ #指定阿里源
加载指定文件夹下安装的三方库
在安装三方库时是安装在指定文件夹下,所以需要把指定文件夹插入到 sys.path 的第1个位置,否则会加载系统自带的版本
import sys
lib_path = "/mnt/disk1/datashare/python"
sys.path.insert(0,lib_path) #插入安装三方库的文件夹
import pyspark
print(pyspark.__version__)
#2.4.3
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多 日期:2026年2月4日
背景
装饰器是Python中一种强大的语法糖,它允许我们在不修改原函数代码的情况下,为函数添加额外的功能。装饰器本质上是一个可调用对象,它接受一个函数作为输入,并返回一个新的函数。装饰器的使用方式非常灵活,既可以不带参数使用,也可以带参数使用
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
函数装饰器实现
我们先来看一个简单的函数装饰器实现:
import time
def delayed_start(func=None, *, duration=1):
def decorator(_func):
def wrapper(*args, **kwargs):
print(f"Wait for {duration} seconds before starting...")
time.sleep(duration)
return _func(*args, **kwargs)
return wrapper
if func is None:
return decorator
else:
return decorator(func)
这个装饰器可以以两种方式使用:
- 不带参数使用:当装饰器不带参数使用时,Python会直接将装饰的函数作为参数传递给
delayed_start
@delayed_start
def hello_no_arg(name="datashare"):
print("from hello_no_arg, param name =", name)
等价于:
hello_no_arg = delayed_start(hello_no_arg)
- 带参数使用:当装饰器带参数使用时,Python会先调用装饰器函数,返回一个真正的装饰器,然后再用这个装饰器装饰函数
@delayed_start(duration=2)
def hello_with_arg(name="datashare"):
print("from hello_with_arg, param name =", name)
等价于:
hello_with_arg = delayed_start(duration=2)(hello_with_arg)
实现原理
delayed_start函数的巧妙之处在于它通过检查 func参数是否为 None来判断装饰器的使用方式:
- 如果
func不是None,说明是不带参数使用,直接返回decorator(func) - 如果
func是None,说明是带参数使用,返回decorator函数等待接收真正的函数参数
类装饰器实现
类装饰器通过实现 __call__方法来实现装饰器的功能。下面是带参数和不带参数的类装饰器实现:
from functools import wraps
import time
class Timer:
def __init__(self, func=None, *, print_args=False):
self.func = func
self.print_args = print_args
def __call__(self, *args, **kwargs):
# 情况 1:@Timer(print_args=True)
# 第一次 __call__,args[0] 是函数
if self.func is None:
func = args[0]
return self._decorate(func)
# 情况 2:@Timer
# 或者已经绑定好函数,真正执行
return self._decorate(self.func)(*args, **kwargs)
def _decorate(self, func):
@wraps(func)
def wrapper(*args, **kwargs):
st = time.perf_counter()
ret = func(*args, **kwargs)
if self.print_args:
print(f'"{func.__name__}", args: {args}, kwargs: {kwargs}')
print(f"time cost: {time.perf_counter() - st:.4f} seconds")
return ret
return wrapper
- 不带参数使用:
@Timer
def compute(x):
time.sleep(1)
return x * 2
当类装饰器不带参数使用时,Python会创建 Timer类的实例,并将 compute函数传递给 __init__方法。此时 self.func就是 compute函数。当我们调用 compute(10)时,实际上是调用 Timer实例的 __call__方法
- 带参数使用:
@Timer(print_args=True)
def compute2(x):
time.sleep(1)
return x * 3
当类装饰器带参数使用时,Python会先调用 Timer(print_args=True)创建实例,此时 self.func为 None。然后用这个实例去装饰 compute2函数,这相当于调用 Timer实例的 __call__方法,并将 compute2作为参数传入
两种实现方式的比较
| 特性 | 函数装饰器 | 类装饰器 |
|---|---|---|
| 代码简洁性 | 更简洁,适合简单的装饰逻辑 | 更复杂,但结构更清晰 |
| 状态管理 | 需要使用闭包或nonlocal变量 | 可以使用实例属性,更直观 |
| 可扩展性 | 适合简单的装饰功能 | 适合需要维护状态的复杂装饰器 |
| 可读性 | 对于简单场景更易读 | 对于复杂场景更易维护 |
实际应用场景
- 性能监控:如
Timer装饰器,用于测量函数执行时间 - 权限验证:检查用户是否有权限执行某个函数
- 日志记录:自动记录函数的调用和参数
- 缓存:实现函数结果的缓存,提高性能
- 重试机制:当函数执行失败时自动重试
最佳实践
- 使用
functools.wraps装饰器来保留原函数的元数据(如函数名、文档字符串等) - 对于简单的装饰器,优先使用函数装饰器
- 对于需要维护状态的装饰器,考虑使用类装饰器
- 在设计带参数的装饰器时,确保同时支持带参数和不带参数的使用方式
总结
Python装饰器是一个强大而灵活的特性,它允许我们以非侵入式的方式增强函数的功能。通过掌握函数装饰器和类装饰器的实现方式,以及如何实现带参数和不带参数的装饰器,我们可以编写出更加通用和可重用的代码。无论是简单的函数增强还是复杂的状态管理,装饰器都能提供优雅的解决方案
理解装饰器的工作原理不仅有助于我们编写更好的装饰器,还能加深我们对Python函数式编程和元编程的理解,是成为高级Python开发者的重要一步
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多 日期:2026年4月10日
一、相同的目标:占位符与泛化
无论是 Python 的 TypeVar 还是 Rust 的 <T>,它们的核心使命完全一致:
定义一个“尚不确定具体类型”的占位符,让同一套代码逻辑安全地适用于多种不同类型
# Python: 定义一个泛型函数
from typing import TypeVar
T = TypeVar('T')
def first(items: list[T]) -> T:
return items[0]
#![allow(unused)] fn main() { // Rust: 定义一个泛型函数 fn first<T>(items: &[T]) -> &T { &items[0] } }
在两种语言中,类型检查器(Python 的 mypy , Rust 的 rustc)都能根据调用上下文自动推导出 T 的具体类型,并保证返回类型与输入元素类型一致
二、语法演进:殊途同归
Python 的类型标注语法一直在向更简洁、更内聚的方向演化,而 Rust 从一开始就采用了现在这种高效的形式
| 对比维度 | Python (TypeVar) | Rust 泛型参数 |
|---|---|---|
| 传统声明 | T = TypeVar('T')class Stack(Generic[T]): | struct Stack<T> { ... } |
| 现代声明(3.12+) | class Stack[T]: | struct Stack<T> { ... } |
| 函数定义 | def func[T](arg: T) -> T: | fn func<T>(arg: T) -> T { ... } |
可以看到,Python 3.12 引入的 PEP 695 语法已经让 Python 的泛型写法与 Rust 高度趋同——类型变量直接写在类名或函数名后的方括号内
三、类型约束:继承(Inheritance) vs. 特征(Trait)
这是两种语言泛型系统最核心的差异所在
Python:基于继承或协议的上界约束
Python 通过 bound 参数限定类型变量必须满足某个父类或协议(Protocol)
from typing import TypeVar, Protocol
class SupportsClose(Protocol):
def close(self) -> None: ...
T = TypeVar('T', bound=SupportsClose)
def safe_close(obj: T) -> T:
obj.close()
return obj
- 约束依据:是不是某个类的子类,或者是否实现了特定的方法集(鸭子类型)
- 运行时行为:
isinstance可以检查继承关系,但TypeVar本身不参与运行时类型强制
Rust:基于 Trait 的行为约束
Rust 没有传统意义上的继承,类型能否用作泛型参数完全取决于它是否实现了指定的 Trait
#![allow(unused)] fn main() { use std::io::Write; fn write_twice<T: Write>(mut writer: T) -> std::io::Result<()> { writer.write_all(b"hello")?; writer.write_all(b"world")?; Ok(()) } }
- 约束依据:实现了哪些 Trait,Trait 是显式的“行为契约”,不是隐式的继承关系
- 编译时强制:如果传入的类型没有实现
Write,编译直接失败
学习提示:Python 的
bound=SomeProtocol在思想上最接近 Rust 的T: SomeTrait。可以把 Rust 的 Trait 理解为必须显式声明并实现的、编译期强制的 PythonProtocol
四、型变(Variance):显式声明 vs. 自动推导
型变(协变、逆变、不变)是理解容器类型间替换关系的关键,Python 与 Rust 对型变的处理方式差异巨大
Python:定义 TypeVar 时显式声明型变
from typing import TypeVar, Generic
T_co = TypeVar('T_co', covariant=True) # 协变:只产出数据
T_contra = TypeVar('T_contra', contravariant=True) # 逆变:只消费数据
- 如果希望
Reader[Dog]可以赋值给Reader[Animal],必须将T标记为covariant=True,为可协变的 - 默认行为是不变(既不协变也不逆变),这是最安全的默认值
Rust:编译器自动推导型变
Rust 的类型系统会分析泛型参数在结构体或枚举中的使用方式,自动决定其型变
#![allow(unused)] fn main() { struct Producer<T> { value: T, // 只产出 T,编译器自动推导为协变 } struct Consumer<T> { _marker: std::marker::PhantomData<fn(T)>, // 只消费 T,编译器自动推导为逆变 } }
- Rust 不需要(也不能)用关键字显式声明协变/逆变,这减少了心智负担
- 型变信息主要用于生命周期的协变/逆变,对普通类型参数影响较小
核心口诀对比:
- Python:你需要自己声明型变(
covariant/contravariant)- Rust:编译器帮你搞定,你只需关注类型是否被读(产出→协变)或被写(消费→逆变)
五、运行时存在性:类型擦除 vs. 单态化
这一点是两者运行时行为的根本区别,直接影响你对“泛型性能”的认知
| 特性 | Python (TypeVar) | Rust 泛型 |
|---|---|---|
| 何时检查 | 静态类型检查器(mypy、pyright) | 编译器(rustc) |
| 运行时类型信息 | 完全擦除。list[int] 和 list[str] 在运行时都是 list。 | 单态化(Monomorphization)。为每个具体类型生成独立代码。 |
| 性能影响 | 零运行时开销(因为标注只是注释),但对运行速度无提升。 | 零成本抽象。运行时性能等同于手写的具体类型代码,无动态分发开销。 |
可否用 isinstance 检查 | ❌ 不可。isinstance(obj, list[T]) 是无效的。 | ❌ 不可,但编译时静态分发已保证类型正确。 |
关键理解: Python 的泛型是给工具看的,运行时 Python 解释器根本不知道
T是什么 Rust 的泛型是给编译器看的,编译后Option<i32>和Option<String>是完全不同的两套机器码
六、高级特性对照表
| 特性 | Python | Rust |
|---|---|---|
| 多个类型参数 | class Pair[K, V]: | struct Pair<K, V> |
| 常量泛型 | ❌ 不支持 | struct Array<T, const N: usize> |
| 可变长度类型参数 | TypeVarTuple(用于 *args 类型) | 通过元组或宏实现,无直接语法糖 |
| 高阶类型(泛型上的泛型) | ParamSpec(用于装饰器参数签名捕获) | 通过关联类型(Associated Types)和泛型 trait 部分实现 |
| 幽灵类型标记 | 不需要(类型已擦除) | PhantomData<T> 用于标记未直接使用的类型参数 |
七、从 Python 到 Rust:学习路径建议
- 先理解 Python
TypeVar的作用域与约束:熟悉bound和Protocol,它们是 RustTrait约束的心理映射 - 接受“编译时单态化”的概念:Python 里你写
def func[T](x: T)只有一个函数对象;Rust 里会为每个T生成一份独立的机器码。这是 Rust 高性能的来源,也是二进制体积可能增大的原因 - 忘记 Python 的型变显式声明:在 Rust 中,你几乎不需要手动操心协变/逆变,编译器会帮你处理
- 掌握 Rust Trait 系统:如果说 Python 的
TypeVar是“占位符”,那么 Rust 的Trait就是“准入证”。学好 Trait 是写好 Rust 泛型代码的关键
八、总结对比表
| 维度 | Python (TypeVar) | Rust 泛型 |
|---|---|---|
| 定义方式 | T = TypeVar('T') 或 class C[T] | struct S<T> 或 fn f<T> |
| 类型约束 | bound=BaseClass 或 bound=Protocol | T: Trait |
| 型变控制 | 显式声明 covariant / contravariant | 编译器自动推导 |
| 运行时行为 | 类型擦除,仅用于静态检查 | 单态化,零成本抽象 |
| 学习重心 | 理解继承、协议与型变规则 | 理解 Trait、所有权与单态化 |
掌握了 Python 的 TypeVar 和泛型思维,你已经拥有了理解 Rust 泛型系统的核心“元认知”。接下来只需要将“继承约束”切换为“Trait 约束”,将“运行时擦除”切换为“编译时单态化”,就能顺利迈入 Rust 的类型世界,可以利用已有的 Python 类型知识平滑过渡到 Rust 的泛型思维
历史相关文章
- Rust-是否会重写-Python-解释器与有关的库,替代-C-语言地位?
- Python-新晋包项目工具uv的简单尝试
- Python-项目管理新思路:用-uv-Workspace-共享虚拟环境,省时省空间!
- Python-利用-uv-“一键”-快速部署服务
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
懂编程语言最开始是属于程序猿的世界,现在随着国内人们受教育程度的提升、互联网科技的发展,业务人员也开始慢慢需要懂编程语言。从最近几年的招聘需求看,要求会Python则成为刚需。
业务人员之前使用的大部分都是Excel,现在随着数据量的提升,Excel已无法满足数据处理需求。如果在Excel里面数据量超过10万行,则Excel运行起来就相当卡顿。
下面展示一些在Excel里面常用的功能,看看其在Python里面具体是怎么实现的,Python处理数据用到的主要是pandas库,这也是《利用python进行数据分析》整本书介绍的对象。
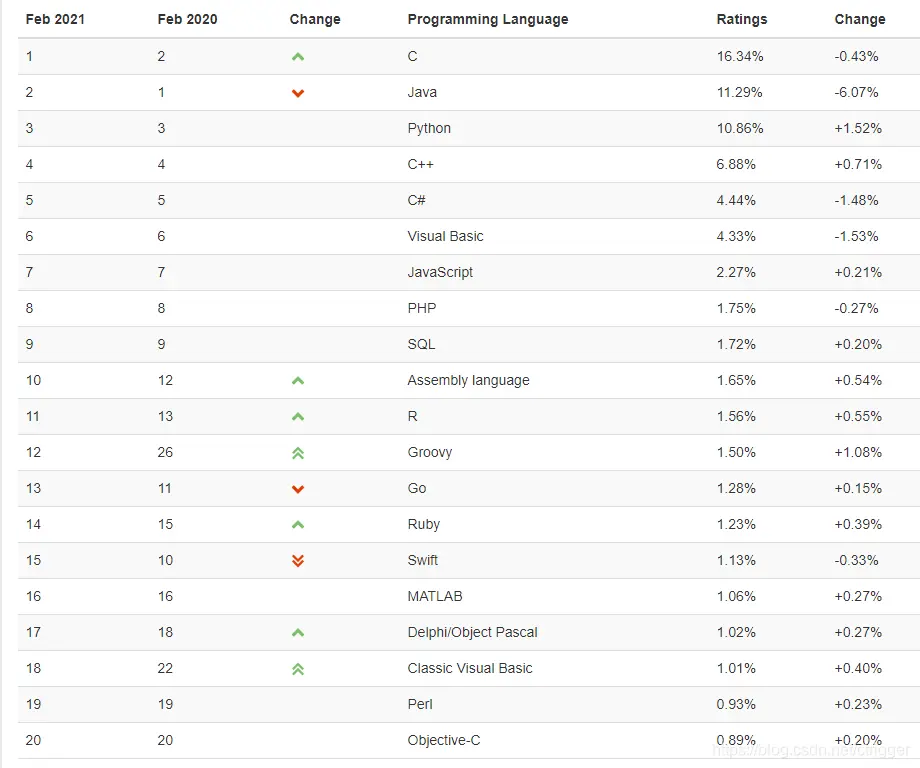
如下所示为2021年2月编程语言排行榜:
从排行榜来看,python越来越吃香了
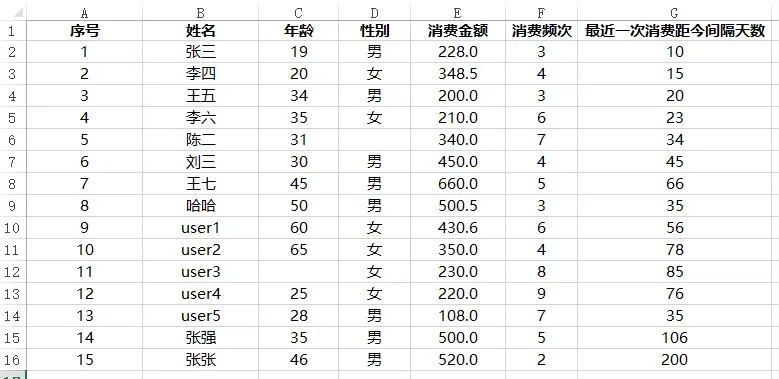
案例
这里只是展示方法,用到数据只有15行
导入模拟数据
import pandas as pd
import numpy as np
data = pd.read_excel('模拟数据.xlsx')
data.head()
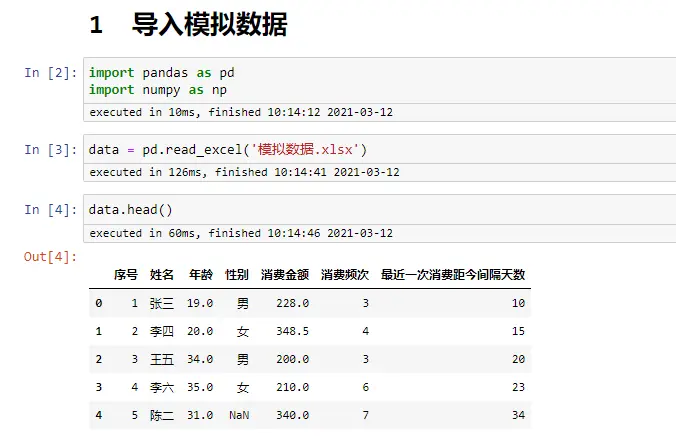
查看数据行、列
len(data) #数据行数
len(data.columns) #数据列数
data.info() #数据各列详细信息
data.describe() #默认,值统计数值型列
data.describe(include='all') #所有列
data.describe(include='object') #只针对列为字符型
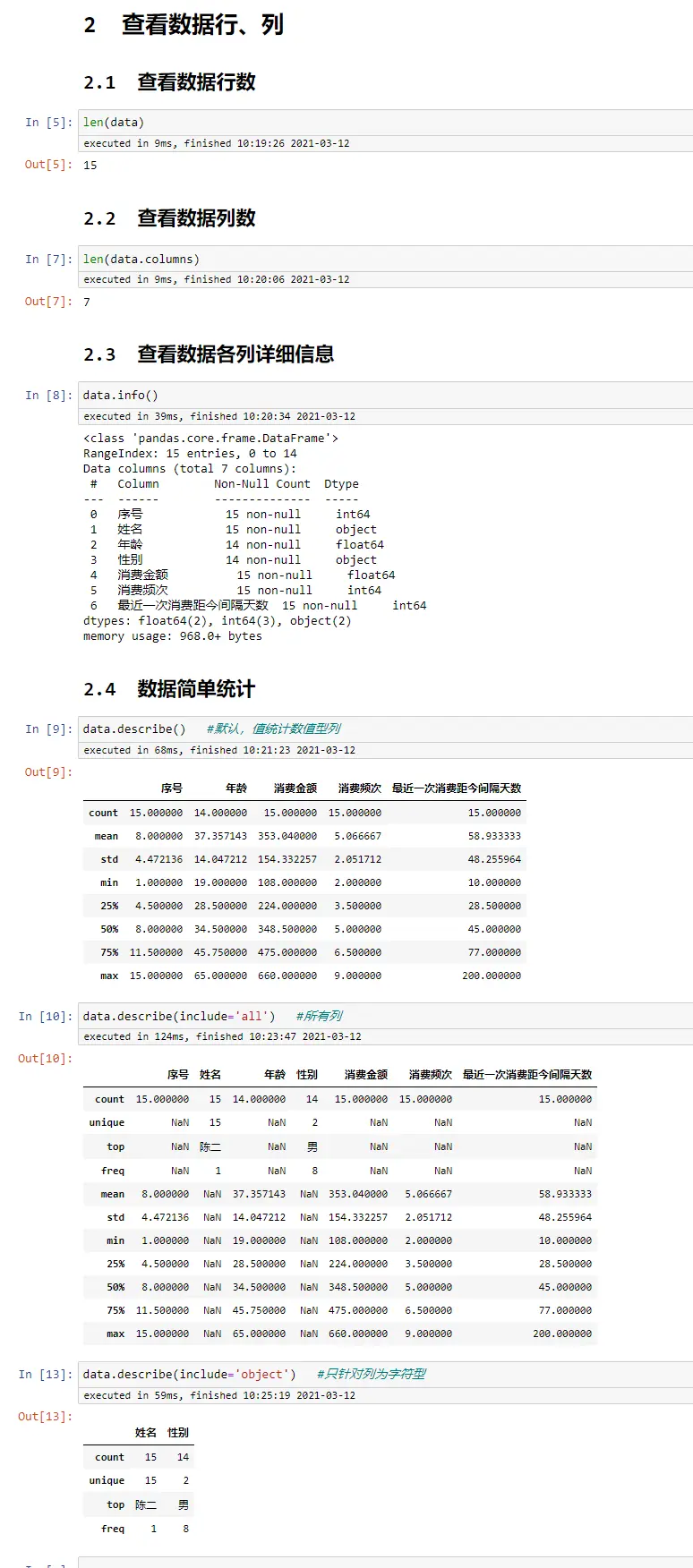
查看数据类型
data.dtypes
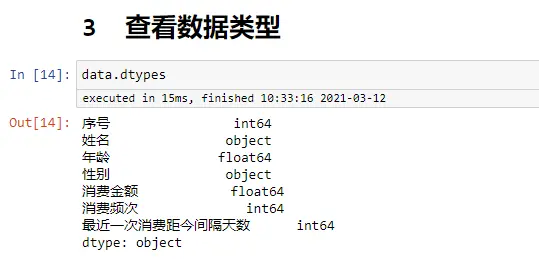
数据筛选
data[data['性别']=='男']
data[data['年龄']>=30]
data[(data['年龄']>=30) & (data['性别']=='男')] #两个条件 与
data[(data['年龄']>=30) | (data['性别']=='男')] #两个条件 或
基于筛选,修改里面的数据
data.loc[data['姓名']=='张三','性别']='女' #把张三 性别 修改为:女
data

数据缺失值替换
data #性别、年龄 里面各有个缺失值
int(data['年龄'].mean(skipna=True))
#年龄的缺失值,用平均值来代替
data['年龄'].fillna(int(data['年龄'].mean(skipna=True)),inplace=True)
data
data['性别'].fillna('其他',inplace=True)
data
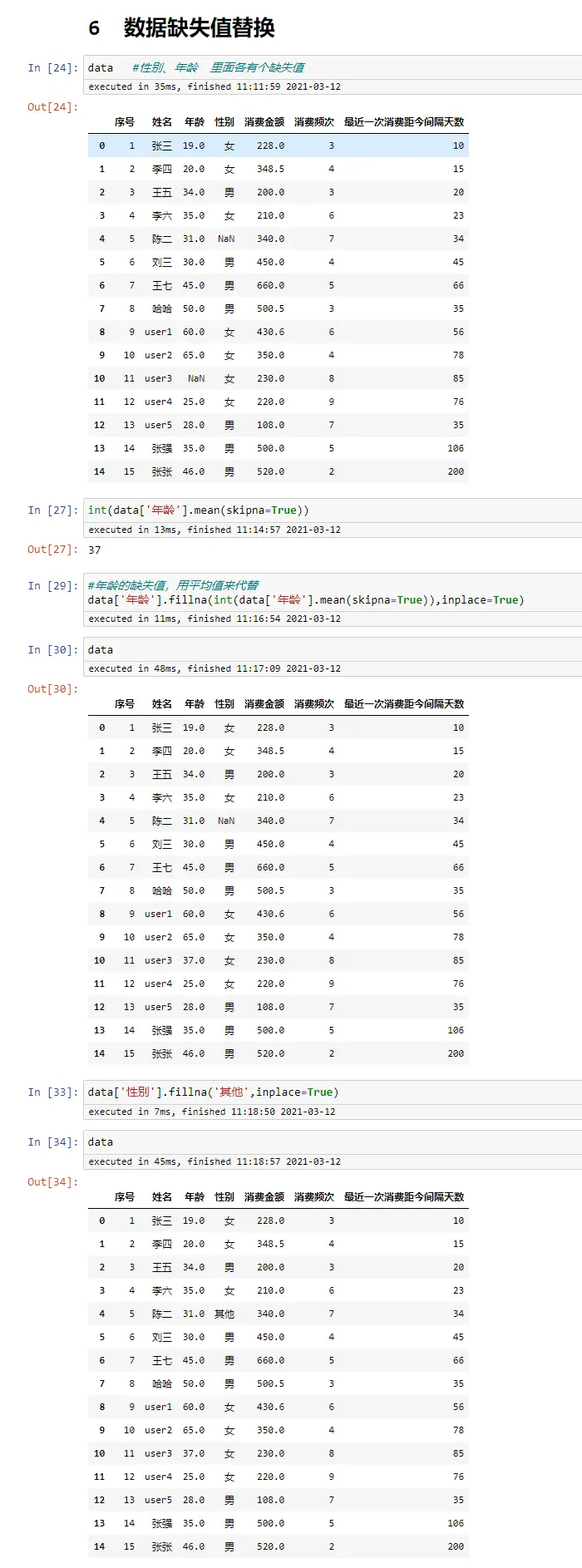
添加行
#方法一
data.loc[15]=[16,'new',55,'女',350,4,50]
data
#方法二
data_new = pd.DataFrame([[16,'new',55,'女',350,4,50]],columns=data.columns)
pd.concat([data,data_new],ignore_index=True)
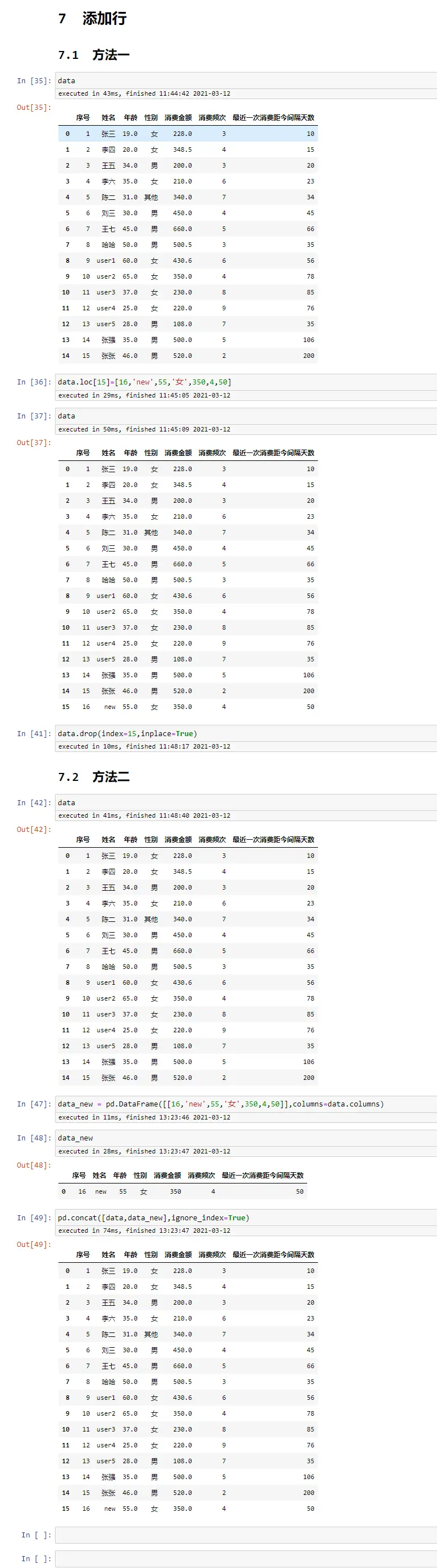
添加列
添加列相对比较简单,直接赋值即可
data['new_column_1']=0
data['new_column_2']='new'
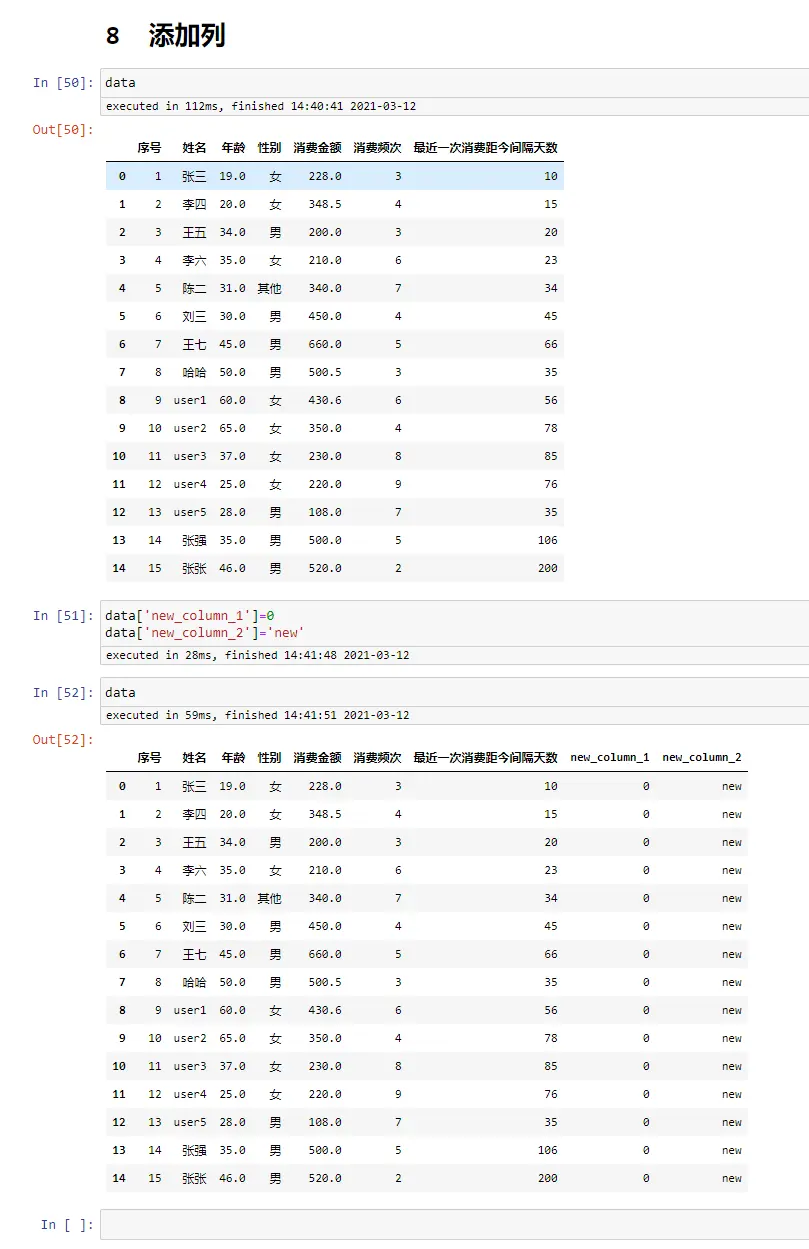
删除行
data.loc[15]=[16,'new',55,'女',350,4,50,0,'new'] #先添加一个测试行
data
data.drop(index=15,inplace=True) #删除行
data
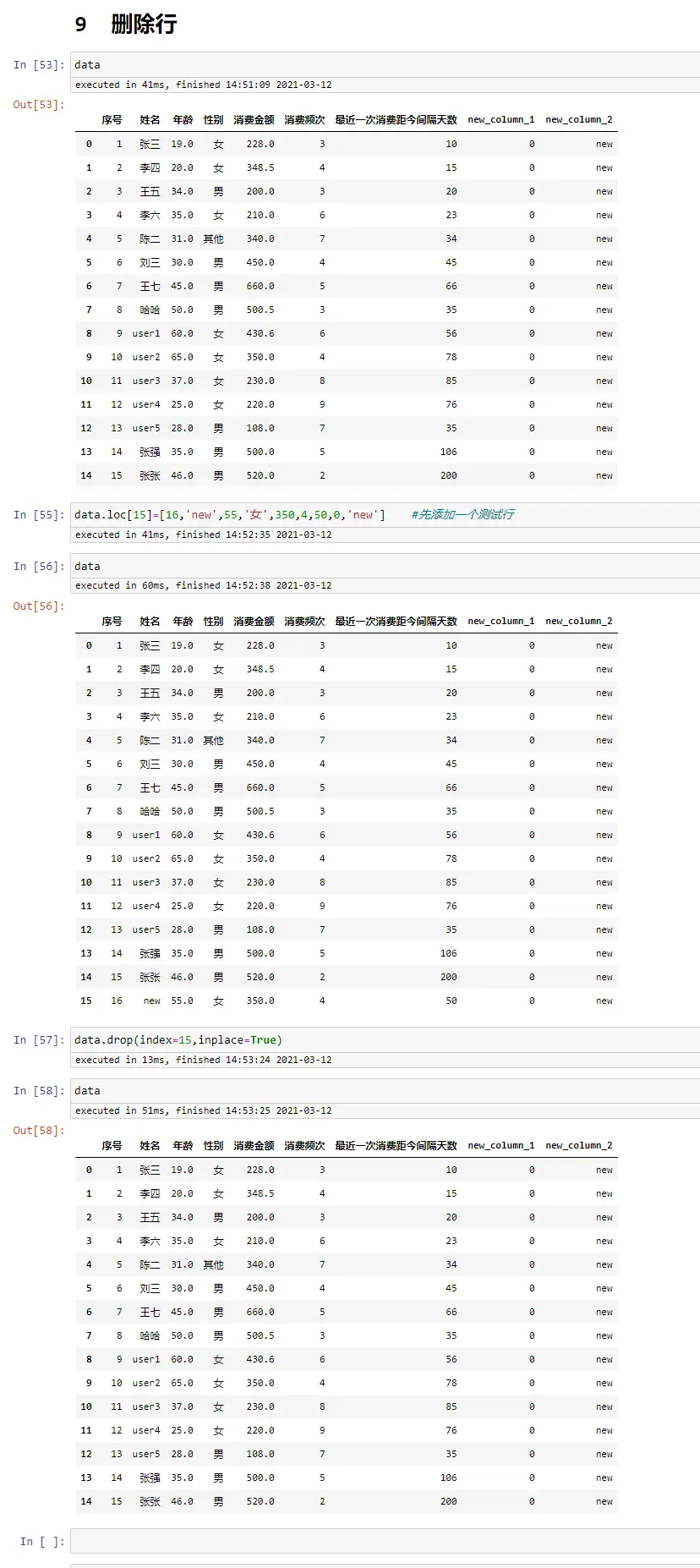
删除列
data.drop(columns='new_column_1') #返回删除后的新数据,原始数据不变
data.drop(columns=['new_column_1','new_column_2']) #返回删除后的新数据,原始数据不变
data.drop(columns=['new_column_1','new_column_2'],inplace=True) #在原始数据上处理
data
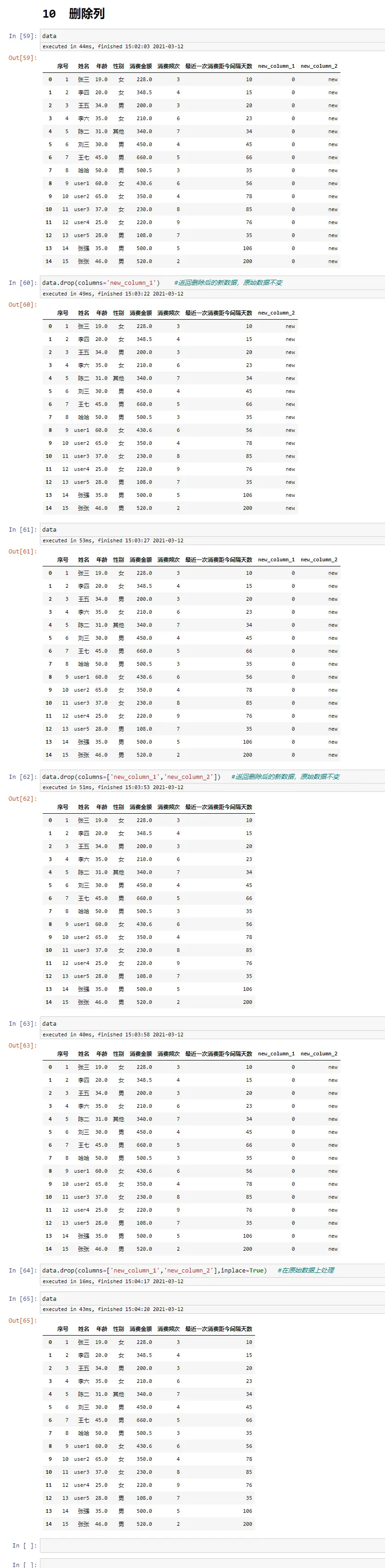
数据去重
data
data[['性别','消费频次']]
data[['性别','消费频次']].drop_duplicates(keep='first') #保留第1个,一般结合排序使用
data[['性别','消费频次']].drop_duplicates(keep='last') #保留最后1个,一般结合排序使用
#根据 性别、消费频次 2列进行去重
data.drop_duplicates(subset=['性别','消费频次'],keep='first')
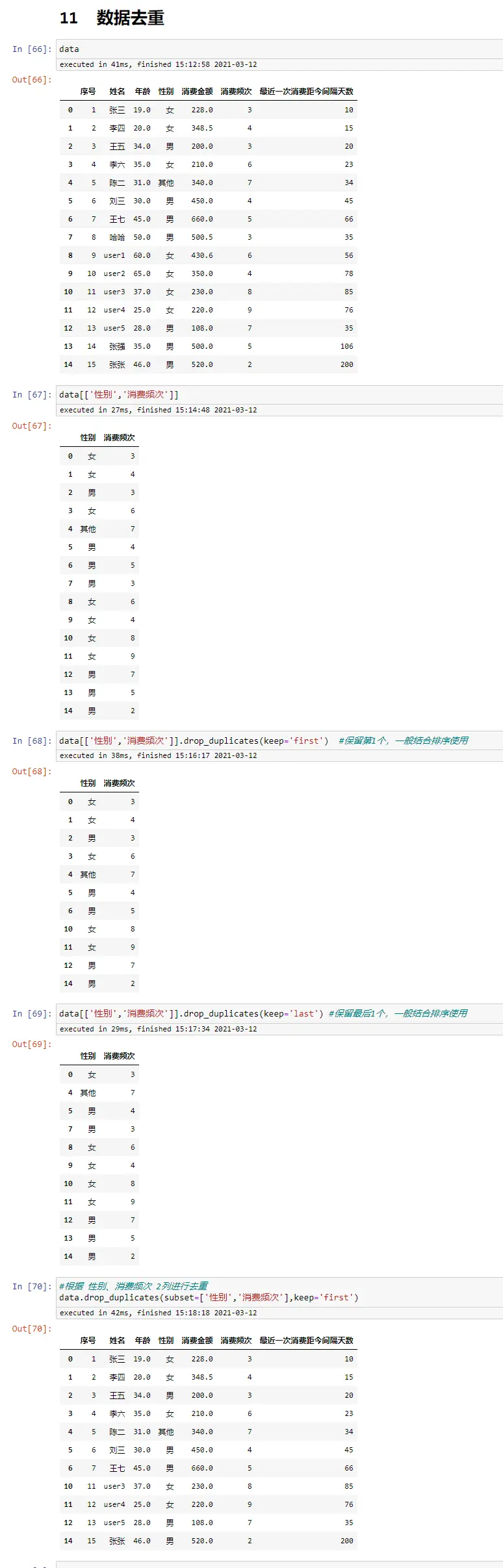
数据排序
相对Excel方便很多
data
data.sort_values(by='消费金额',ascending=True)
data.sort_values(by='消费金额',ascending=False)
data.sort_values(by=['消费频次','消费金额'],ascending=[False,True])
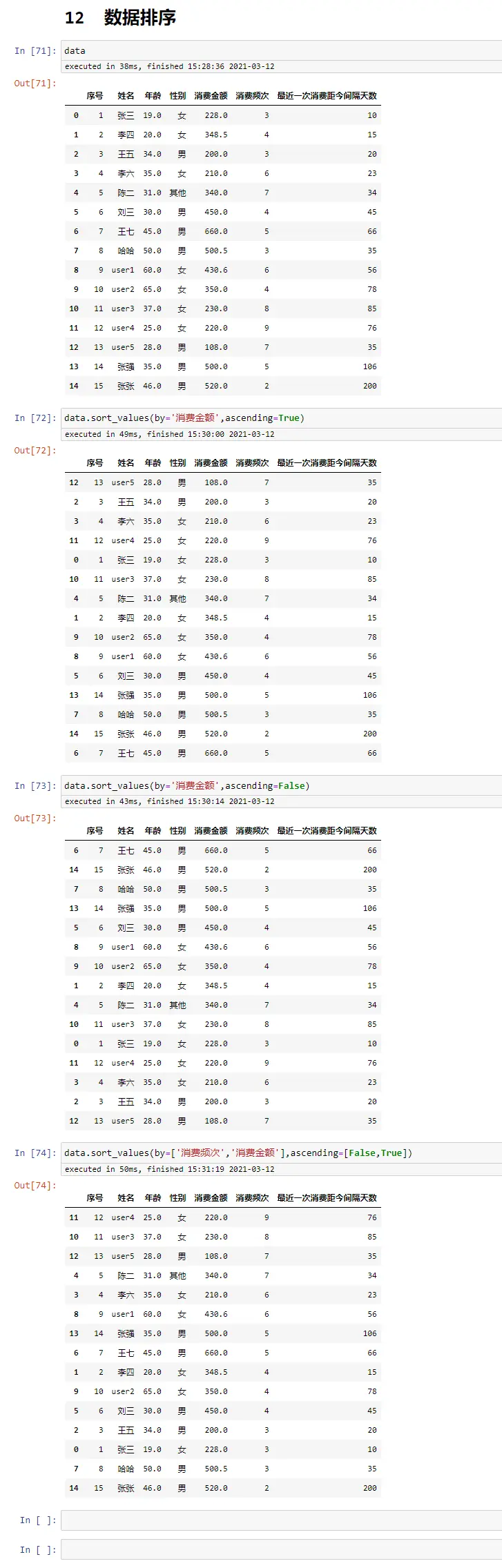
数据统计
data
data['性别'].value_counts()
data['性别'].value_counts(normalize=True) #百分比
data.value_counts(subset='性别')
data.value_counts(subset=['消费频次'],sort=True,ascending=True)
数据透视表
data
pd.pivot_table(data,index=['性别'],aggfunc='count')
pd.pivot_table(data,index=['性别'],values=['姓名'],aggfunc='count')
pd.pivot_table(data,index=['性别'],
columns=['消费频次'],
values=['姓名'],
aggfunc='count',
fill_value=0)
pd.pivot_table(data,index=['性别'],
columns=['消费频次'],
values=['姓名'],
aggfunc='sum',
fill_value=0)
pd.pivot_table(data,index=['性别'],
columns=['消费频次'],
values=['消费金额'],
aggfunc='sum',
fill_value=0)
pd.pivot_table(data,index=['性别'],
columns=['消费频次'],
values=['最近一次消费距今间隔天数'],
aggfunc='mean',
fill_value=0)
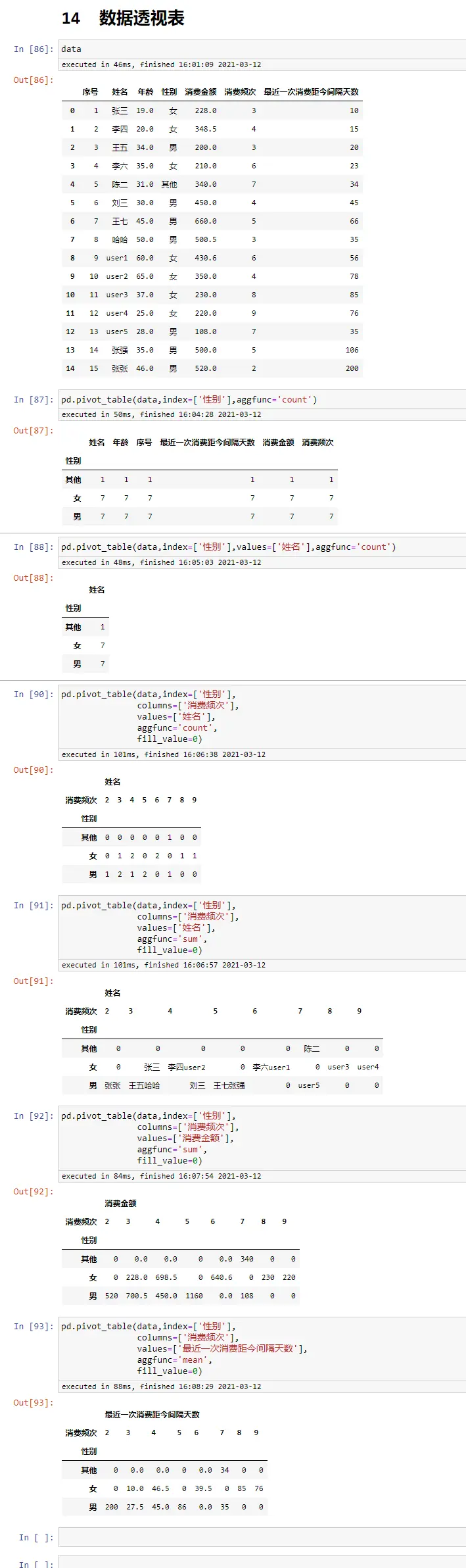
sum函数
data
data['消费金额'].sum()
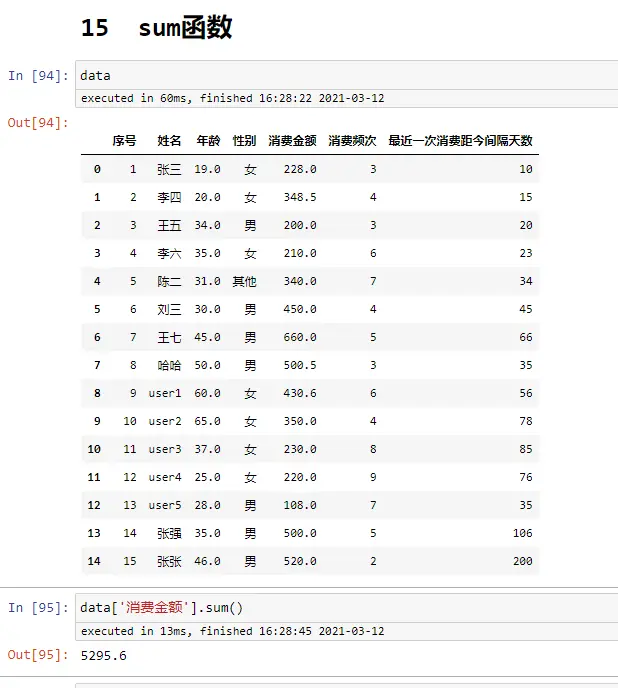
count函数
data
data.count()
data['姓名'].count()
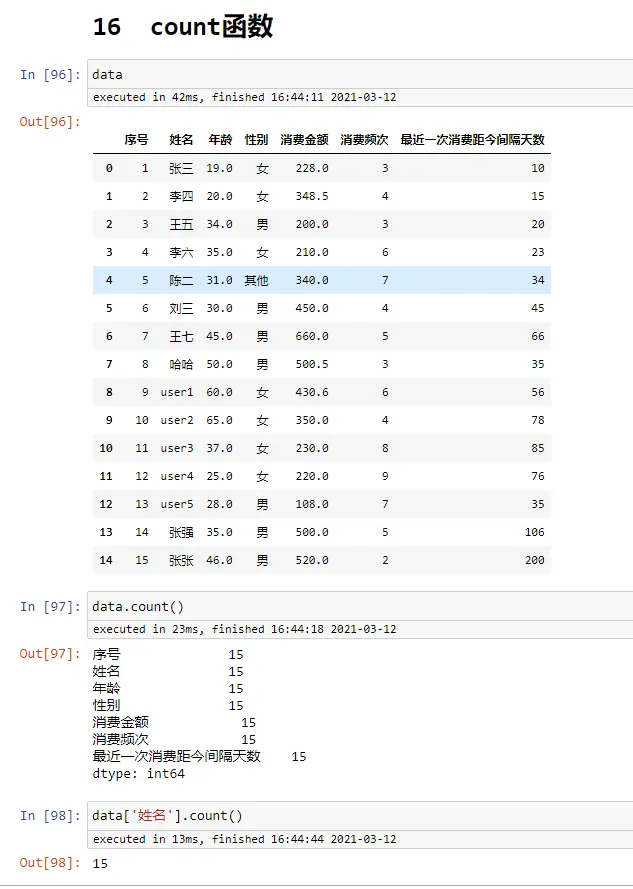
if函数
data
#方法一
data['性别_处理']=data['性别'].map(lambda x:1 if x=='男' else 0)
#方法二
def gender(x):
if x=='男':
return 1
else:
return 0
data['性别_处理2']=data['性别'].map(gender)
#方法三
dict_gender={'男':1,'女':0 ,'其他':0}
data['性别_处理3']=data['性别'].map(dict_gender)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在数据分析时,有时我们会碰到csv格式文件,需要先进行数据处理,转换成所需要的数据格式,然后才能进行分析
业务侧的同学可能对Excel文件比较熟悉,Excel可以把单个sheet直接保存为csv文件,也可以直接读取csv文件,变成Excel文件
技术侧的同学有时需要把数据库里面的数据导出到一个csv文件,有时也需要把别人给的csv文件加载到数据库中
csv文件在各个地方都这么流行,你真的彻底了解它吗?
CSV(逗号分隔值文件格式),逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号)
csv文件包含的各种数据
-
常规的内容
表格中: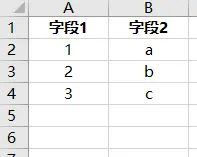
csv文件中: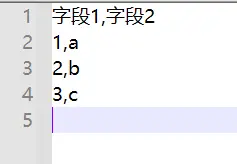
-
字段内部有逗号
表格中: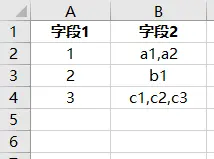
csv文件中: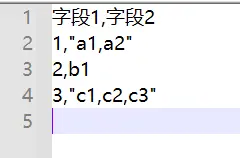
-
字段内部有引号
表格中: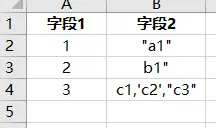
csv文件中:
-
字段内部有换行符
表格中: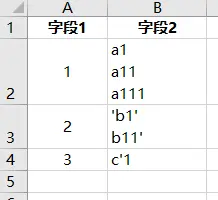
csv文件中:
-
字段内部有空格
表格中: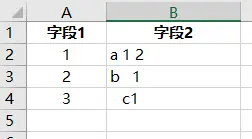
csv文件中:
csv文件规则
从上面的各种内容可以看出,当字段中包含特殊的字符时,在csv文件中会用双引号进行特殊处理
官方标准:
RFC4180:https://www.rfc-editor.org/rfc/rfc4180.txt
维基百科wiki:https://wiki.lazarus.freepascal.org/CSV
- 字段内包含逗号, 双引号, 或是换行符的字段必须放在双引号内
- 字段内包含引号必须在其前面增加一个引号,来实现引号的转码
- 元素中的换行符将被保留下来
- 分隔符逗号前后的空格仍然会被保留
用pandas进行解析
- 常规的内容
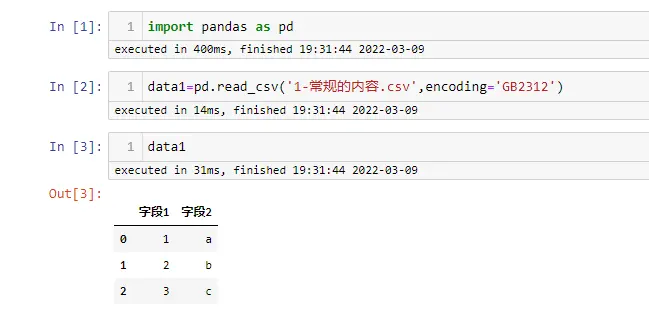
import pandas as pd
data1=pd.read_csv('1-常规的内容.csv',encoding='GB2312')
data1
- 字段内部有逗号
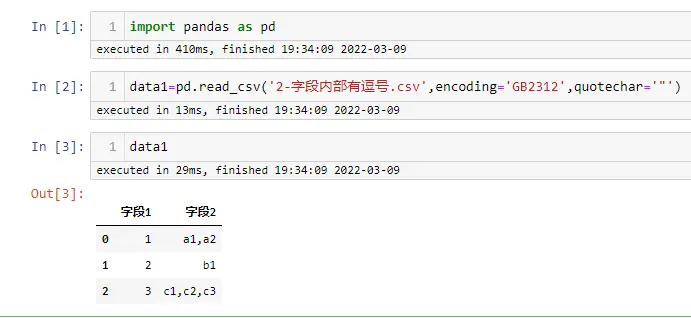
import pandas as pd
data1=pd.read_csv('2-字段内部有逗号.csv',encoding='GB2312',quotechar='"')
data1
- 字段内部有引号
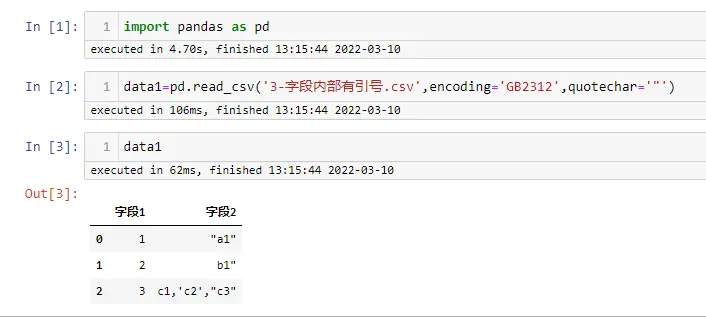
import pandas as pd
data1=pd.read_csv('3-字段内部有引号.csv',encoding='GB2312',quotechar='"')
data1
- 字段内部有换行符
该程序是在 Windows 平台运行,换行符为
\r\n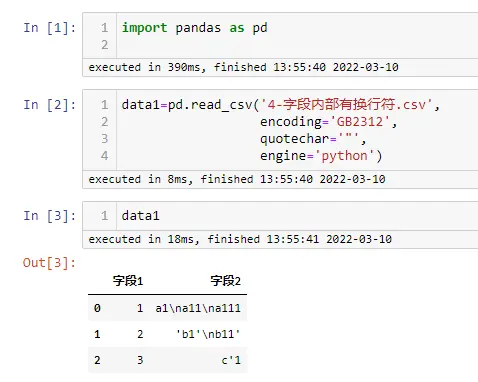
import pandas as pd
data1=pd.read_csv('4-字段内部有换行符.csv',
encoding='GB2312',
quotechar='"',
engine='python')
data1
- 字段内部有空格
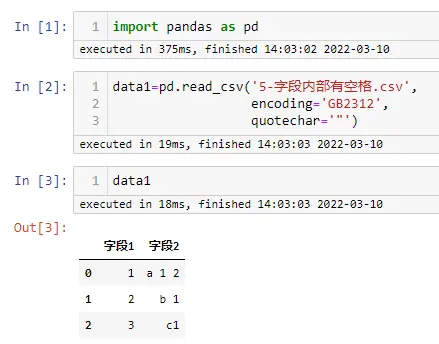
import pandas as pd
data1=pd.read_csv('5-字段内部有空格.csv',
encoding='GB2312',
quotechar='"')
data1
pd.read_csv部分参数解释
import pandas as pd
print(pd.__version__) #1.3.4
完整的参数:
pd.read_csv(
filepath_or_buffer: 'FilePathOrBuffer',
sep=<no_default>,delimiter=None,header='infer',names=<no_default>,
index_col=None,usecols=None,squeeze=False,prefix=<no_default>,
mangle_dupe_cols=True,dtype: 'DtypeArg | None' = None,
engine=None,converters=None,true_values=None,
false_values=None,skipinitialspace=False,skiprows=None,
skipfooter=0,nrows=None,na_values=None,keep_default_na=True,
na_filter=True,verbose=False,skip_blank_lines=True,
parse_dates=False,infer_datetime_format=False,keep_date_col=False,
date_parser=None,dayfirst=False,cache_dates=True,iterator=False,
chunksize=None,compression='infer',thousands=None,
decimal: 'str' = '.',lineterminator=None,quotechar='"',
quoting=0,doublequote=True,escapechar=None,
comment=None,encoding=None,encoding_errors: 'str | None' = 'strict',
dialect=None,error_bad_lines=None,warn_bad_lines=None,
on_bad_lines=None,delim_whitespace=False,low_memory=True,
memory_map=False,float_precision=None,storage_options: 'StorageOptions' = None,
)
下面主要解释一些常用的参数:
-
sep
sep参数是字符型的,代表每行数据内容的分隔符号,默认是逗号,另外常见的还有制表符(\t)、空格等,根据数据的实际情况传值 还提供了一个参数名为delimiter的定界符,这是一个备选分隔符,是sep的别名,效果和sep一样。如果指定该参数,则sep参数失效 -
dtype
指定各数据列的数据类型,建议在导入数据时全部使用字符型,dtype='str',后面在数据处理时再转换为需要的类型 -
engine
解析器、引擎,可以选择C或Python。 C语言的速度最快,Python语言的功能最为完善 -
iterator
是否设置为迭代器,如果设置为True,则返回一个TextFileReader对象,并可以对它进行迭代,以便逐块处理文件,一般结合chunksize使用,指定文件块的大小,分块处理大型CSV文件 -
lineterminator
每行的解释符号,但只能允许一个字符长度,仅对C解析器有效 -
quotechar
字段之间的定界符,这样就能正确解析包含特殊符号的字段了
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近在做数据处理时,发现别人给的 csv 文件用 txt 打开后,发现里面的所有字段都是带双引号,与自己之前见过的 csv 文件有点不一样,自己脑海里面隐约也见过 python 有相关的设置参数,于是就查看 python 官方文档中的 csv 模块介绍,总结分享出来予以记录,方便后续查看
csv文档地址:https://docs.python.org/zh-cn/3.11/library/csv.html
csv代码:https://github.com/python/cpython/blob/3.11/Lib/csv.py
csv 模块的常量是从 _csv 模型引入,_csv 是用 c 语言编写
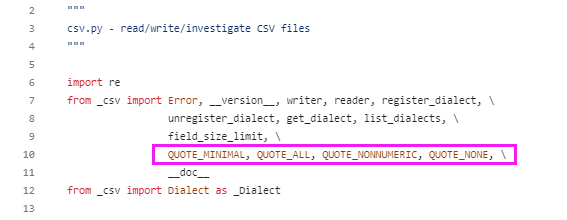

csv模块定义的常量说明
- csv.QUOTE_ALL,等于0
指示writer对象给所有字段加上引号 - csv.QUOTE_MINIMAL,等于1
指示writer对象仅为包含特殊字符(例如 定界符(delimiter)、引号字符(quotechar) 或 行结束符(lineterminator) 中的任何字符)的字段加上引号 - csv.QUOTE_NONNUMERIC,等于2
指示writer对象为所有非数字字段加上引号 指示reader将所有未用引号引出的字段转换为 float 类型 - csv.QUOTE_NONE,等于3
指示writer对象不使用引号括住字段。当 定界符(delimiter) 出现在输出数据中时,其前面应该有 转义符(escapechar)。如果未设置 转义符(escapechar),则遇到任何需要转义的字符时,writer都会抛出 Error 异常 指示reader不对引号字符进行特殊处理
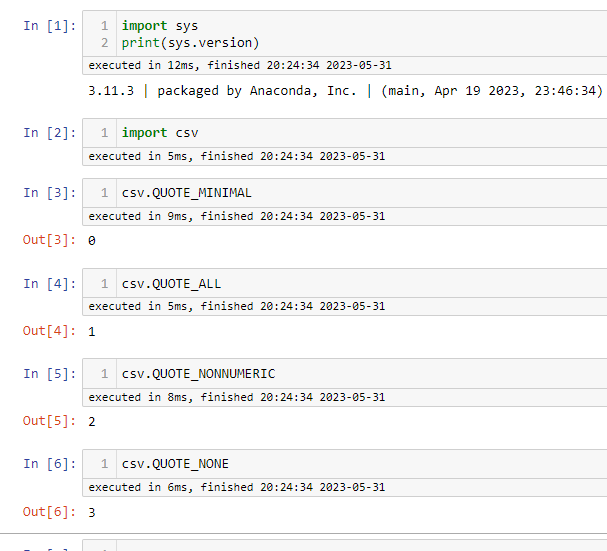
在 pandas 中的案例演示
模拟数据
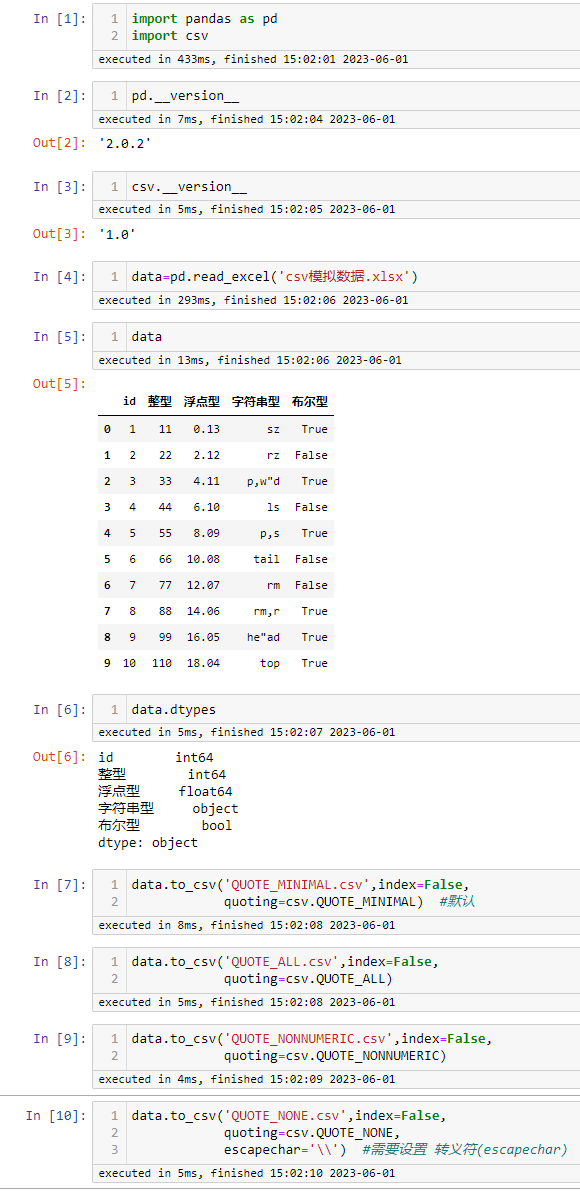
pandas to_csv
默认使用的是 csv.QUOTE_MINIMAL
文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_csv.html


csv.QUOTE_ALL 生成csv文件

csv.QUOTE_MINIMAL 生成csv文件

csv.QUOTE_NONNUMERIC 生成csv文件

csv.QUOTE_NONE 生成csv文件

jupyter-notebook 完整代码
历史相关文章
- 对csv文件,又get了新的认知
- Python pandas在读取csv文件时(linux与windows之间传输),数据行数不一致的问题
- Python pandas数据分列,分割符号&固定宽度
- Python 字符串格式化方法总结
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
由于身边同事经常买双色球,时间长了也就慢慢关注这个,我们中午经常也一块去吃饭,然后去彩票站点。之前是在支付宝上面就可以买,那会自己也会偶尔买10元的。这片文章主要是爬取了历史双色球所有数据,并进行简单分析,纯属业余爱好,分析结果仅供参考。
1.数据爬取网页
历史双色球数据:https://datachart.500.com/ssq/
#分析网页后可以得知get历史所有数据的参数
url='https://datachart.500.com/ssq/history/newinc/history.php?start=03001'
#加载相关的库
import requests
import numpy as np
import pandas as pd
#获取历史所有双色球数据
response = requests.get(url)
response.encoding = 'utf-8'
re_text = response.text
#网页数据解析
re=re_text.split('<tbody id="tdata">')[1].split('</tbody>')[0]
result=re.split('<tr class="t_tr1">')[1:]
all_numbers=[]
for i in result:
each_numbers=[]
i=i.replace('<!--<td>2</td>-->','')
each=i.split('</td>')[:-1]
for j in each:
each_numbers.append(j.split('>')[1].replace(' ',''))
all_numbers.append(each_numbers)
#定义列名称
col=['期号','红球1','红球2','红球3','红球4','红球5','红球6','蓝球','快乐星期天','奖池奖金(元)',
'一等奖注数','一等奖奖金(元)','二等奖注数','二等奖奖金(元)','总投注额(元)','开奖日期']
#解析完网页数据,生成双色球数据框
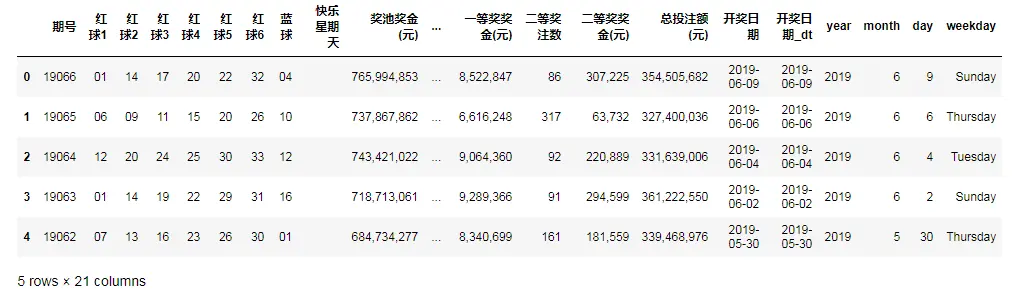
df_all=pd.DataFrame(all_numbers,columns=col)
df_all.head()

2.数据转换
#日期转换
df_all['开奖日期_dt']=pd.to_datetime(df_all['开奖日期'])
df_all['year']=df_all['开奖日期_dt'].dt.year
df_all['month']=df_all['开奖日期_dt'].dt.month
df_all['day']=df_all['开奖日期_dt'].dt.day
df_all['weekday']=df_all['开奖日期_dt'].dt.weekday_name
df_all.head()
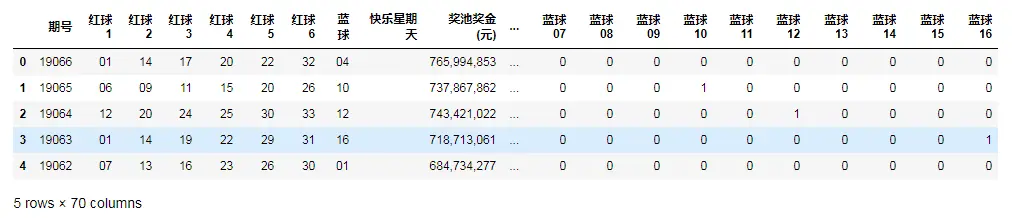
#one-hot 编码转换自定义函数
def lotterydata(df):
modeldata=df.copy()
redball=[]
for i in range(1,34):
redball.append('红球'+'%02d'%i)
for i in redball:
modeldata[i]=0
blueball=[]
for i in range(1,17):
blueball.append('蓝球'+'%02d'%i)
for i in blueball:
modeldata[i]=0
for row in range(modeldata.shape[0]):
#print(row)
#print(modeldata.iloc[row,:])
for i in redball:
#print(i)
#modeldata[i]=0
if (modeldata.iloc[row,:]['红球1']==i[-2:] or modeldata.iloc[row,:]['红球2']==i[-2:]
or modeldata.iloc[row,:]['红球3']==i[-2:] or modeldata.iloc[row,:]['红球4']==i[-2:]
or modeldata.iloc[row,:]['红球5']==i[-2:] or modeldata.iloc[row,:]['红球6']==i[-2:]):
modeldata.loc[row,i]=1
for j in blueball:
#modeldata[j]=0
if modeldata.iloc[row,:]['蓝球']==j[-2:]:
modeldata.loc[row,j]=1
return modeldata
#生成各颜色球的0-1编码
modeldata=lotterydata(df_all)
modeldata.head()
3.数据分析与展示
allhistorydata=modeldata.iloc[:,-49:].copy()
#历史所有红球和蓝球数据
allhistorydata_red=allhistorydata.iloc[:,:33]
allhistorydata_blue=allhistorydata.iloc[:,-16:]
#最近20期红球和最近48期蓝球
#(33*3)/6 每个红球有3次出现机会,看一共需要多少期,这里取整数20期
#(16*3)/1 每个蓝球有3次出现机会,看一共需要多少期
recently20_red=allhistorydata.iloc[:20,:33]
recently48_blue=allhistorydata.iloc[:48,-16:]
#求和
historyred_sum=allhistorydata_red.sum()
historyblue_sum=allhistorydata_blue.sum()
recently20red_sum=recently20_red.sum()
recently48blue_sum=recently48_blue.sum()
#排序
historyred_sum=historyred_sum.sort_values(ascending=True)
historyblue_sum=historyblue_sum.sort_values(ascending=True)
recently20red_sum=recently20red_sum.sort_values(ascending=True)
recently48blue_sum=recently48blue_sum.sort_values(ascending=True)
#数据展示
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文
plt.figure(figsize=(30,24),facecolor='snow')
#历史出现次数最少的10个红球
x_red=historyred_sum.index.map(lambda x:x[-2:])[:10]
y_red=historyred_sum.values[:10]
#历史出现次数最少的5个蓝球
x_blue=historyblue_sum.index.map(lambda x:x[-2:])[:5]
y_blue=historyblue_sum.values[:5]
plt.subplot(3,2,1)
plt.bar(x_red,y_red,width=0.4,align='center',color='r')
for a,b in zip(x_red,y_red):
plt.text(a,b,b,ha='center',va='bottom',fontsize=15)
plt.tick_params(axis='x',labelsize=30)
plt.title("历史出现次数最少的10个红球",fontsize=30)
plt.subplot(3,2,2)
plt.bar(x_blue,y_blue,width=0.2,align='center',color='b')
for a,b in zip(x_blue,y_blue):
plt.text(a,b,b,ha='center',va='bottom',fontsize=15)
plt.tick_params(axis='x',labelsize=30)
plt.title("历史出现次数最少的5个蓝球",fontsize=30)
#最近20期红球
x20_red=recently20red_sum.index.map(lambda x:x[-2:])
y20_red=recently20red_sum.values
#最近48期蓝球
x48_blue=recently48blue_sum.index.map(lambda x:x[-2:])
y48_blue=recently48blue_sum.values
plt.subplot(3,1,2)
plt.bar(x20_red,y20_red,width=0.5,align='center',color='r')
for a,b in zip(x20_red,y20_red):
plt.text(a,b,b,ha='center',va='bottom',fontsize=15)
plt.tick_params(axis='x',labelsize=25)
plt.title("最近20期红球情况",fontsize=30)
plt.subplot(3,1,3)
plt.bar(x48_blue,y48_blue,width=0.5,align='center',color='b')
for a,b in zip(x20_blue,y20_blue):
plt.text(a,b,b,ha='center',va='bottom',fontsize=15)
plt.tick_params(axis='x',labelsize=25)
plt.title("最近48期蓝球情况",fontsize=30)
plt.show()
最终的数据展示结果,仅供参考!!!
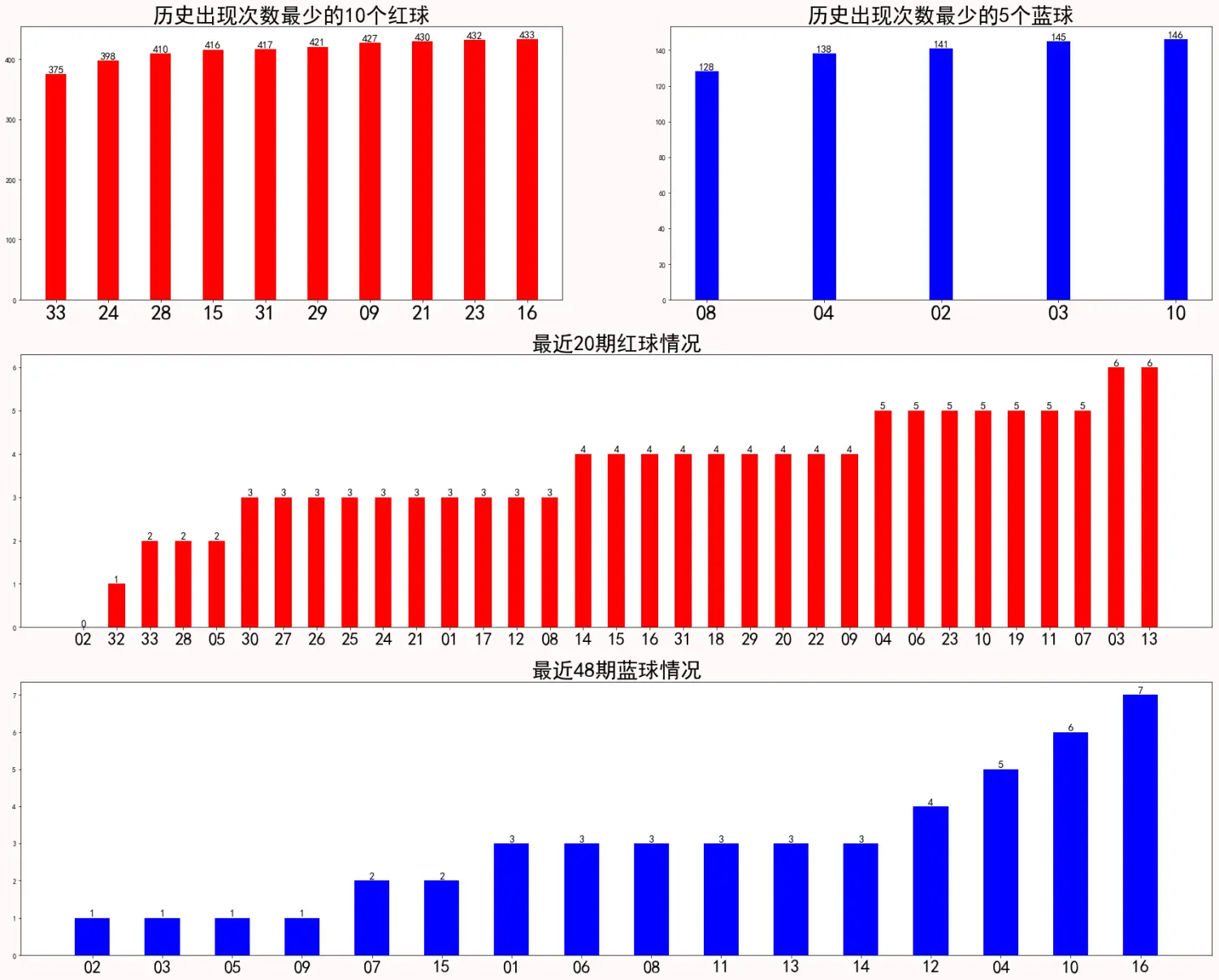
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
介绍
众所周知地球是一个球体,地平面是一个弧形,那么两个地理位置之间的中点该如何确定,比如北京与上海两个城市之间的中点在哪里?
可以直接对经纬度进行平均,求中点吗?
答案:当然不可以
我们都知道一个地理位置是由经度、维度来确定,平时在计算地理信息时基本都是两列数据,一列是经度,一列是维度,比如:
北京:"lon":116.512885,"lat":39.847469,
上海:"lon":116.332334,"lat":39.882806
- lon:longitude 经度
经度是指通过某地的经线面与本初子午面所成的二面角。
在本初子午线以东的经度叫东经,在本初子午线以西的叫西经。
东经用“E”表示,西经用“W”表示。
- lat:latitude 维度
赤道的纬度为0°,将行星平分为南半球和北半球。
纬度是指某点与地球球心的连线和地球赤道面所成的线面角,其数值在0至90度之间。
位于赤道以北的点的纬度叫北纬,记为N,位于赤道以南的点的纬度称南纬,记为S。
概念-----计算原理
那么应该怎么计算呢?
我们可以把地球看做是一个立体坐标系,有x轴,y轴,z轴三个方向,对于球面上的一个点,可以分别计算出在x轴,y轴,z轴的投影,那么在三个轴上面的分量是可以直接求均值,最后再进行反向合成,这样即可求出球面上对应的中点。
下图手工画出了,在x轴,y轴,z轴如何进行投影(可进行参考):
 根据手绘图可以计算出,各个分量:
根据手绘图可以计算出,各个分量:
x = cos(lat) * sin(lon)
y = cos(lat) * cos(lon)
z = sin(lat)
角度和弧度相互转换
由于我们实际数据中的经纬度是角度,而我们在计算分量时需要用弧度,比如 cos(π/2) ,这里就先需要转换,那么怎么进行转换:
python的math模块里面有相应转换函数
radians()-----将角度转换为弧度
degrees()-----将弧度转换为角度
脑补一下角度与弧度:
度和弧度都是衡量角的大小的单位,就像米(m)和英寸(in)都是用来衡量长度的单位。度用°来表示,弧度用rad表示。
1rad = (180/π)° ≈ 57.3°
1° = (π/180)rad ≈ 0.01745rad
弧度的定义
在一个圆中,弧长等于半径的弧,其所对的圆心角就是 1rad。也就是说,两条射线从圆心向圆周射出,形成一个夹角和夹角正对的一段弧。当这段弧的长度正好等于圆的半径时,两条射线的夹角的弧度为 1。根据定义,圆一周的弧度数为 2πr/r = 2π,360° = 2πrad,平角(即 180° 角)为 πrad,直角为 π/2rad
在具体计算中,角度以弧度给出时,通常不写弧度单位,直接写值。最典型的例子是三角函数,例如:sin(8π)、tan(3π/2)
自定义函数
import pandas as pd
import numpy as np
from math import cos, sin, atan2, sqrt, radians, degrees
data=pd.read_excel('./data.xlsx')
def center_geolocation(df):
"""
输入多个经纬度坐标,找出中心点 [lon,lat]->[经度,维度]
:param geolocations: 列表
:return 中心经纬度
"""
x = 0
y = 0
z = 0
lenth = len(df)
for lon, lat in zip(df['lon'].to_list(),df['lat'].to_list()):
lon = radians(float(lon)) #radians将角度转换为弧度
lat = radians(float(lat))
x += cos(lat) * sin(lon)
y += cos(lat) * cos(lon)
z += sin(lat)
x = float(x / lenth)
y = float(y / lenth)
z = float(z / lenth)
#degrees将弧度转换为角度
lon=degrees(atan2(x, y))
lat=degrees(atan2(z, sqrt(x * x + y * y)))
return pd.DataFrame({'lon':[lon],'lat':[lat]})
#使用
result_data=data.groupby('ID').apply(center_geolocation)
result_data.index=result_data.index.droplevel(level=1)
result_data.to_excel('./result_data.xlsx')
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
Excel里面数据透视表可谓是功能强大,可以对数据进行去重,可以方便的对数据进行汇总,可以对数据从不同维度进行交叉分析等,而且速度还非常快,即使有几万行数据。
当然在Python里面也有数据透视函数,但是没有Excel这么灵活,比如今天要介绍的这种情况,在值里面要一列放聚合的求和,一列放聚合后的占比,这在Excel里面可以非常方便的利用数据透视表的功能 值显示方式 来解决,今天这篇文章利用 自定义函数 来实现这个功能。
模拟数据
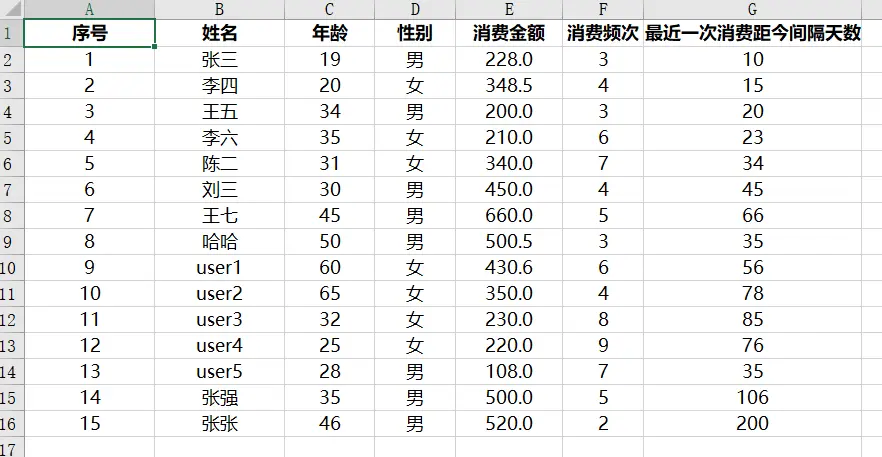
需要类似Excel数据透视表的结果
自定义函数
利用pandas的 pivot_table 函数可以实现求和功能,然后再让该列值除以总和来实现占比的功能
def pivot_percent(df, index, value, decimal=2):
'''
该函数 index、value 仅支持一个字段
df: 传入整个数据框
index: 维度
value: 汇总的值
decimal: 百分比保留的小数位数
'''
data_pivot = pd.pivot_table(data, values=value, index=index, aggfunc='sum')
data_pivot['占比'] = data_pivot[value]/data_pivot[value].sum()
data_pivot = data_pivot.sort_values(by=value, ascending=False)
#添加总计行
data_new = pd.DataFrame([[data_pivot[value].sum(), 1]],
columns=data_pivot.columns,
index=['总计'])
data_result = pd.concat([data_pivot, data_new], ignore_index=False)
#格式化百分比
data_result['占比'] = data_result['占比'].map(lambda x: f'{x:.{decimal}%}')
return data_result
jupyter notebook 完成代码
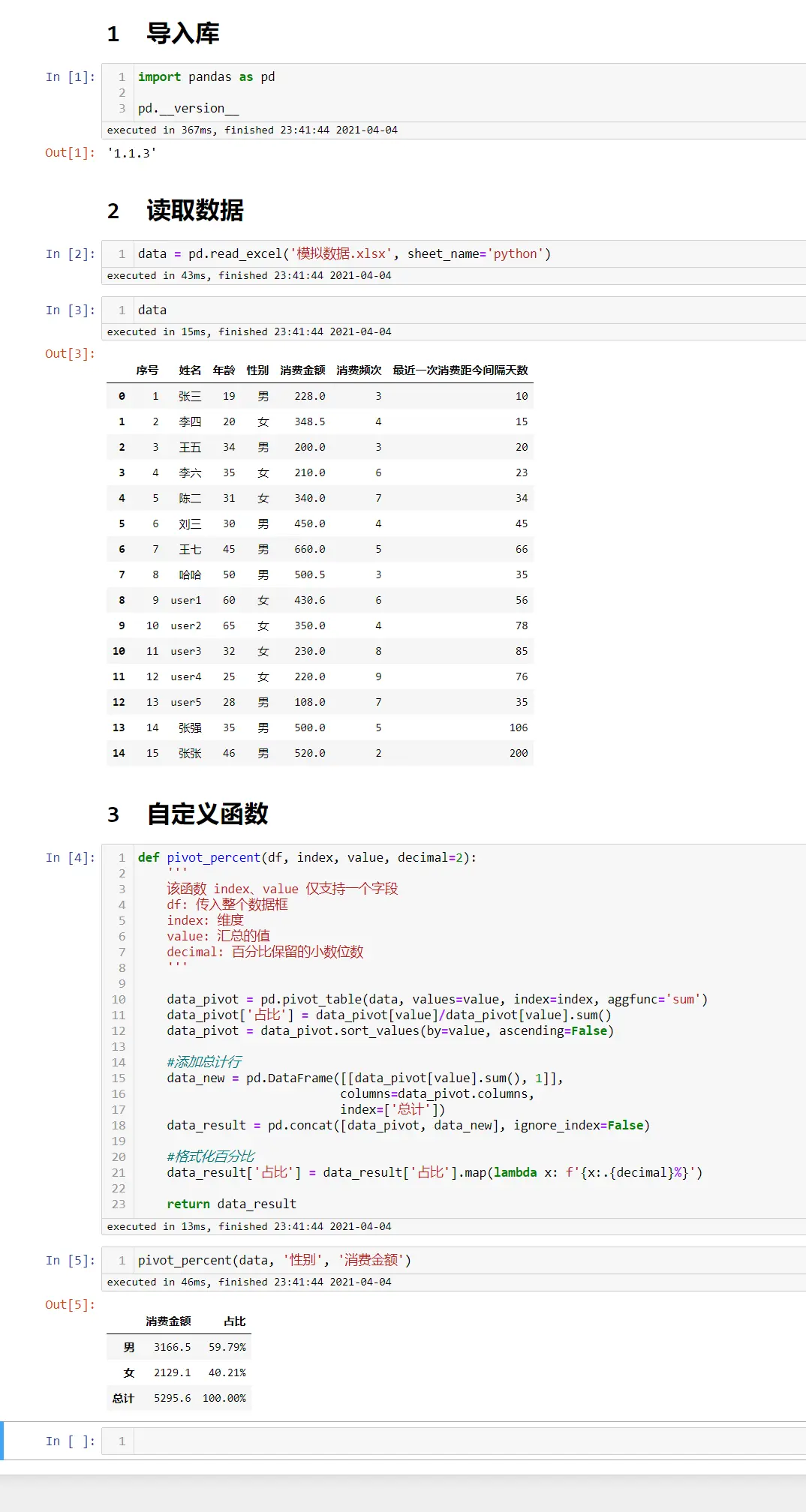
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
习惯了Excel里面的透视表拖拽方式,在Python中的pandas怎么能方便使用透视函数呢,有时可能会感到困惑,但是Excel中的透视表功能,pandas基本都能实现,下面进行详细介绍:
生成透视表函数
pd.pivot_table(data,values=None,index=None,columns=None,aggfunc='mean',fill_value=None,margins=False,dropna=True,margins_name='All')
详细介绍每个参数:
data:为了生成透视表需要用到的数据框,对应Excel里面的需要用到的区域
values:对那个字段进行值计算,对应Excel里面需要把字段拖拽到值的地方
index:根据字段进行汇总,生成每行一个分类,对应Excel里面需要把字段拖拽到行的地方
columns:根据字段进行汇总,生成每列一个分类,对应Excel里面需要把字段拖拽到列的地方
aggfunc:对值字段进行那种计算,计数、求和、平均,对应Excel里面对值字段设置里面的值汇总方式选择
fill_value:行分类与列分类交叉值为空的地方用什么值填充
margins:是否对行列显示汇总,对应Excel里面透视表下面设计选型卡,总计是否对行和列启用
dropna:是否包括原始引用数据里面都为NAN的列
margins_name:可以给总计的列起别名

示例
- 导入数据
import pandas as pd
data=pd.read_excel('111.xlsx',sheet_name='python')
data
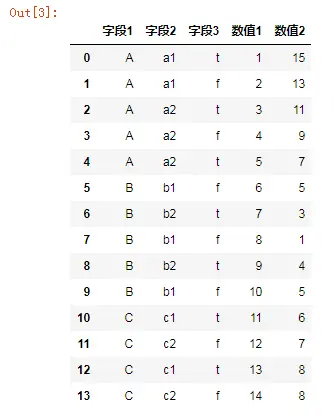
- 创建数据透视表
pd.pivot_table(data,values =['数值1','数值2'],index=['字段1','字段2','字段3'],aggfunc='sum')
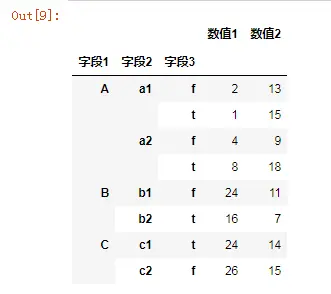
- 查看生成的数据透视表是什么
可以看到生成的数据透视表还是dataframe数据框,那么数据框能用的一切方法同样适用于生成的这个透视表
data_result=pd.pivot_table(data,values =['数值1','数值2'],
index=['字段1','字段2','字段3'],
aggfunc='sum')
type(data_result)

- 添加行列总计
#添加margins参数
pd.pivot_table(data,values =['数值1','数值2'],
index=['字段1','字段2'],
columns=['字段3'],
aggfunc='sum',
margins=True)
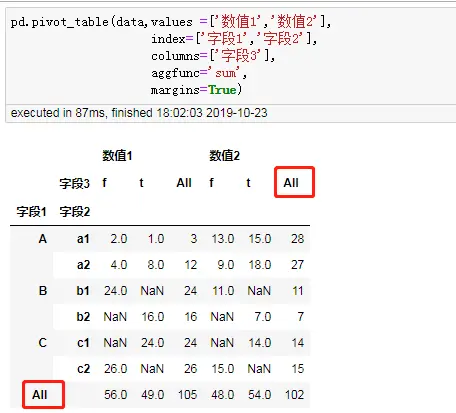
- 转换成正常的数据框
重置索引转换成正常的数据框样式
data_result=pd.pivot_table(data,values =['数值1','数值2'],
index=['字段1','字段2','字段3'],
aggfunc='sum').reset_index()
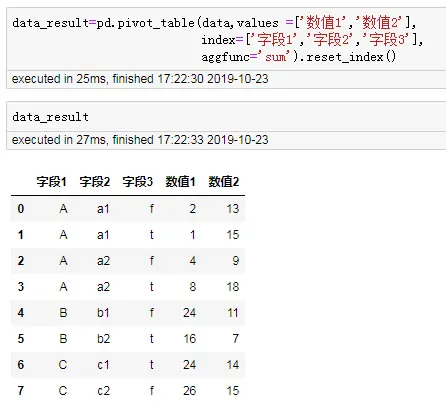
- 生成带列分类的透视表
pd.pivot_table(data,values =['数值1','数值2'],
index=['字段1','字段2'],
columns=['字段3'],
aggfunc='sum')
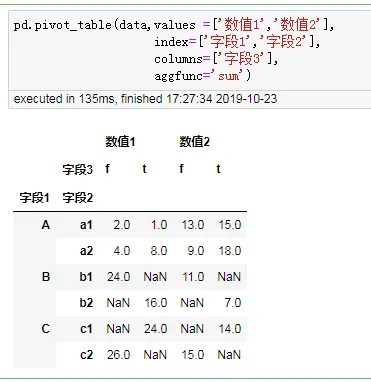
- 不同层级之间的调换
比如上面生成带列字段分类的透视表,需要把字段3(f、t)的一行和上面数值1、数值2的一行进行调换
#先进行一下赋值
data_result=pd.pivot_table(data,values =['数值1','数值2'],
index=['字段1','字段2'],
columns=['字段3'],
aggfunc='sum')
#修改列的名称
data_result.columns.names=['一','二']
#进行调换
data_result.swaplevel('二','一',axis=1)
#为了对相同内容放到一块,进行排序
data_result.swaplevel('二','一',axis=1).sort_index(level=0,axis=1)
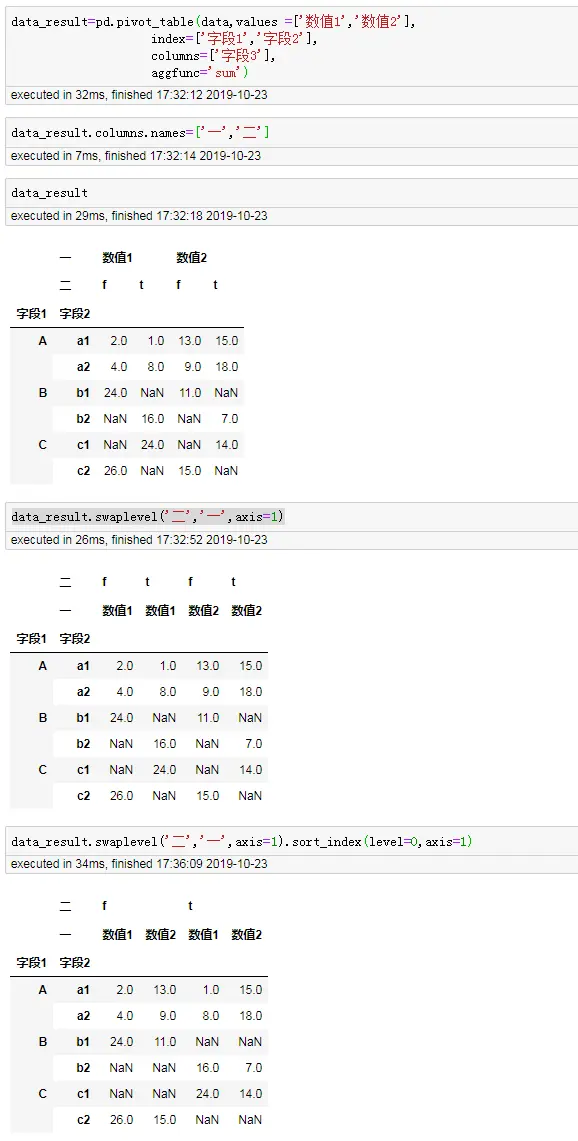
- 根据一列进行排序
#赋值操作
data_result=data_result.swaplevel('二','一',axis=1).sort_index(level=0,axis=1)
#进行排序
data_result.sort_values(by=[('f','数值2')],axis=0)
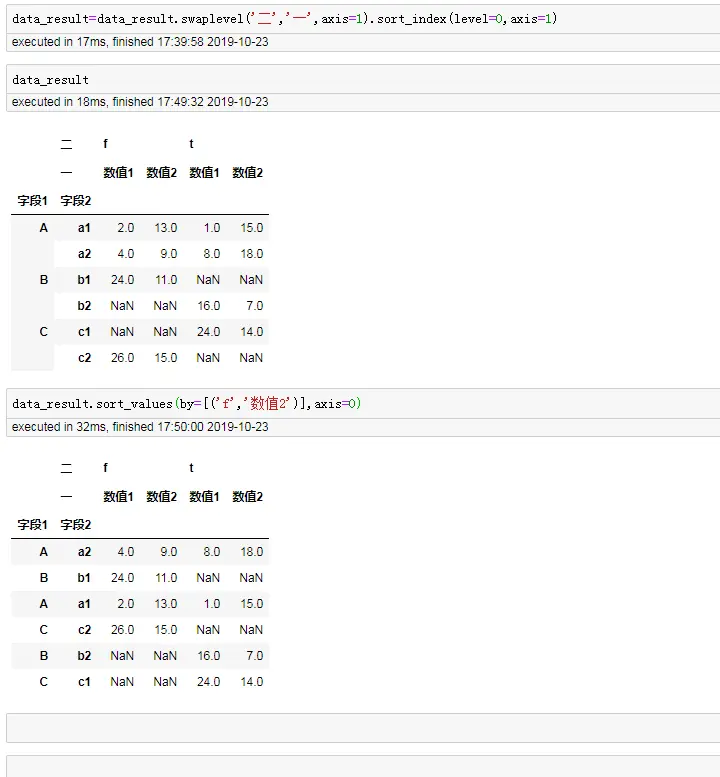
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
主要区别
shuffle没有返回值,直接在原来的数据上进行打乱排序,没有返回;而permutation是在数据副本上面进行打乱,返回打乱之后的副本。- 由于permutation会复制数据,所以当数据量特别大的时候,使用shuffle的效率更高。
- 无论是
shuffle还是permutation对二维及以上数据,都是只对第一维进行打乱顺序,第二维中的顺序并不会打乱。
示例
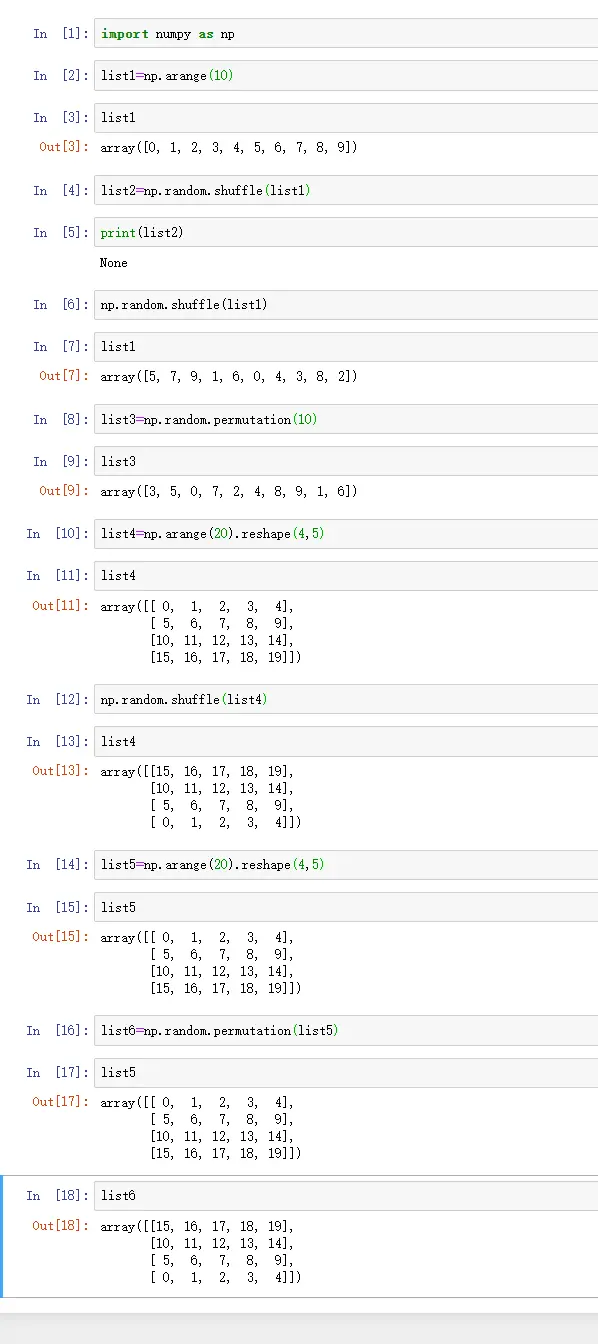
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在数据处理时,对原始数据进行筛选操作,在不注意情况下,会引发FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison 警告,究其根本原因就是在进行筛选时,对不同类型进行了比较,导致返回错误的结果
复现
可以看出,字段5是有2个7,现在想筛选出包含7的行
在进行筛选时,对列进行比较,引发错误提醒,FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison,导致没有筛选出结果

解决方法
由于在筛选时用的是逻辑索引,可以先看看逻辑索引结果
可以看出,逻辑索引结果均为False,所以没有成功筛选出数据,由于模拟的数据量比较小,咱们基本一眼就能看出问题所在,那就是在进行比较时,字段5的类型明显为数值型,而在进行比较时用的是字符型 ‘7’,所以导致引发错误提醒,当在进行大量数据操作时,这种错误可能会很难发现
先进行类型转换,然后再进行比较,即可得出正确的结果
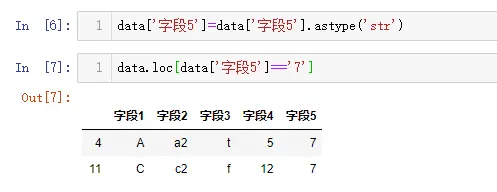
总结
我们在进行大数据操作时,一定要对数据类型进行确认,并且是真实的数据类型,至于为什么是真实的数据类型,详情可参考历史文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在Python里面处理数据,必然离不开Pandas,但目前网上的文章大部分都是介绍函数怎么使用,至于为什么有时数据处理结果是错误的,并没有深入研究,也可能是由于Pandas的一些BUG,没有人提出,下面介绍几个误区,看与你一直以为的一样吗
数据准备
平时大家都是从其他一些文件或数据库导入,在这里直接手动模拟一些数据,大家可以仔细看看这些数据有什么区别
>>> import pandas as pd
>>> df=pd.DataFrame({'x':[1,1,2,3,4,5,5,6],
'y':['A','B','C','D','E','F','E','A'],
'z':[11,21,32,34,'65',56,31,45]})
>>> df
x y z
0 1 A 11
1 1 B 21
2 2 C 32
3 3 D 34
4 4 E 65
5 5 F 56
6 5 E 31
7 6 A 45
df['x'] 与 df[['x']] 区别
乍一看上去,这两个可能并没有什么区别,都是对x列的引用,其实是有区别的,并且区别还是比较大,不信就看看
>>> df['x']
0 1
1 1
2 2
3 3
4 4
5 5
6 5
7 6
Name: x, dtype: int64
>>> df[['x']]
x
0 1
1 1
2 2
3 3
4 4
5 5
6 5
7 6
>>>
![df['x'] 与 df[['x']]区别](Python%E6%95%B0%E6%8D%AE%E5%A4%84%E7%90%86/./images/6641583-bca8cc08c734418f.webp) 上面程序打印结果一下看不出什么区别,下面的图片是不是一下就有区别了,为什么一个没有显示格式,一个是有格式;一个显示变量名称、数据类型,一个什么都没有,那就接着往下看,打印一下他们是Pandas里面的什么类型
上面程序打印结果一下看不出什么区别,下面的图片是不是一下就有区别了,为什么一个没有显示格式,一个是有格式;一个显示变量名称、数据类型,一个什么都没有,那就接着往下看,打印一下他们是Pandas里面的什么类型
>>> type(df['x'])
<class 'pandas.core.series.Series'>
>>> type(df[['x']])
<class 'pandas.core.frame.DataFrame'>
是不是恍然大悟,虽然都是对x列变量的引用,但是返回的结果是不一样的,一个是Series,一个是DataFrame,那么后续在这个结果上的操作肯定也是有很大区别,Series与DataFrame的方法、属性 各有千秋,区别很大
数据类型'object'
在创建数据时,一共创建了3列,其中x列与z列看出有什么区别了吗?没有仔细看的认为两列不都是数值吗???,其实并不然
>>> df.dtypes
x int64
y object
z object
dtype: object
怎么z列是object类型,那就再看一下创建数据时的z到底是什么:
'z':[11,21,32,34,'65',56,31,45],中间的'65'是字符型,所以导致z是object类型,也就说明:
pandas在检查数据类型时,当遇到数值型与字符型时,用字符型类型来代表这一列的类型,但里面每个值具体的类型还是原来的真实类型;都是数值型的则会转变,具体测试如下所示
>>> df1=pd.DataFrame({'x':[1,1,2,3.0,4,5,5,6],'y':['A','B','C','D','E','F','E','A']})
>>> df1
x y
0 1.0 A
1 1.0 B
2 2.0 C
3 3.0 D
4 4.0 E
5 5.0 F
6 5.0 E
7 6.0 A
>>> df1.dtypes
x float64
y object
dtype: object
>>> df
x y z
0 1 A 11
1 1 B 21
2 2 C 32
3 3 D 34
4 4 E 65
5 5 F 56
6 5 E 31
7 6 A 45
>>> for i in df['z']:
print(type(i))
<class 'int'>
<class 'int'>
<class 'int'>
<class 'int'>
<class 'str'>
<class 'int'>
<class 'int'>
<class 'int'>
>>> for i in df1['x']:
print(type(i))
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
数学概念
范数,是具有 “长度” 概念的函数。在线性代数、泛函分析及相关的数学领域,范数是一个函数,是矢量空间内的所有矢量赋予非零的正长度或大小。
在数学上,范数包括向量范数和矩阵范数
L1 范数和 L2 范数,用于机器学习的 L1 正则化、L2 正则化。对于线性回归模型,使用 L1 正则化的模型建叫做 Lasso 回归,使用 L2 正则化的模型叫做 Ridge 回归(岭回归)。
其作用是: L1 正则化是指权值向量 w 中各个元素的绝对值之和,可以产生稀疏权值矩阵(稀疏矩阵指的是很多元素为 0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是 0. ),即产生一个稀疏模型,可以用于特征选择;
L2 正则化是指权值向量 w 中各个元素的平方和然后再求平方根,可以防止模型过拟合(overfitting);一定程度上,L1 也可以防止过拟合。
Numpy函数介绍
np.linalg.norm(x, ord=None, axis=None, keepdims=False)
np.linalg.norm:linalg=linear(线性)+algebra(代数),norm则表示范数
x:表示矩阵(也可以是一维)ord:范数类型axis:轴向 axis=1表示按行向量处理,求多个行向量的范数 axis=0表示按列向量处理,求多个列向量的范数 axis=None表示矩阵范数。keepdims:是否保持矩阵的二维特性 True表示保持矩阵的二维特性,False相反
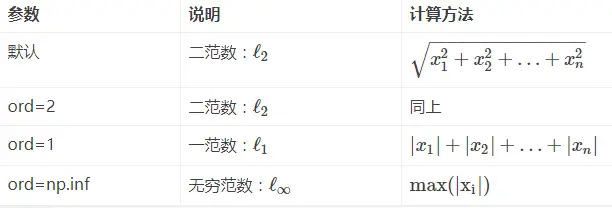
例子
- 向量
>>> import numpy as np
>>> x=np.array([1,2,3,4])
>>> np.linalg.norm(x) #默认是二范数,所有向量元素绝对值的平方和再开方
5.477225575051661
>>> np.sqrt(1**2+2**2+3**2+4**2)
5.477225575051661
>>> np.linalg.norm(x,ord=1) #所有向量元素绝对值之和
10.0
>>> 1+2+3+4
10
>>> np.linalg.norm(x,ord=np.inf) #max(abs(x_i)),所有向量元素绝对值中的最大值
4.0
>>> np.linalg.norm(x,ord=-np.inf) #min(abs(x_i)),所有向量元素绝对值中的最小值
1.0
- 矩阵
>>> import numpy as np
>>> x=np.arange(12).reshape(3,4)
>>> x
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> np.linalg.norm(x) #默认是二范数,最大特征值的算术平方根
22.494443758403985
>>> np.linalg.norm(x,ord=1) #所有矩阵列向量绝对值之和的最大值
21.0
>>> x
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> np.linalg.norm(x,ord=1,axis=1) #行向量的一范数
array([ 6., 22., 38.])
>>> np.linalg.norm(x,ord=2,axis=1) #行向量的二范数
array([ 3.74165739, 11.22497216, 19.13112647])
>>> np.linalg.norm(x,ord=1,axis=1,keepdims=True) #结果仍然是个矩阵
array([[ 6.],
[22.],
[38.]])
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号,不定期分享干货
作者:数据人阿多
背景
由于研发部门给的数据是 csv 文件,业务人员一般都是熟悉 excel 文件,为了方便查看数据,因此需要写个程序,把 csv 文件转换为 excel 文件,由于是经常使用,小编的脚本程序,写成了在命令行中使用的方式
业务人员直接打开 csv 文件会乱码,因excel 默认的编码是 GB2312,所以会乱码
完整脚本
为了方便在命令行中使用,该脚本使用了 argparse 库,如果对该库不是很懂,可以查看相关资料,进行学习
"""
===========================
@Time : 2023/2/1 11:19
@File : csv_to_excel.py
@Software: PyCharm
@Platform: Win10
@Author : DataShare
===========================
"""
import pandas as pd
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='csv_to_excel')
parser.add_argument('--input_file', '-in', type=str, required=True, help='csv文件')
parser.add_argument('--output_file', '-out', type=str, required=False, default=None, help='excel文件')
args = parser.parse_args()
data = pd.read_csv(args.input_file, sep=',', dtype='str', quotechar='"', header=0)
print('csv文件行数为:', len(data)) # 判断数据行数是否一致,防止不可见字符,例如:回车 等
if args.output_file is not None:
if args.output_file.endswith('.xlsx'):
output_file_converted = args.output_file
else:
output_file_converted = args.output_file + '.xlsx'
else:
output_file_converted = args.input_file.split('.csv')[0] + '.xlsx'
# 这是由于Excel单个工作表限制URL类型数据量为65530,超出的部分会被舍弃
# 只要将strings_to_urls自动转换功能关闭就好了
writer = pd.ExcelWriter(output_file_converted, engine='xlsxwriter',
engine_kwargs={'options': {'strings_to_urls': False}})
data.to_excel(writer, index=False)
writer.close()
print('数据转换完成')
使用教程
前提条件:
- 需要把以上的完整脚本,复制下来保存为
csv_to_excel.py文件 - 本机安装了python,并且在命令行中可以直接使用
使用教程
最好把 csv_to_excel.py 文件与将要转换的 csv 文件放到一个文件夹中
用法1: 只指定需要转换的 csv 文件,转换后的结果 excel 文件,默认与 csv 文件同名,且保存在同一个文件夹里面
python csv_to_excel.py -in test.csv
#python csv_to_excel.py --input_file test.csv
用法2: 指定需要转换的 csv 文件,同时指定输出的 excel 结果文件名
python csv_to_excel.py -in test.csv -out test_convert.xlsx
#python csv_to_excel.py --input_file test.csv --output_file test_convert.xlsx
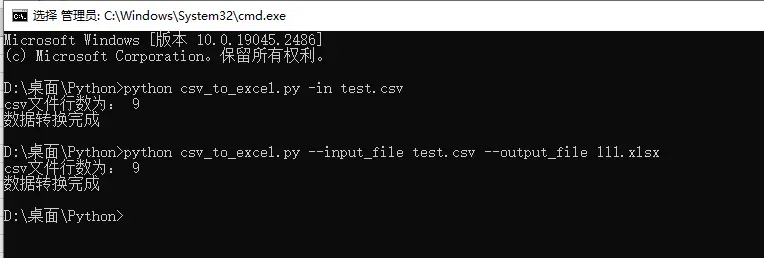
历史相关文章
- 对csv文件,又get了新的认知
- Python 处理Excel文件为了通用原则,建议用openpyxl库
- Python pandas在读取csv文件时(linux与windows之间传输),数据行数不一致的问题
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
经过移动互联网的蓬勃发展后,促使数字化也进入大众视野,现阶段各个行业能数字化的基本都数字化,至于数字化后好用不好用是另一回事了
数字化就会涉及到数据处理、数据存放等,紧接着引出了数据安全,数据存放时是否需要加密的问题,大型公司数据存放在服务器时,敏感数据基本都是加密后存放
小编这里大概梳理了几个常用的加密算法,本篇文章重点是实际使用,不介绍算法原理,算法原理相对比较深奥,涉及到密码学,小编也研究不懂
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.5
DES、AES加密算法需要利用三方包 pycryptodome
#需要先安装三方包
#pip install pycryptodome
import Crypto
print(Crypto.__version__) #3.20.0
不同的加解密算法
MD5
MD5是单向加密算法,加密后无法解密,MD5重复(碰撞)概率:三百万亿亿亿亿 分之一 $$(\frac{1}{16})^{32}=(\frac{1}{2})^{128}$$ $$2^{128}=340 2823 66920938 46346337 46074317 68211456$$
import hashlib
data='DataShare 中国'
print(hashlib.md5(data.encode(encoding='UTF-8')).hexdigest())
#6c066bb026f2529e9694420b70b78df2
MD5,加盐
加盐可能初听起来比较奇怪,小编个人感觉应该是翻译不够直白,应该是对数据先进行一些加工,再进行MD5加密
import hashlib
data='DataShare 中国'
salt='12345'
data_salt=data+salt
print(hashlib.md5(data_salt.encode(encoding='UTF-8')).hexdigest())
#2a0e91ca52ec8da75171e9165fc26e28
DES
DES是一种对称加密,所谓对称加密就是加密与解密使用的秘钥是一个,数据加密完成后能解密还原
英语:Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法
ECB模式
- 加密
from Crypto.Cipher import DES
import binascii
secret='DataShar' #秘钥必须为8字节
data='DataShare 中国'
#创建一个des对象 ,DES.MODE_ECB 表示模式是ECB模式
des = DES.new(bytes(secret, encoding="utf-8"),AES.MODE_ECB)
data_encrypt_bin=des.encrypt(bytes(data, encoding="utf-8"))
print(binascii.b2a_hex(data_encrypt_bin).decode())
#0ef72f2ea2eeaff395f2f75fbb76e124
- 解密
from Crypto.Cipher import DES
import binascii
secret='DataShar' #秘钥必须为8字节
data_encrypt='0ef72f2ea2eeaff395f2f75fbb76e124'
data_encrypt_bin=binascii.unhexlify(bytes(data_encrypt, encoding="utf-8"))
#创建一个des对象 ,DES.MODE_ECB 表示模式是ECB模式
des = DES.new(bytes(secret, encoding="utf-8"),AES.MODE_ECB)
print(des.decrypt(data_encrypt_bin).decode())
#DataShare 中国
CBC模式 该模式需要一个偏移量,也就是初始化的值,对数据进行初始化处理,类似MD5加盐
- 加密
from Crypto.Cipher import DES
import binascii
secret='DataShar' #秘钥必须为8字节
data='DataShare 中国'
iv = b'12345678' #偏移量,bytes类型,必须为8字节
des = DES.new(bytes(secret, encoding="utf-8"),DES.MODE_CBC,iv) #创建一个des对象
data_encrypt_bin=des.encrypt(bytes(data, encoding="utf-8"))
print(binascii.b2a_hex(data_encrypt_bin).decode())
#8d5e64e6a20638158d6a2fe43f0cc23d
- 解密
from Crypto.Cipher import DES
import binascii
secret='DataShar' #秘钥必须为8字节
iv = b'12345678' #偏移量,bytes类型,必须为8字节
data_encrypt='8d5e64e6a20638158d6a2fe43f0cc23d'
data_encrypt_bin=binascii.unhexlify(bytes(data_encrypt, encoding="utf-8"))
des = DES.new(bytes(secret, encoding="utf-8"),DES.MODE_CBC,iv) #创建一个des对象
print(des.decrypt(data_encrypt_bin).decode())
#DataShare 中国
AES
高级加密标准(英语:Advanced Encryption Standard,缩写:AES),是美国联邦政府采用的一种区块加密标准,这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用
AES是一种对称加密,所谓对称加密就是加密与解密使用的秘钥是一个,数据加密完成后能解密还原
ECB模式
- 加密
from Crypto.Cipher import AES
import binascii
secret='DataShareDataSha' #秘钥必须为16字节或者16字节倍数的字节型数据
data='DataShare 中国'
#创建一个aes对象 ,AES.MODE_ECB 表示模式是ECB模式
aes = AES.new(bytes(secret, encoding="utf-8"),AES.MODE_ECB)
data_encrypt_bin=aes.encrypt(bytes(data, encoding="utf-8"))
print(binascii.b2a_hex(data_encrypt_bin).decode())
#bae24aeaa8f1258a97edd935ed4ca495
- 解密
from Crypto.Cipher import AES
import binascii
secret='DataShareDataSha' #秘钥必须为16字节或者16字节倍数的字节型数据
data_encrypt='bae24aeaa8f1258a97edd935ed4ca495'
data_encrypt_bin=binascii.unhexlify(bytes(data_encrypt, encoding="utf-8"))
#创建一个aes对象 ,AES.MODE_ECB 表示模式是ECB模式
aes = AES.new(bytes(secret, encoding="utf-8"),AES.MODE_ECB)
print(aes.decrypt(data_encrypt_bin).decode())
#DataShare 中国
CBC模式 该模式需要一个偏移量,也就是初始化的值,对数据进行初始化处理,类似MD5加盐
- 加密
from Crypto.Cipher import AES
import binascii
secret='DataShareDataSha' #秘钥必须为16字节或者16字节倍数的字节型数据
data='DataShare 中国'
iv = b'0123456789abcdef' #偏移量,bytes类型,必须为16字节
aes = AES.new(bytes(secret, encoding="utf-8"),AES.MODE_CBC,iv) #创建一个aes对象
data_encrypt_bin=aes.encrypt(bytes(data, encoding="utf-8"))
print(binascii.b2a_hex(data_encrypt_bin).decode())
#6866c9639f59d3485c50d30ec383b70b
- 解密
from Crypto.Cipher import AES
import binascii
secret='DataShareDataSha' #秘钥必须为16字节或者16字节倍数的字节型数据
iv = b'0123456789abcdef' #偏移量,bytes类型,必须为16字节
data_encrypt='6866c9639f59d3485c50d30ec383b70b'
data_encrypt_bin=binascii.unhexlify(bytes(data_encrypt, encoding="utf-8"))
aes = AES.new(bytes(secret, encoding="utf-8"),AES.MODE_CBC,iv) #创建一个aes对象
print(aes.decrypt(data_encrypt_bin).decode())
#DataShare 中国
历史相关文章
- Python 标准库之pathlib,路径操作
- Python 记录re正则模块,方便后期查找使用
- Python 内建模块 bisect,数组二分查找算法
- Python 标准库heapq,堆数据结构操作详解
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在给业务生成自动化Excel报表时,需要把数据库里面的数据进行处理,然后放到Excel里面并进行美化,用邮件进行发送,满足业务的需求。但是这些自动化程序一般都是部署在Linux服务器上定期进行发送邮件,这样就需要在Linux环境下生成Excel文件,之前有文章介绍过 xlwings库,但是该库不支持Linux,经过查找相关的资料后,openpyxl库 可以满足要求。
xlwings只支持Windows 和 Mac系统
openpyxl 三个系统都支持,该库是基于操作XML文件而支持操作Excel文件,支持Excel2010版之后的所有Excel文件
额外话题: 虽然现在一些公司都用BI工具,但是这些BI报表建立后,后期进行维护时需要很大的成本,比如:BI系统有升级、数据库字段有变化、更有甚者创建BI报表的员工离职等等,有的公司可能用的还是Tableau、帆软BI等第三方的工具,更新不及时,无法使用到最新的功能。 个人感觉从数据库里面查询数据,并实现可视化放到Excel文件里面是一个不错的选择。当然一些大厂有充足的人力除外,一些中小型公司用这种方法是最经济、最实用且高效的
深度剖析Excel文件的构成
上面说到openpyxl库是基于操作XML文件而支持操作Excel文件,那么XML文件和Excel有什么关系呢?下面进行介绍:
现阶段公司里面基本用的都是office2013版之后的,文件后缀是 .xlsx ,可以把后缀修改为 .zip ,然后进行解压后,可以发现文件夹里面有一些XML文件,其实Excel就是由XML文件与其他一些文件联合组成的一个文件包,然后经过Excel解析后,呈现在用户面前的是一个可编辑的界面,如果理解了这些,就可以发现微软确实比较牛,他们的产品经理是多么厉害。
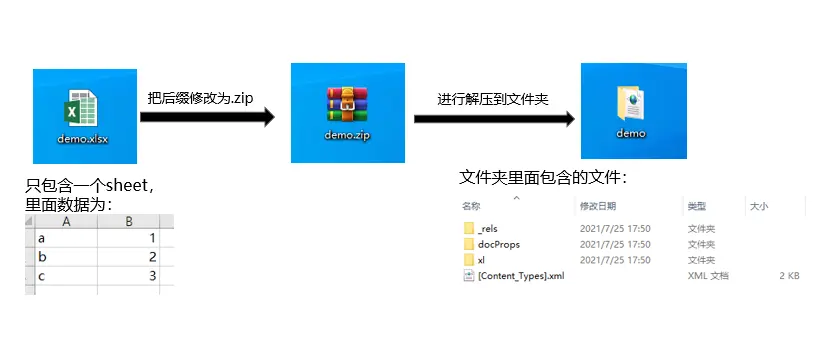
/demo/xl/worksheets/sheet1.xml 文件内容,B1到B3单元格存放的是1-3

而A1到A3单元格放的是0-2值来代替,真实的值可以在/demo/xl/sharedStrings.xml文件里面查到,这里微软用了映射的方法,放入的是数值,类似pandas里面的category类型一样,可以减少内存占用

openpyxl介绍
该库是基于PHPExcel,也就是PHP操作Excel文件的库,PHP是后端的开发语言,一般大都是部署在Linux服务器 文档:官方文档 https://openpyxl.readthedocs.io/en/stable/index.html,里面有很详细的介绍,目前只有英文版文档,可以配合百度翻译进行查阅
该库也一直有更新,最近的一次更新时间为:2021年3月9日,python里面建议用一直有更新的库
用 openpyxl 可以直接生产包含XML文件的文件包,也就是Excel文件,该库也就是按照微软的规则把数据写入XML文件,进而可以生产Excel,达到了操作Excel的目的
使用案例
官方文档:https://openpyxl.readthedocs.io/en/stable/index.html里面有很详细的使用介绍,这里只展示一些自己用过的功能,一下只是部分代码:
from openpyxl import load_workbook
from openpyxl.styles import Font,Border,Side,Alignment,PatternFill
#加载excel文件
workbook = load_workbook(filename = path_excel)
#字体、边框、加粗、居中对齐、格式化设置
bd=Side(border_style='thin', color="A6A6A6")
for row_num,key in enumerate(result_index):
worksheet.cell(row_num+2, 1, key).font = Font(name='微软雅黑',bold=False, size=10,color='000000')
worksheet.cell(row_num+2, 1, key).border = Border(left=bd, top=bd, right=bd, bottom=bd)
worksheet.cell(row_num+2, 1, key).alignment = Alignment(horizontal='center', vertical='center')
if '率' in key:
worksheet.cell(row_num+2, 2).number_format='0.0%'
if key=='对话轮次':
worksheet.cell(row_num+2, 2).number_format='0.0'
#单元格填充颜色
worksheet.cell(1, 1, value).fill = PatternFill(fill_type='solid',fgColor="538DD5")
#设置行高、列宽
worksheet.row_dimensions[1].height=29
worksheet.column_dimensions['A'].width=18
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在网上搜集到的多线程资料都是一些概念介绍,而没有真实的案例告诉读者怎么真实来使用,下面就一个真实的使用场景来介绍多线程。
以下为一些概念引用:
在非python环境中,单核情况下,同时只能有一个任务执行。多核时可以支持多个线程同时执行。但是在python中,无论有多少个核同时只能执行一个线程。究其原因,这就是由于GIL(全局解释器)的存在导致的。
GIL的全称是全局解释器,来源是python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以把GIL看做是“通行证”,并且在一个python进程之中,GIL只有一个,拿不到通行证的线程,就不允许进入CPU执行。GIL只在cpython中才有,因为cpython调用的是c语言的原生线程,所以他不能直接操作cpu,而只能利用GIL保证同一时间只能有一个线程拿到数据。
python针对不同类型的代码执行效率也是不同的: 1、CPU密集型代码(各种循环处理、计算等),在这种情况下,由于计算工作多,ticks技术很快就会达到阀值,然后触发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。 2、IO密集型代码(文件处理、网络爬虫等设计文件读写操作),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序的执行效率)。所以python的多线程对IO密集型代码比较友好。
主要要看任务的类型,我们把任务分为I/O密集型和计算密集型,而多线程在切换中又分为 I/O切换 和 时间切换(一个线程执行一段时间后,再切换到另外一个线程)。如果任务属于是I/O密集型,若不采用多线程,我们在进行I/O操作时,势必要等待前面一个I/O任务完成,后面的I/O任务才能进行,在这个等待的过程中,CPU处于等待状态,这时如果采用多线程的话,刚好可以切换到进行另一个I/O任务。这样就刚好可以充分利用CPU避免CPU处于闲置状态,提高效率。但是如果多线程任务都是计算型,CPU会一直在进行工作,直到一定的时间后采取多线程时间切换的方式进行切换线程,此时CPU一直处于工作状态,此种情况下并不能提高性能,相反在切换多线程任务时,可能还会造成时间和资源的浪费,导致效能下降。这就是造成上面两种多线程结果不能的解释。
结论:I/O密集型任务,建议采取多线程;对于计算密集型任务,python此时就不适用了。
现实需求
为了解决读取文件、写入文件的I/O密集型任务,现在需要三个线程:
1、读取文件数据的线程-----读线程
2、对读取文件数据进行操作的线程-----数据处理线程
3、把处理结果再写入文件的线程-----写线程
这样就可以解决读取数据等待,写入数据等待的过程
数据准备
建立number.txt,里面放置1~50数字,每行一个
 目的:从number.txt每次读取一行数据,对数据进行处理后,再写入number_write.txt(程序自动建立)
目的:从number.txt每次读取一行数据,对数据进行处理后,再写入number_write.txt(程序自动建立)
代码
# -*- coding:UTF-8 -*-
# @Time : 2020/7/19 15:38
# @File : 多线程案例.py
# @Software: PyCharm
# @Platform: Win10
# @Author: data_duo
import threading
import os
import time
import queue
def read_txt(path_file_txt):
with open(path_file_txt, 'r') as file:
while True:
data = file.readline().strip()
if data:
while True: # 确保读取的数据一定存入workQueue_read队列,防止队列满了放不下
if not workQueue_read.full():
workQueue_read.put(data)
print(
'read_txt线程给workQueue_read队列存入:{} \n'.format(data),
end='',
flush=True)
break
else:
pass
else:
print('退出read_txt线程', end='\n', flush=True)
break
def handle():
count = 0
while True:
if not workQueue_read.empty():
data = workQueue_read.get()
print(
'handle线程从workQueue_read队列获取:{} \n'.format(data),
end='',
flush=True)
data = int(data) + 1
data = str(data - 1)
time.sleep(1)
count = 0 # 需要重置
while True: # 确保数据存入workQueue_write 队列,防止队列满了放不下
if not workQueue_write.full():
workQueue_write.put(data)
print(
'handle线程给workQueue_write队列存入:{} \n'.format(data),
end='',
flush=True)
break
else:
pass
else:
if count < 5: # 等待workQueue_read队列有数据,一共5次等待机会
count += 1
time.sleep(1)
pass
else:
if thread_read.is_alive():
pass
count = 0 # 需要重置,再次计时
else:
print('退出handle线程 \n', end='', flush=True)
break
def write_txt(path_file_txt):
count = 0
with open(path_file_txt, 'w+') as file:
while True:
if not workQueue_write.empty():
data = workQueue_write.get()
print(
'write_txt线程从workQueue_write队列获取:{} \n'.format(data),
end='',
flush=True)
file.write(data)
file.write('\n')
print('write_txt线程写入数据:{} \n'.format(data), end='', flush=True)
count = 0 # 需要重置,再次计时
else:
if count < 5: # 确保handle线程处理完毕,把数据存入workQueue_write队列
count += 1
time.sleep(1)
pass
else:
if thread_handle.is_alive():
pass
count = 0 # 需要重置,再次计时
else:
print('退出写线程 \n', end='', flush=True)
break
if __name__ == "__main__":
threads = []
workQueue_read = queue.Queue(20)
workQueue_write = queue.Queue(20)
print('原来总线程数为:{} \n'.format(threading.active_count()), end='', flush=True)
# 创建读取线程
thread_read = threading.Thread(target=read_txt, args=('number.txt',))
thread_read.start()
threads.append(thread_read)
print(
'启动读取线程后,总线程数为:{} \n'.format(
threading.active_count()),
end='',
flush=True)
# 创建操作线程
thread_handle = threading.Thread(target=handle)
thread_handle.start()
threads.append(thread_handle)
print(
'启动操作线程后,总线程数为:{} \n'.format(
threading.active_count()),
end='',
flush=True)
# 创建写入线程
thread_write = threading.Thread(
target=write_txt, args=(
'number_write.txt',))
thread_write.start()
threads.append(thread_write)
print(
'启动写入线程后,总线程数为:{} \n'.format(
threading.active_count()),
end='',
flush=True)
# 等待所有线程完成
for t in threads:
t.join()
print('退出主线程')
运行结果:
原来总线程数为:1
启动读取线程后,总线程数为:2
read_txt线程给workQueue_read队列存入:1
启动操作线程后,总线程数为:3
read_txt线程给workQueue_read队列存入:2
read_txt线程给workQueue_read队列存入:3
...
read_txt线程给workQueue_read队列存入:20
启动写入线程后,总线程数为:4
handle线程从workQueue_read队列获取:1
read_txt线程给workQueue_read队列存入:21
handle线程给workQueue_write队列存入:1
handle线程从workQueue_read队列获取:2
read_txt线程给workQueue_read队列存入:22
write_txt线程从workQueue_write队列获取:1
write_txt线程写入数据:1
handle线程给workQueue_write队列存入:2
handle线程从workQueue_read队列获取:3
...
read_txt线程给workQueue_read队列存入:50
退出read_txt线程
write_txt线程从workQueue_write队列获取:29
...
handle线程给workQueue_write队列存入:50
write_txt线程从workQueue_write队列获取:50
write_txt线程写入数据:50
退出handle线程
退出写线程
退出主线程
历时相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在数据处理过程中,多多少少都会和日期时间打交道,比如在分析数据时,一般需要求各年、各季度、各月、各周的销量等,这些基本都会涉及到日期时间,处理日期时间变量是躲不过的
在这里用的名词术语:日期时间,是一个整体
datetime库介绍
官方文档:https://docs.python.org/zh-cn/3/library/datetime.html
datetime包含的类:
- class datetime.date 日期
- class datetime.time 时间
- class datetime.datetime 日期和时间的结合
- class datetime.timedelta 两个时间之间的间隔
- class datetime.tzinfo 时区
- class datetime.timezone tzinfo 的子类
这里主要介绍在工作中经常使用的:
- class datetime.datetime--------日期时间
- class datetime.timedelta--------时间间隔
常用函数、方法、属性
- class datetime.datetime
- 获取当前时间,结果为:年、月、日、时、分、秒、微秒 1 秒 = 1000毫秒(millisecond) 1毫秒 = 1000微秒(microsecond)
In [1]: import datetime
In [2]: datetime.datetime.now()
Out[2]: datetime.datetime(2021, 1, 25, 16, 56, 56, 992611)
In [3]: type(datetime.datetime.now())
Out[3]: datetime.datetime
- 用指定日期时间创建datetime
In [4]: datetime.datetime(2021,1,1,12,30,00)
Out[4]: datetime.datetime(2021, 1, 1, 12, 30)
In [5]: print(datetime.datetime(2021,1,1,12,30,00))
2021-01-01 12:30:00
- 一般日志文件使用的格式
In [6]: dt=datetime.datetime.now().strftime('%Y%m%d%H%M%S')
In [7]: dt
Out[7]: '20210125171518'
一般创建日志文件代码:
import logging
import datetime
#日志记录
def get_logger():
dt=datetime.datetime.now().strftime('%Y%m%d%H%M%S')
logger = logging.getLogger('model_main.py')
logger.setLevel(level = logging.INFO)
if not os.path.exists('./logs'):
os.mkdir('./logs')
handler = logging.FileHandler(f'./logs/{dt}_model_main.txt',encoding='utf-8')
handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger, handler
- 获取年、月、日等
In [8]: dt = datetime.datetime.now()
In [9]: dt.year
Out[9]: 2021
In [11]: dt.month
Out[11]: 1
In [12]: dt.day
Out[12]: 25
In [13]: dt.hour
Out[13]: 17
In [14]: dt.minute
Out[14]: 20
In [15]: dt.microsecond
Out[15]: 728805
- 解析字符串为日期
strptime:string parse time,官方的符号代表意义:
https://docs.python.org/zh-cn/3/library/datetime.html#strftime-strptime-behavior
In [16]: datetime.datetime.strptime("1/25/2021 17:27:30","%m/%d/%Y %H:%M:%S")
Out[16]: datetime.datetime(2021, 1, 25, 17, 27, 30)
- 把日期格式化为字符串
strftime:string format time 官方的符号代表意义(同上)
In [17]: dt = datetime.datetime.now()
In [18]: dt
Out[18]: datetime.datetime(2021, 1, 25, 17, 33, 25, 952250)
In [19]: datetime.datetime.strftime(dt,"%Y-%m-%d %H:%M:%S")
Out[19]: '2021-01-25 17:33:25'
- class datetime.timedelta
timedelta:time delta 如果学过高等数学的话,那么对delta应该比较熟悉,代表间隔、增量
Delta是第四个希腊字母的读音,其大写为 Δ,小写为 δ。在数学或者物理学中大写的 Δ 用来表示增量符号。 而小写 δ 通常在高等数学中用于表示变量或者符号。 $$Δx = x1 - x2$$
datetime.timedelta 只有 days, seconds 和 microseconds 会保留,其他的单位全部相应会转换为这三个,并且 days, seconds, microseconds 会经标准化处理以保证表达方式的唯一性:
0 <= microseconds < 1000000
0 <= seconds < 360024 (一天的秒数)*
-999999999 <= days <= 999999999
- 两个时间相减生成timedelta
In [20]: dt1 = datetime.datetime(2020,12,5,11,12,13)
In [21]: dt2 = datetime.datetime(2021,1,15,12,30,31)
In [22]: dt2 - dt1
Out[22]: datetime.timedelta(days=41, seconds=4698)
- 两个时间相隔的天数
在数据分析中,有时业务要求前后半年时间内都算正常这样的需求,那么就可以用这种方式来解决
In [20]: dt1 = datetime.datetime(2020,12,5,11,12,13)
In [21]: dt2 = datetime.datetime(2021,1,15,12,30,31)
In [23]: dt_delta = dt1 - dt2
In [24]: dt_delta
Out[24]: datetime.timedelta(days=-42, seconds=81702)
In [25]: dt_delta.days
Out[25]: -42
In [26]: abs(dt_delta.days)
Out[26]: 42
- 用timedelta类来创建
In [27]: datetime.timedelta(days=50,seconds=27,microseconds=10,milliseconds=29000,minutes=5,hours=8,weeks=2)
Out[27]: datetime.timedelta(days=64, seconds=29156, microseconds=10)
In [28]: datetime.timedelta(10,10,10)
Out[28]: datetime.timedelta(days=10, seconds=10, microseconds=10)
- 一个日期加上或减去timedelta增量
一个时间点加上或减去一个timedelta增量结果还是一个时间点
In [29]: dt = datetime.datetime.now()
In [30]: dt_delta = datetime.timedelta(days = 1)
In [31]: dt + dt_delta
Out[31]: datetime.datetime(2021, 1, 26, 18, 21, 30, 27141)
In [32]: dt - dt_delta
Out[32]: datetime.datetime(2021, 1, 24, 18, 21, 30, 27141)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
本篇文章为小编翻译文章,小编在查找资料时看到的一篇文章,看了后感觉不错,就翻译过来,供大家参考学习
文章原文地址:
https://www.slingacademy.com/article/python-aiohttp-how-to-download-files-using-streams/
Overview 概述
aiohttp 是一个现代库,为Python提供异步(协程)HTTP客户端和服务器功能。流是一种分块处理数据的方式,无需一次将整个文件加载到内存中,这对于下载大文件或同时处理多个请求非常有用。
可以通过以下步骤下载带有aiohttp流的文件(尤其是几百MB或更多的大文件):
-
创建一个
aiohttp.ClientSession对象,它表示用于发出HTTP请求的连接池(客户端会话,用于发送不同的HTTP请求) -
使用
session.get方法向文件URL发送get请求,并获得aiohttp.ClientResponse对象,表示来自服务器的响应 -
使用
response.content属性访问aiohttp.StreamReader对象,它是用于读取响应主体的流 -
使用
stream.read或stream.readany方法从流中读取数据块,并将其写入本地的文件中 -
完成后关闭响应和会话对象(这可以通过使用
async with语句自动完成)
上面说的这么多,可能让你困惑且难以理解,让我们来看看下面的例子以获得更清晰的理解
Complete Example 完整示例
假如我们要同时下载两个文件,一个文件是CSV,另一个是PDF
CSV文件的URL:https://api.slingacademy.com/v1/sample-data/files/student-scores.csv
PDF文件的URL:https://api.slingacademy.com/v1/sample-data/files/text-and-table.pdf
完整的代码(带说明)
在运行以下代码时,aiohttp 建议更新为最新的版本,否则可能报错
# SlingAcademy.com
# This code uses Python 3.11.4
import asyncio
import aiohttp
# This function downloads a file from a URL and saves it to a local file
# The function is asynchronous and can handle large files because it uses aiohttp streams
async def download_file(url, filename):
async with aiohttp.ClientSession() as session:
print(f"Starting download file from {url}")
async with session.get(url) as response:
assert response.status == 200
with open(filename, "wb") as f:
while True:
chunk = await response.content.readany()
if not chunk:
break
f.write(chunk)
print(f"Downloaded {filename} from {url}")
# This function downloads two files at the same time
# 同时下载两个文件
async def main():
await asyncio.gather(
# download a CSV file
download_file(
"https://api.slingacademy.com/v1/sample-data/files/student-scores.csv",
"test.csv",
),
# download a PDF file
download_file(
"https://api.slingacademy.com/v1/sample-data/files/text-and-table.pdf",
"test.pdf",
),
)
# Run the main function
asyncio.run(main())
运行的输出:
Starting download file from https://api.slingacademy.com/v1/sample-data/files/student-scores.csv
Starting download file from https://api.slingacademy.com/v1/sample-data/files/text-and-table.pdf
Downloaded test.pdf from https://api.slingacademy.com/v1/sample-data/files/text-and-table.pdf
Downloaded test.csv from https://api.slingacademy.com/v1/sample-data/files/student-scores.csv
下载的文件将保存在当前的脚本目录中,test.csv、test.pdf,如下面的屏幕截图所示:
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
需要把txt文件数据导入mysql数据库,中间需要经过一些数据处理,在经过相关查找后,pandas自带的to_sql(),可以实现把DataFrame直接导入数据库。
虽然mysql有其他的方式导入数据,但是在导入前需要对数据进行一些处理,这些任务无法完成,所以可以借助python来一步实现所有需求。
pandas在处理表格数据有很多优点:API多比较方便、速度快;可循环每行,对每个值进行处理;也可对整列进行处理等
在导入数据库时用的是如下API:
Pandas.DataFrame.to_sql()
参数介绍及注意事项
官方文档: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
常用参数:
-
name:
导入到mysql时表的名字
如果mysql里面已经用CREATE TABLE创建好了表,那么就是该表名字
如果mysql没有创建好表,那么可以自己起一个合适的表名 -
con:
数据库连接,需要安装sqlalchemy库,目前仅支持sqlalchemy库创建的连接,pymysql库创建的连接不支持
engine = create_engine("mysql+pymysql://root:z123456@127.0.0.1:3306/routeapp?charset=utf8")
#SQLALCHEMY_DATABASE_URI = '%s+%s://%s:%s@%s:%s/%s' % (DB_TYPE, DB_DRIVER, DB_USER,DB_PASS, DB_HOST, DB_PORT, DB_NAME)
-
if_exists:以下三个选项,是如果数据库里面已经存在该表的意思
"fail":直接报错,不再操作,类似mysql创建表时的IF NOT EXISTS才创建表
"replace":先删除该表,然后再创建
"append":直接在表后面添加数据 -
index:bool
是否把DataFrame的索引列写入表中 -
index_label:
如果要把DataFrame的索引列写入表中,那么需要给出该索引列的名字,如果没给的话,那就会用DataFrame的列索引名
注意事项:
con 参数一定要仔细核对,否则数据库会连接失败,可参照上面给出的例子按自己的实际数据库位置进行更改
案例
首先电脑上已安装:mysql软件、sqlalchemy库、pandas库
现在有一些城市之间的火车车次信息,需要导入数据库
import pandas as pd
data=pd.read_table('./data_pandas.txt')
data.head()
假如数据库里面已经创建好该表,并且已经指定好各列的数据类型,现在只需把数据导入到里面
CREATE TABLE IF NOT EXISTS train (
start_city VARCHAR (100) NOT NULL COMMENT '始发城市',
start_city_id int COMMENT '始发城市id',
end_city VARCHAR (100) NOT NULL COMMENT '到达城市',
end_city_id int COMMENT '到达城市id',
train_code VARCHAR (20) NOT NULL COMMENT '车次',
arrival_time VARCHAR (20) NOT NULL COMMENT '到达时间',
departure_time VARCHAR (20) NOT NULL COMMENT '出发时间',
run_time INT NOT NULL COMMENT '运行时间(分钟)',
P1 FLOAT COMMENT '硬座票价',
P2 FLOAT COMMENT '软座票价',
P3 FLOAT COMMENT '硬卧票价',
P4 FLOAT COMMENT '软卧票价',
P5 FLOAT COMMENT '商务座票价',
P6 FLOAT COMMENT '一等座',
P7 FLOAT COMMENT '二等座'
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '城市之间火车信息';
借助sqlalchemy库来导入数据
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:z123456@127.0.0.1:3306/routeapp?charset=utf8")
#SQLALCHEMY_DATABASE_URI = '%s+%s://%s:%s@%s:%s/%s' % (DB_TYPE, DB_DRIVER, DB_USER,DB_PASS, DB_HOST, DB_PORT, DB_NAME)
with engine.begin() as conn:
data.to_sql(name='routeapp_train_line_tb_new_2',con=conn,if_exists='append',index=False)
这里用with语句可以实现mysql的roallback功能,建议最好用with来导入数据
参考文章
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
小编最近在处理hive表存储大小时,需要对每个表的大小进行排序,因通过 hadoop fs -du -s -h /path/table 命令获取的数据表大小,其结果是展示为人能直观理解的大小,例如 1.1T、1.9G、49.6M 等,如果想对这些表根据存储大小进行降序排列,利用pandas应该如何做呢?
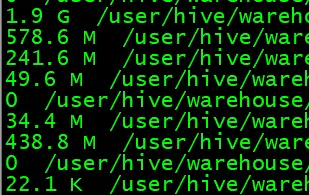
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.5
import pandas as pd
print(pd.__version__)
#2.1.0
测试数据
这里仅列举10行数据,进行演示,小编真实的hive表有几万个
函数概述
在pandas对数据进行排序主要使用 pandas.DataFrame.sort_values 方法
DataFrame.sort_values(by, *,
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last',
ignore_index=False,
key=None)
参数解释:
-
by :str or list of str
用于排序的单个字段 或 多个字段组成的列表 -
axis:“{0 or ‘index’, 1 or ‘columns’}”, default 0
排序时的轴向,0 表示行向排序(一行一行排序),1表示列向排序(一列一列排序),默认是 0,也就是Excel中经常使用的排序 -
ascending:bool or list of bool, default True
升序、降序,默认是升序,也就是True,如果是False,则是降序
注意:该参数需要和 上面的by参数要相对应 -
inplace:bool, default False
是否原地更新排序的数据,默认是False,表示调用该方法后,会返回一个新的数据框 -
kind:{‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’}, default ‘quicksort’
进行排序时,指定的排序算法,默认是quicksort,快速排序算法 -
na_position:{‘first’, ‘last’}, default ‘last’
在排序的数据中,指定NaN的排序位置,默认是排在最后 -
ignore_index:bool, default False
是否要忽略数据的索引,默认是 Fasle,不忽略,使用数据原本的索引 -
key:callable, optional
排序之前使用的函数,该函数需要是矢量化的,也就是传入参数是Series,返回的结果也需要为Series,该函数会逐个用在被排序的字段上
官方文档: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.sort_values.html
完整案例
import pandas as pd
data=pd.read_excel('排序数据.xlsx',sheet_name='排序')
key_type={'T':1,'G':2,'M':3,'K':4}
data.sort_values(by=['大小2','大小1'],
ascending=[True,False],
key=lambda col: col.map(key_type) if col.name=='大小2' else col
)
历史相关文章
- Python pandas 2.0 初探
- Python pandas.str.replace 不起作用
- Python数据处理中 pd.concat 与 pd.merge 区别
- 对比Excel,利用pandas进行数据分析各种用法
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在数据处理过程中经常遇到求两个字典相加(并集),要求相同的键,值相加,不同的键,进行汇集,最后得出一个总的字典,自己可以先进行思考,利用已有的知识,是否马上在心里有解决方法
例如:
d1={'a':1,'b':1}
d2={'b':2,'c':2}
要求的结果:d1+d2={'a':1,'b':3,'c':2}
下面介绍两种方法:
- 自定义函数法
- 利用collections库
方法一
def sum_dict(a,b):
temp = dict()
# dict_keys类似set; | 并集
for key in a.keys() | b.keys():
temp[key] = sum([d.get(key, 0) for d in (a, b)])
return temp
案例:
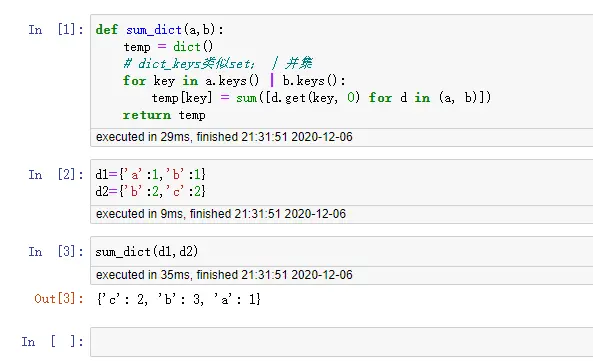
方法二
利用collections库里面的Counter函数进行计数,collections模块是一个很强大的模块,里面有各种扩展的变量容器
如果感兴趣的话可以参考这篇文章 Python-collections模块,里面有详细的使用方法
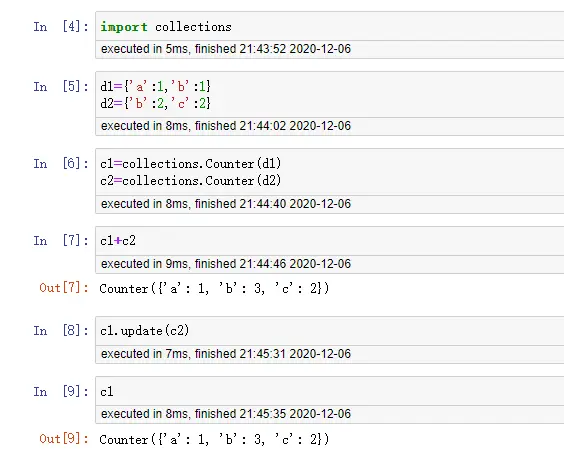
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注 DataShare (同微),不定期分享干货
作者:数据人阿多
问题
请认真思考下这个问题,应该会输出什么呢?
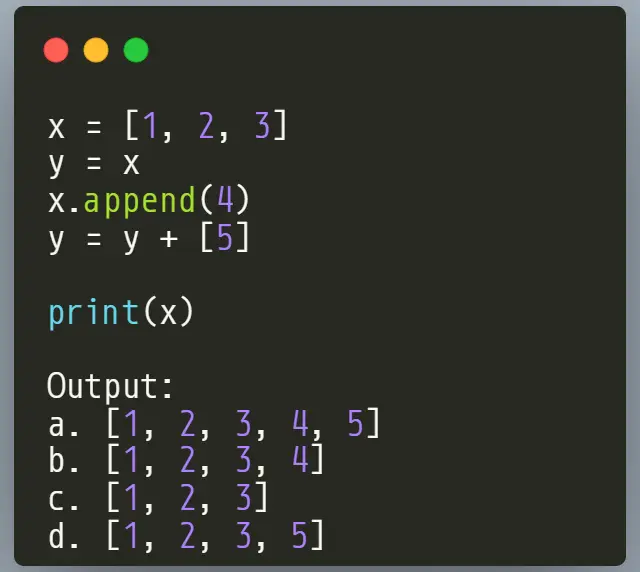
答案
b. [1, 2, 3, 4]
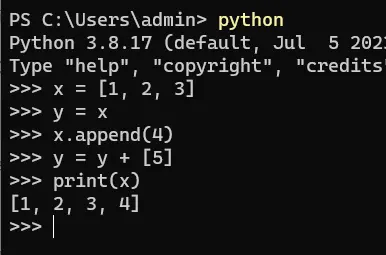
解释
第1行:创建一个列表,变量 x 指向这个列表
x = [1, 2, 3]
第2行:把变量 x 赋值给一个新变量 y,这两个变量同时指向了第1行创建的列表
y = x
第3行:在列表后面追加一个新元素 4,这时 x 和 y 同时也更改为新列表的值
x.append(4)
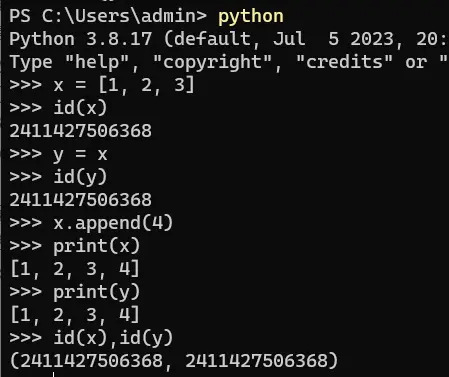
第4行:变量 y 与 新列表 [5] 进行相加运算,会生成一个新列表,这个新列表与原来的列表不一样,变量 y 指向这个新生成的列表
y = y + [5]
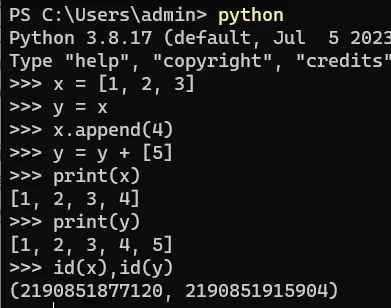
知识点:
列表的 apend 方法是在原有的内存地址后面继续添加新元素,而加号运算符则会产生新的列表,存放在新的内存地址里面
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
字符串格式化的主要使用场景是让变量打印出来,让人看着美观、易于查看。有时会直接print出来;有时会把这些内容写到文件里面,也就是进行日志记录。比如日志文件,设置好格式,后期在查询问题时,就可以快速定位。
字符串格式化就类似于手机APP界面一样,UI、排版设计都是为了使人机交互更加直观,内容让人看起来更美观、更舒服。
字符串格式化方法
- 方法 1
在 python 2.6 之前,利用 百分号% 占位符,进行格式化
>>> name = '张三'
>>> print('哈喽,%s'%name)
哈喽,张三
- 方法 2 ---------- 现阶段使用最多的方法
Python2.6 引入,性能比 % 更强大,字符串的 format 方法
>>> name = '张三'
>>> '哈喽,{}'.format(name)
'哈喽,张三'
- 方法 3 ---------- 推荐使用的方法
为了进一步简化格式化方法,Eric Smith 在2015年提交了 PEP 498 -- Literal String Interpolation 提案。字符串开头加上一个字母 f ,是在 Python3.6 新加入的字符串格式化方法
>>> name = '张三'
>>> f'哈喽,{name}'
'哈喽,张三'
推荐大家用最新的方法
推荐方法常规用法
设定浮点数精度
需要加一个 :(冒号)再加一个 .(英文句号)然后跟着小数点位数最后以f(float)结尾
num = 3.1415926 #山巅一寺一壶酒
print(f'圆周率保留两位小数为:{num:.2f}')
#圆周率保留两位小数为:3.14
数字格式化为百分数
方法与浮点数格式化类似,但是要用%代替结尾的f
a = 1
b = 3
c = a / b
print(f'百分数为:{c:%}')
#百分数为:33.333333%
print(f'百分数保留两位小数为:{c:.2%}')
#百分数保留两位小数为:33.33%
格式化 datetime 对象
支持的格式详见官方文档: https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes
import datetime
now = datetime.datetime.now()
print(f'{now:%Y-%m-%d %H:%M:%S}')
#2021-01-19 16:44:32
字符串前补零
{var:0len} 方法来进行字符串补零,len是最终返回字符串的长度
num = 123
print(f"{num:05}")
#00123
字符串居中
想要实现字符串居中,可以通过 var:^N 的方式。其中var是你想要打印的变量,N是字符串长度。如果N小于var的长度,会打印全部字符串。
test = 'hello world'
print(f'{test:^20}')
# hello world
print(f'{test:*^20}')
#****hello world*****
print(f'{test:^2}')
#hello world
进制转换
print(f'{7:b}')
#111
bases = {"b": "bin",
"o": "oct",
"x": "hex",
"X": "HEX",
"d": "decimal"}
for n in range(1,21):
#print(n)
for base,desc in bases.items():
print(f'{desc}:{n:5{base}}',end=' '*5)
print()
参考文章
- https://miguendes.me/73-examples-to-help-you-master-pythons-f-strings
- https://mp.weixin.qq.com/s/0F06lMbJSqN2msX4bNl2Aw
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
1.全局设置
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
#禁止自动换行(设置为Flase不自动换行,True反之)
pd.set_option('expand_frame_repr', False)
#打开修改时复制机制
pd.set_option("mode.copy_on_write", True)
#打印时显示全部数组信息
np.set_printoptions(threshold=np.inf)
2.画图
#内嵌画图
%matplotlib inline
#单独画图
%matplotlib qt
3.显示
#让一个cell同时有多个输出print
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
每门编程语言都有其独特的用途,目前python在数据科学方面发展的相对比较全面,大家目前也都喜欢使用python来处理数据、做模型开发等。python在数据处理方面离不开 pandas 库,该库在今年的4月3日发布了 2.0版更新,对底层进行了大量的重构以优化性能和稳定性
主要新增功能及优化
1、引擎增加pyarrow
最主要是底层的数据引擎增加了对pyarrow支持(Apache Arrow 内存数据交换格式),pandas之前的底层引擎是numpy,numpy在处理数值型数据时效率很高,但是在处理字符串型的数据时效率比较慢,pyarrow的引入,使字符串的处理效率得到明显提升
2、写入时复制(Copy-on-Write)的优化
当你复制一个pandas对象,如DataFrame或Series,而不是立即创建一个新的数据副本,pandas将创建一个对原始数据的引用(视图),推迟创建一个新的副本,直到你以某种方式修改数据时才创建一个副本,而原数据保持不变,
这可以大大减少内存的使用,提高性能,因为你不需要对数据进行不必要的复制。总的来说,写时拷贝是一种强大的优化技术,可以帮助你更有效地处理大型数据集,并减少内存占用
安装
必须要安装pyarrow库,否则运行时会报错
pip install --upgrade pandas #更新pandas库
pip install pyarrow #安装pyarrow库
测试
测试数据是有12W+行数据
1、加载数据测试
从加载csv数据可以看出,速度有明显的提升,差不多有10倍
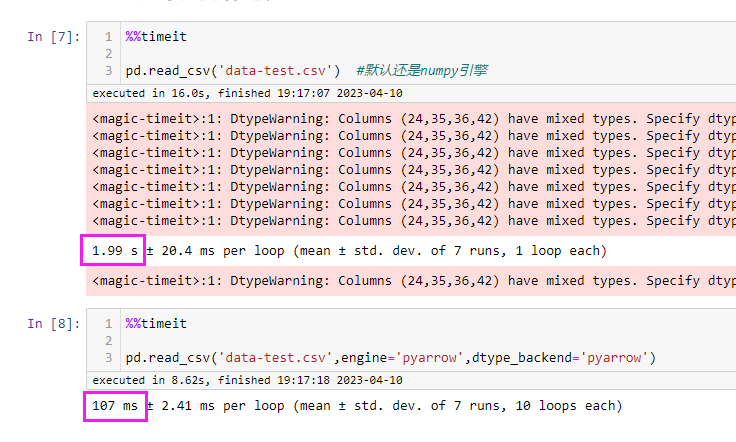
2、字符串处理测试
从字符串处理方面看,速度大约是原来的40倍
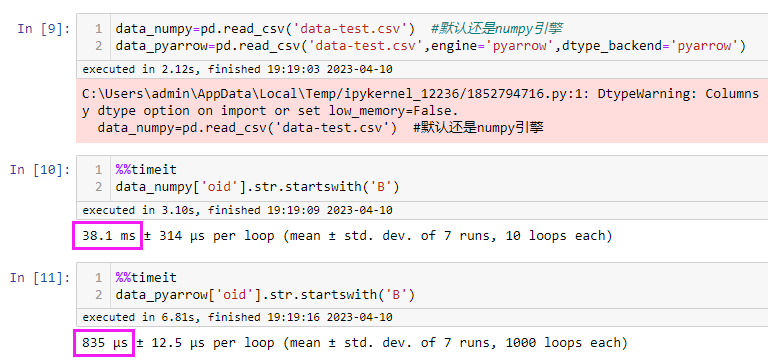
3、修改时复制机制
-
默认该机制是关闭的,修改视图数据时,原始数据也会被修改
-
打开修改时复制机制,修改视图数据时,原始数据保持不变
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近在项目处理数据时,对pandas里面的数据类型进行转换时(astype),产生了一些意外的情况,经过研究,对数据框里面的数据类型,又有了新的认识,分享出来供大家参考学习。
创建模拟数据
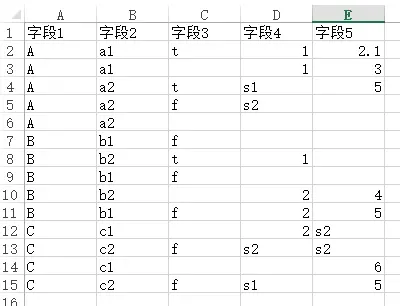
- 假如模拟的数据如上图所示,里面有一些空单元格,下面读取模拟数据
import pandas as pd
import numpy as np
data=pd.read_excel('111.xlsx',sheet_name='astype')
data
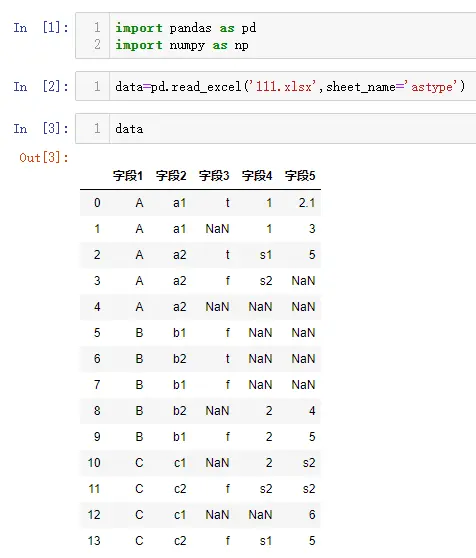
- 查看整体数据类型,可以看出所有的数据类型均为
object,这里的object对应的是python里面的str字符类型
data.dtypes
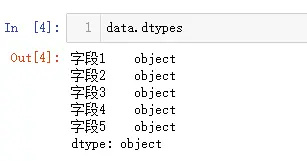
- 查看
字段4每一个数据是什么类型
for i in data['字段4']:
print(i,'\t',type(i))
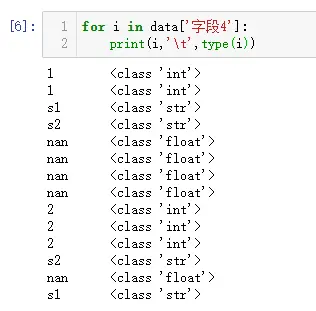
可以看出字段4这一列里面,有str、float、int三种数据类型,这里就可以看出一列里面数据类型可以不同,类似Excel一列,每个单元格可以存放不同类型的数据,和数据库里面一列完全不一样,数据库里面一列数据类型在建表时,已声明类型,只存放一种类型。但是上面在获取整列数据类型时返回的是object,用的是最大的数据类型,能囊括整列的数据类型
如果astype类型强制转换
data['字段4_astype']=data['字段4'].astype('str')
data
for i in data['字段4_astype']:
print(i,'\t',type(i))
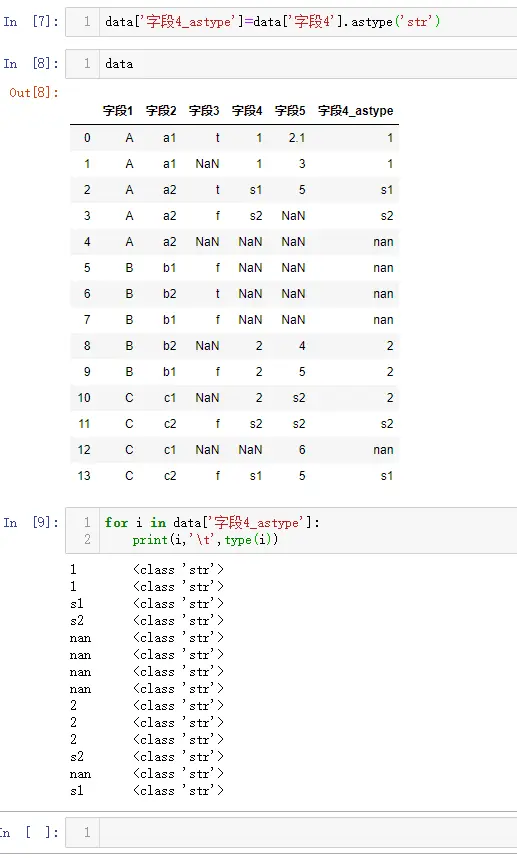
可以看出这里全部转换为str,NaN也会强制转换为字符型nan,不再是np.nan
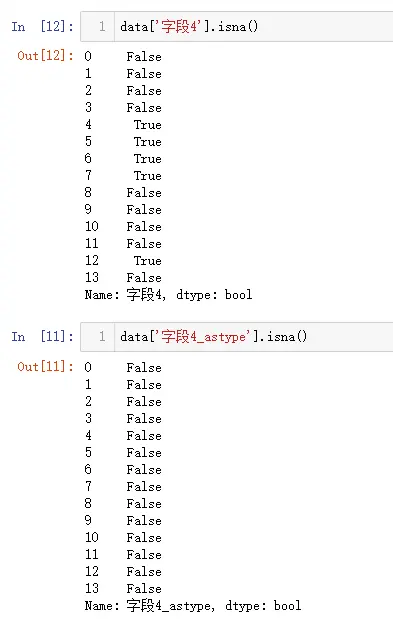
这样的话就出现一个问题,astype是强制把所有的类型都转换为str,而不忽略NaN,要对非NAN进行转换,就需要自定义函数来实现
自定义函数实现非NAN转换类型
def astype_str_notna(df):
'''
传入参数:数据框里面一列 Series
return:转换后的一列 Series
'''
t=[]
for i in df:
if type(i)== float:
if not np.isnan(i):
i=str(int(i))
if type(i)== int:
i=str(i)
t.append(i)
return pd.Series(t)
data['字段4_def']=astype_str_notna(data['字段4'])
data
data['字段4'].isna()
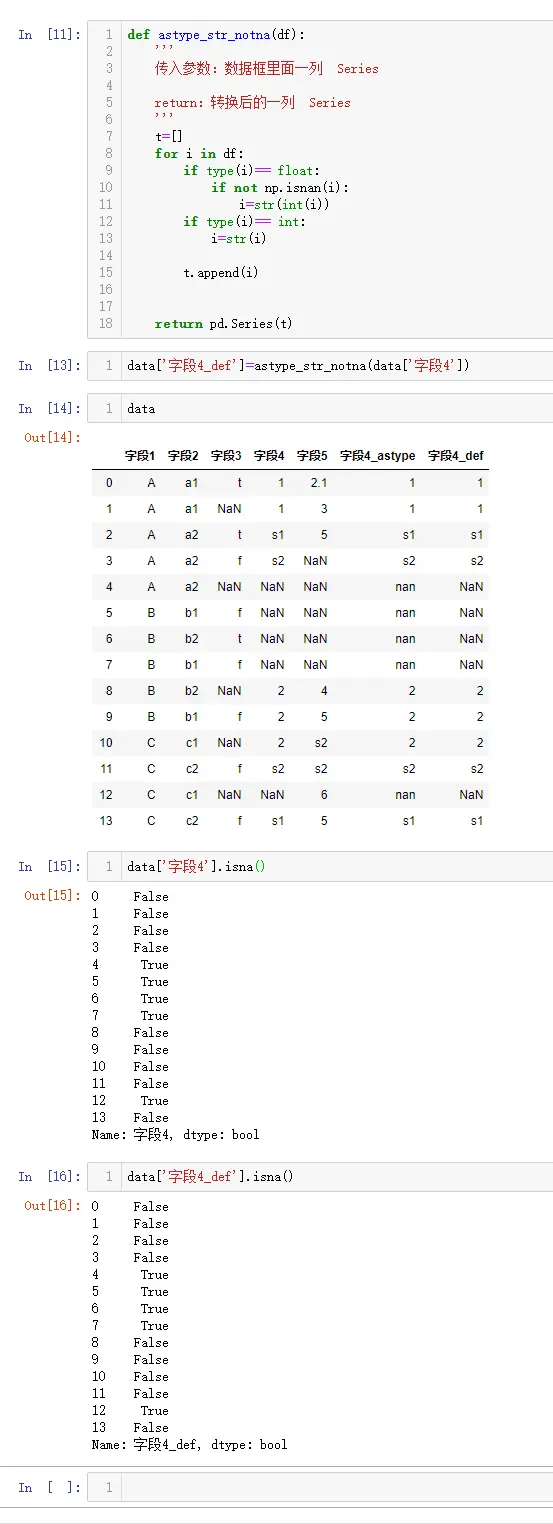
通过自定义函数,可以实现数据类型转换,而忽略NAN,从而达到在数据统计时,不会计算NAN
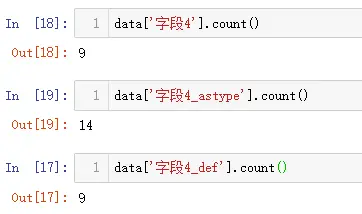
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
数据筛选背景
在处理数据时,我们可能希望从数据库里面筛选出符合特定条件的记录(个案或样本,不同的行业叫法不一样),平常大家对Excel筛选很熟悉,比如从A字段(变量或特征)包含“团队”,B字段大于等于40,筛选出符合这两个条件的记录,如下图所示:

pandas处理
- 正确代码
#加载库
import pandas as pd
import numpy as np
#读取数据
data=pd.read_excel('test.xlsx')
#查看数据类型
data.dtypes
#查看数据前5行
data.head()
#根据条件筛选出数据
data.loc[(data['A'].str.contains('团队')) & (data['B']>=40)]
#data[(data['A'].str.contains('团队')) & (data['B']>=40)] #这两行都可以
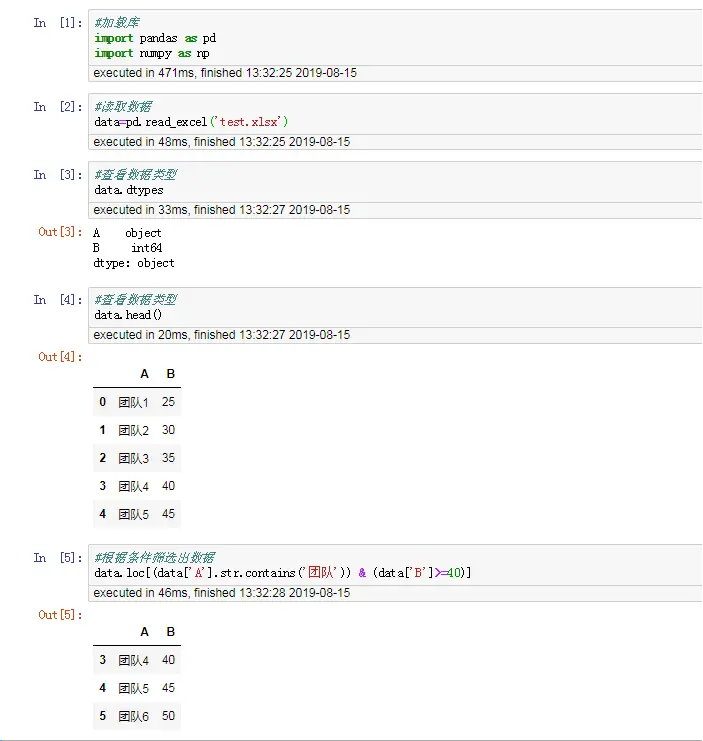
- 错误代码
- 位运算符
&与|,而不是逻辑运算符and与or,两者是有区别的
data.loc[(data['A'].str.contains('团队')) and (data['B']>=40)]
- 缺少括号
(),导致筛选不出数据,但是不报错
data.loc[data['A'].str.contains('团队') & data['B']>=40]
经过多方查找原因,动手实践,这个问题貌似没有帖子仔细进行解释,那这是为什么筛选不出来数据呢,加了括号就可以,可能有同学一下子就明白了,运算符的顺序,对,位运算符&的优先级 高于 比较运算符>=,其实也就是只对后面的条件加上括号即可,但是考虑到逻辑严谨性,最好把所有条件都括起来,详情参考这篇文章Python 3 的运算符及优先级
pandas赋值操作
- 正确代码
注意避免链式操作导致SettingwithCopyWarning ,最详细的解释,请参考这篇文章Pandas 中 SettingwithCopyWarning 的原理和解决方案
#赋值操作
data.loc[(data['A'].str.contains('团队')) & (data['B']>=40),'C']='是'
data
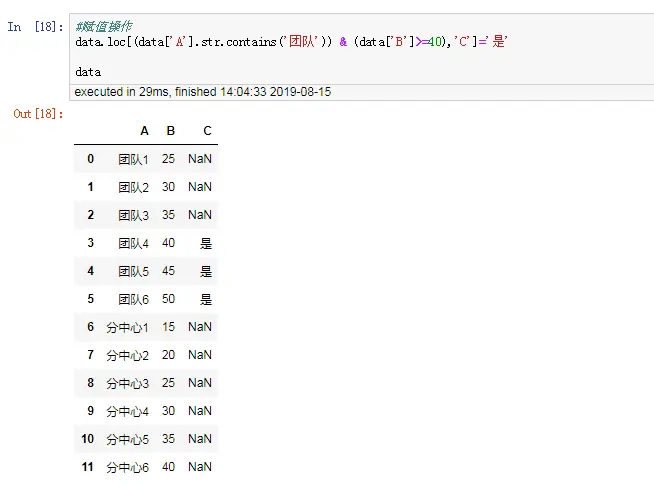
及时原来的数据框里面没有C列变量,但是在赋值时可以直接指定,数据框会自动生成这一列变量
- 错误代码
- 缺少
.loc导致报错提示不可哈希,对这个不是很懂
data[(data['A'].str.contains('团队')) & (data['B']>=40),'C']='是'
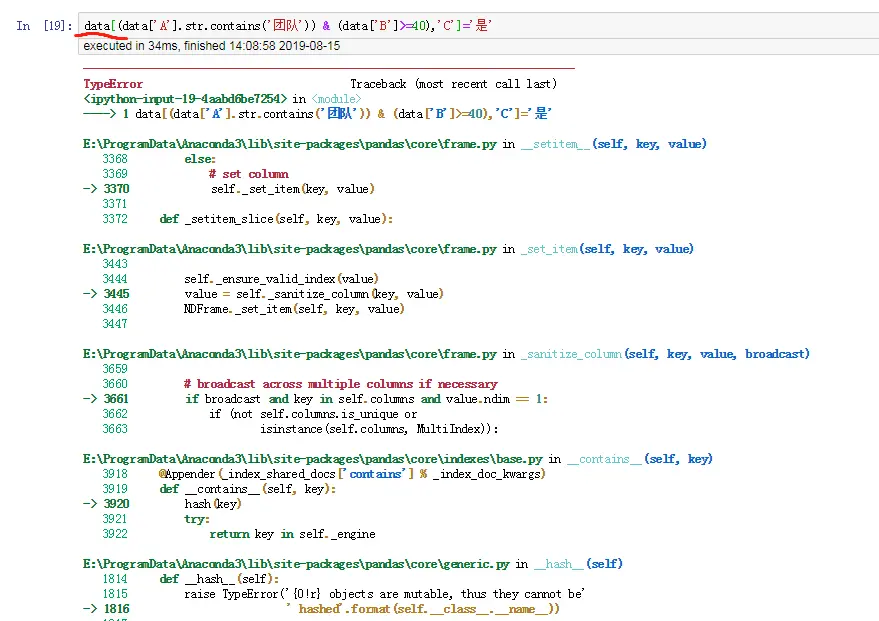 建议为了使代码规范,在根据条件筛选时就把
建议为了使代码规范,在根据条件筛选时就把.loc带上,防止后期出错
- 链式操作,提示
SettingwithCopyWarning
data.loc[(data['A'].str.contains('团队')) & (data['B']>=40)]['C']='是'
data
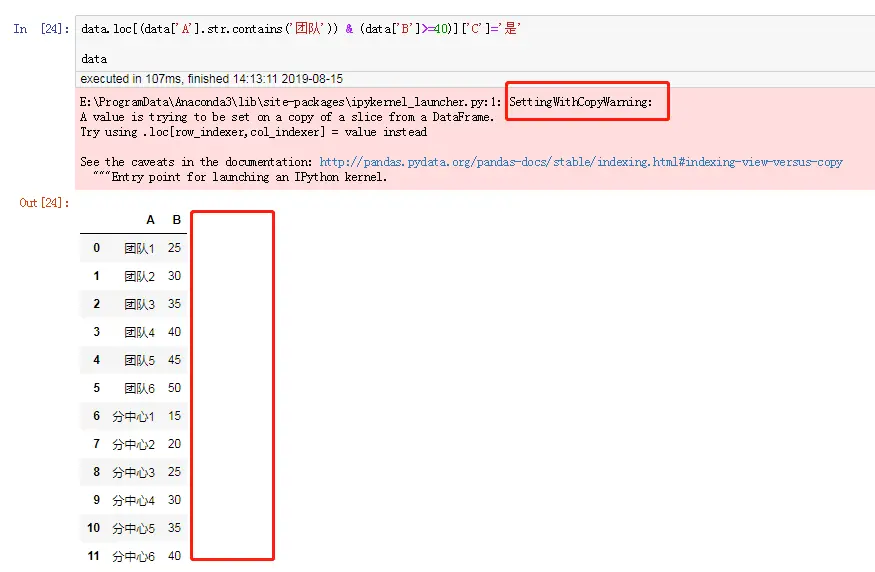
为什么会出现这种情况,请详细阅读这篇文章Pandas 中 SettingwithCopyWarning 的原理和解决方案
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
在数据处理时,有时需要对数据进行分列,类似于Excel里面的分列功能,这个在pandas里面也可以实现,下面就来详细介绍相关的方法及注意点,前提是你已经对pandas有一定的了解
导入数据
这里介绍的是从Excel导入数据,当然也可以从其他文件导入、数据库查询后导入等,为了弄清楚里面的细节,本教程从Excel导入数据
import pandas as pd
import numpy as np
data=pd.read_excel('split.xlsx')
查看原始数据及各列数据类型,可以看到指标、选项都是object类型,其中选项列没有缺失值

对选项列进行分列
对导入的原始数据进行分列,这里运用的是pandas.Series.str.split方法,可以理解为把Series作为字符串进行分列操作,分列都是对字符串进行操作的
split_data=data['选项'].str.split(':',expand=True) #需要添加expand=True,使分列后的数据扩展为一个数据框
split_data
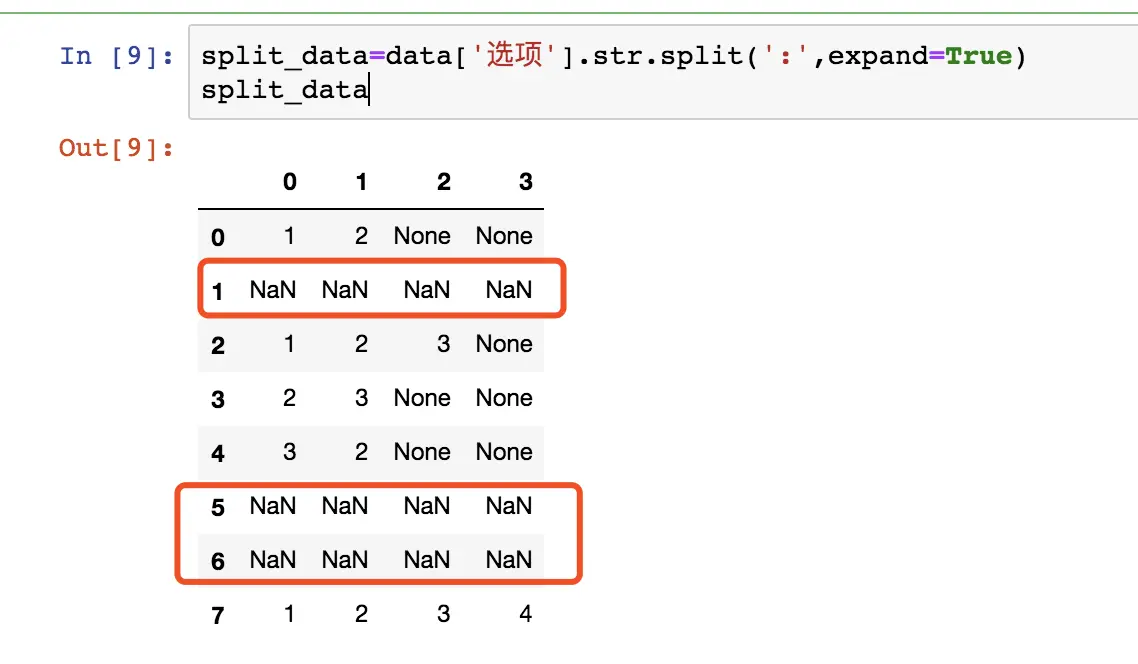
可以明显看到分列后的数据,第1、5、6索引行全是缺失值, 对比上面的原始数据,这些都是只有一个数字,难道分列方法split对只有一个数字不能分列吗?其实则并不然,实际的原因请往下看
寻找原因
查看Excel里面的数据寻找原因,发现选项所在列,单个数字在Excel单元格是数字,其他的都是文本,因Excel里面数字一般都是在单元格里面都是靠右对齐,而文本都是靠左对齐
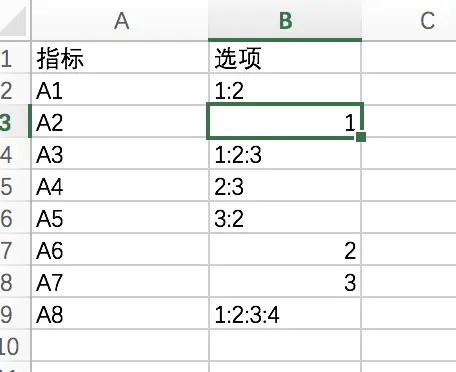
但是pandas导入数据后,已经查看了选项列为object类型,难道判断的数据类型有问题? 请继续往下看
强制转换数据类型,再次分列
data['选项']=data['选项'].astype('str')
#data['选项']=data['选项'].astype('object') #这两个代码都可以转换
split_data=data['选项'].str.split(':',expand=True)
split_data
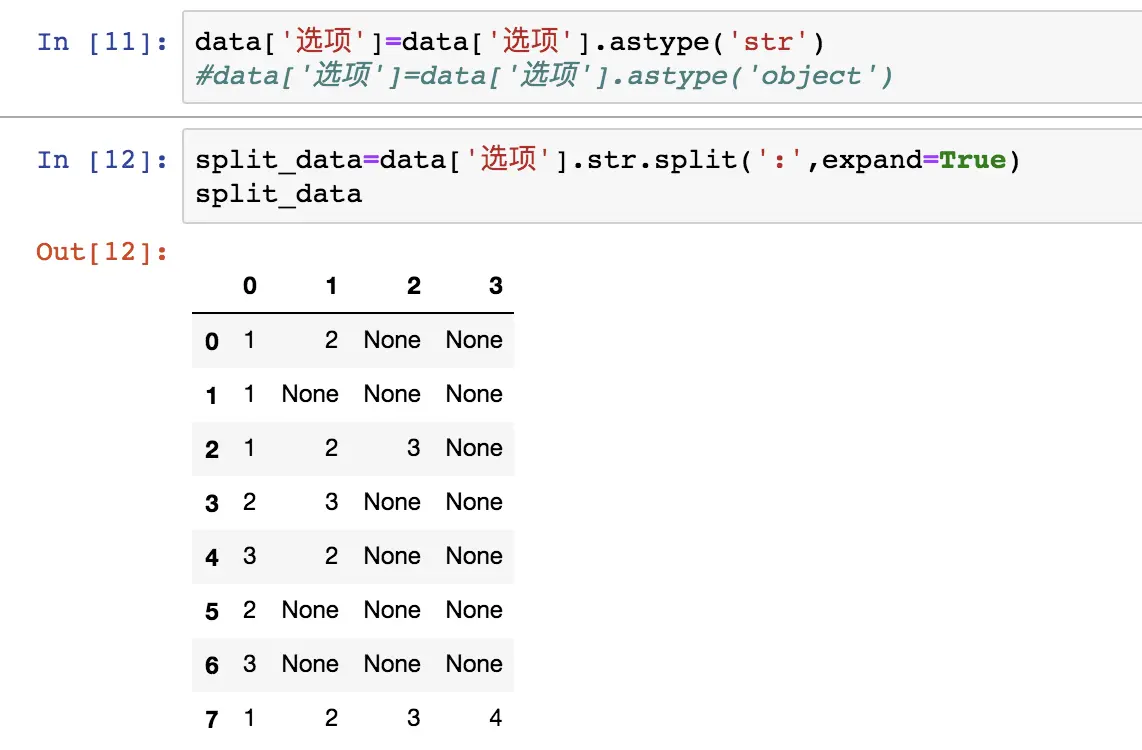 可以看到已经成功进行分列了,说明pandas读取的数据,判断出来的数据类型并不一定是这一列所有数据的真实类型,而是能概括所有类型的一个较大的类型(兼容所有类型),并没有强制转换为同一个数据类型,比如选项列,里面有数值型、字符串型,那么较大的一个类型是object,pandas及认为该列数据类型是object
可以看到已经成功进行分列了,说明pandas读取的数据,判断出来的数据类型并不一定是这一列所有数据的真实类型,而是能概括所有类型的一个较大的类型(兼容所有类型),并没有强制转换为同一个数据类型,比如选项列,里面有数值型、字符串型,那么较大的一个类型是object,pandas及认为该列数据类型是object
合并数据
split_data.columns=['s_1','s_2','s_3','s_4']
data.join(split_data) #join比较方便,根据索引直接对两个表进行链接,而merge需要设置链接时的字段
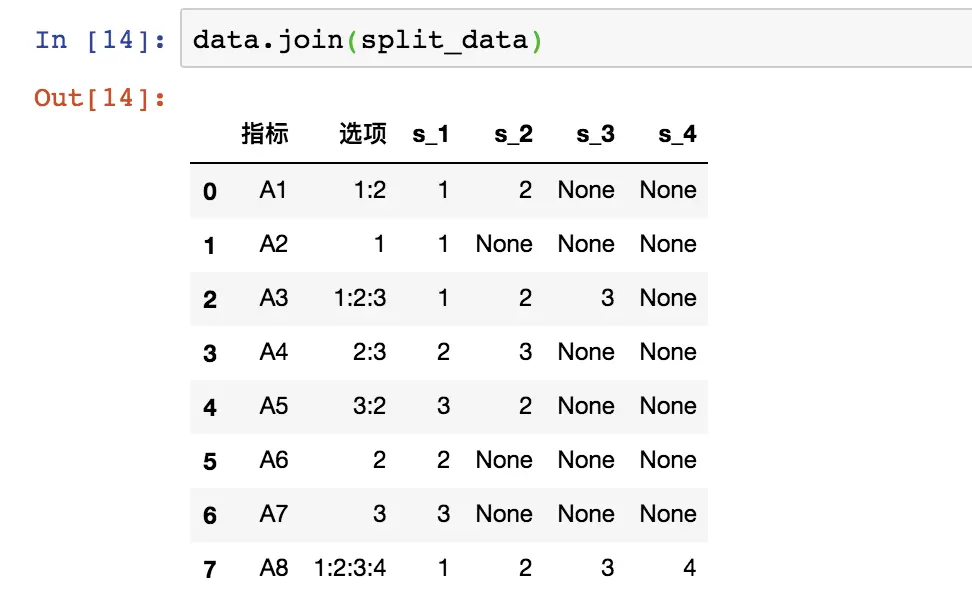
分列时注意事项
- 导入数据后一定要检查数据类型,不要急着去处理
- 分列前检查该列数据类型,确保该列数据类型都是字符串类型,或者object类型,当数据量很大的时候这个很容易出错
pandas里面数据类型对照
详情请参考这篇博文,数据处理过程的数据类型
作者:数据人阿多
背景
最近在处理别人给的数据时,大概 700w+ 行数据,发现有的字段里面存在换行符、斜杠等一些特殊字符,于是想着就用Python来处理下,因为Pandas处理数据还是很方便,结果发现这些转义字符: \n、\r、\ 一直替换不掉,后来经过研究成功替换,分享出来供大家参考
演示数据
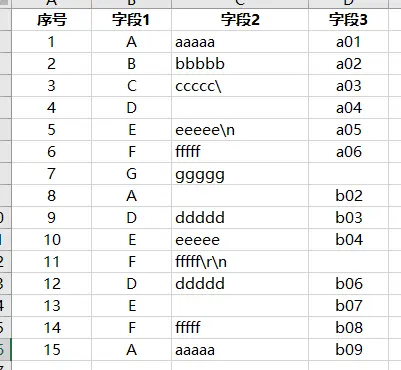
python 与 pandas版本
特意说一下版本,现在不同的版本功能可能不一样
问题复现
因为涉及到字符串替换,所以直接想到的方法是用 pandas.Series.str.replace 来进行替换,但是一直不能成功,即使双斜杠也不行
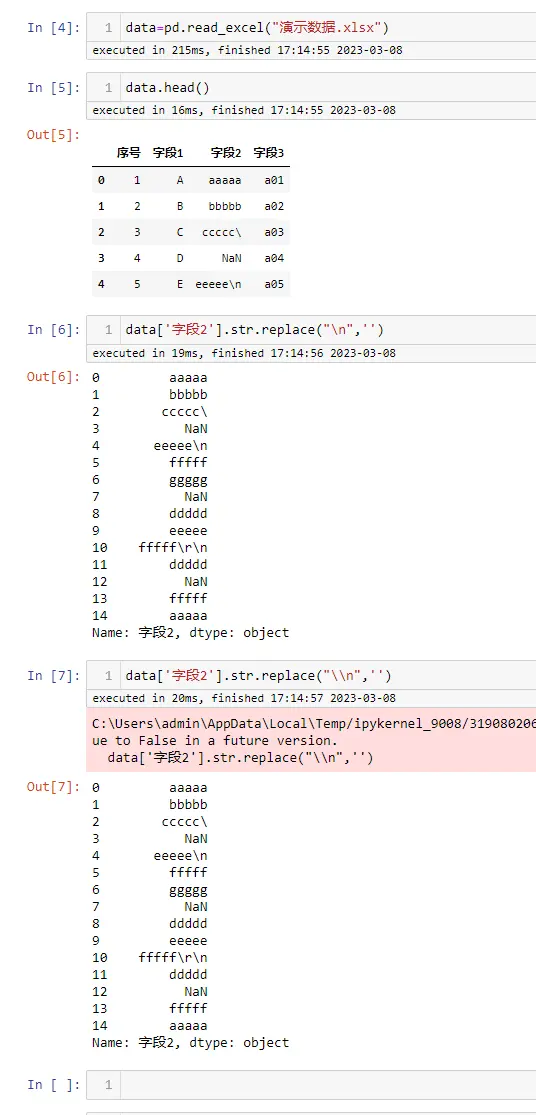
问题解决
在上面第7个单元格运行时,报了一个错误,FutureWarning: The default value of regex will change from True to False in a future version.
于是就翻看了 pandas.Series.str.replace 的官方文档:
http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.replace.html
文档中写了 regex:bool, default True,正则默认是开启的
个人经验:正则表达式来处理转义字符是比较麻烦的事,因为里面的斜杠不知道要写几个,总是记不住
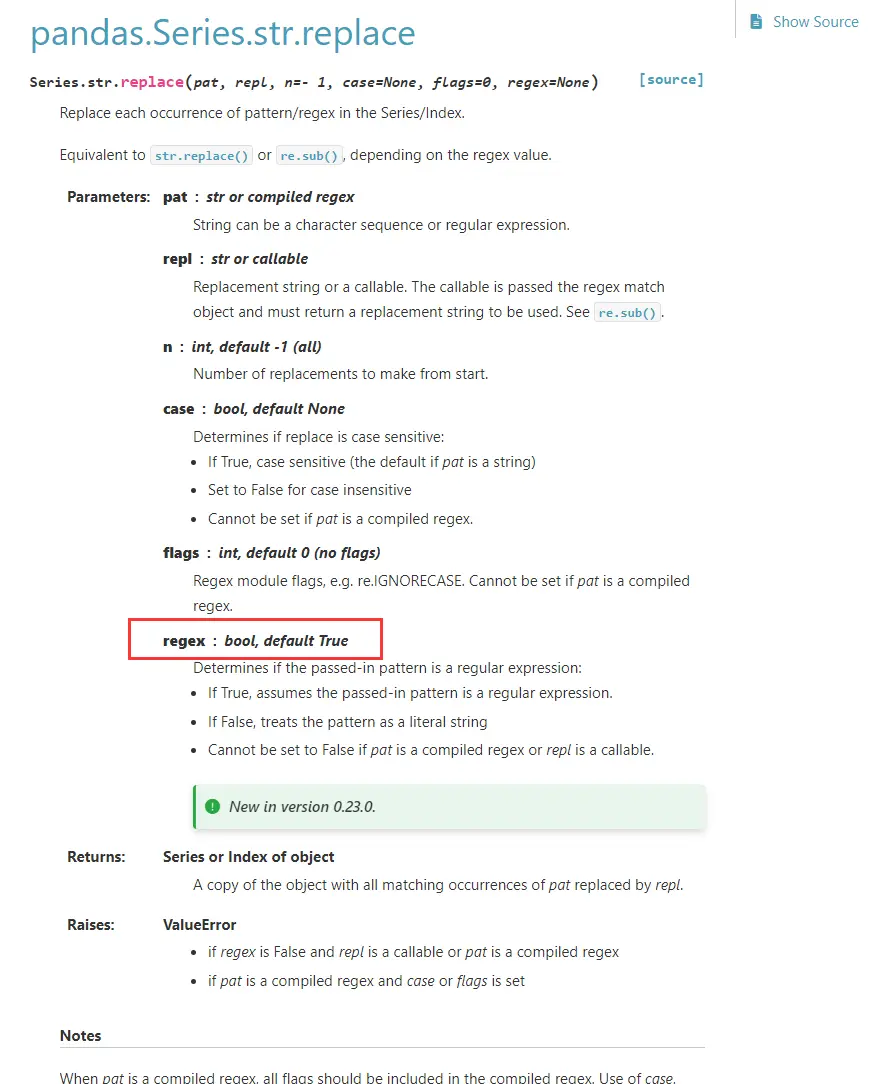
经过测试如下几种方法,可行:
方法1:
明确使用正则来处理,并且使用原字符 r
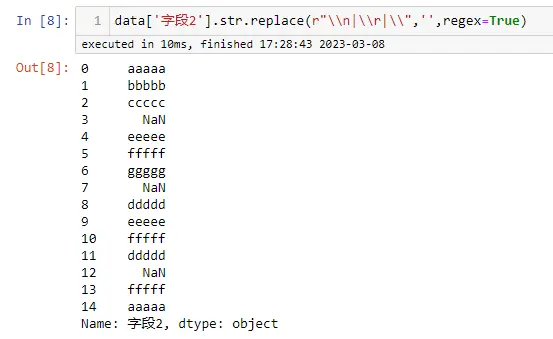
方法2:
明确使用正则来处理,正常的写法,经测试需要4个斜杠
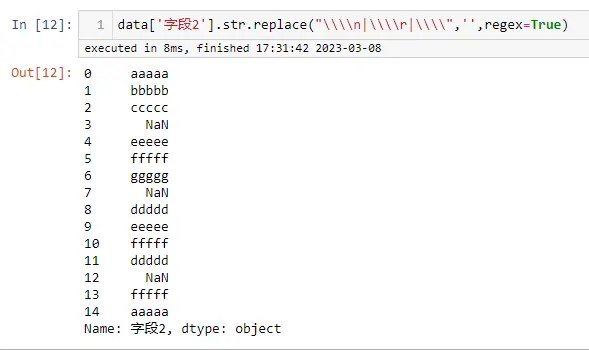
方法3:
不使用正则来处理,但是在处理单个斜杠时,必须用2个
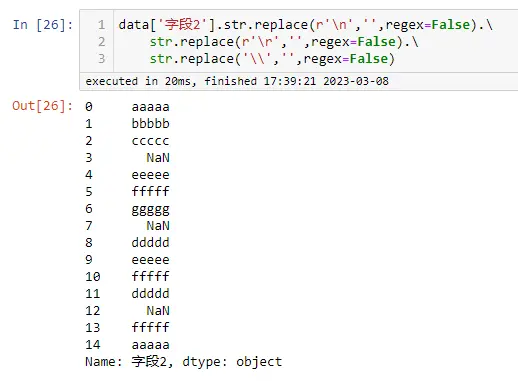
历史相关文章
- Python pandas在读取csv文件时(linux与windows之间传输),数据行数不一致的问题
- Python pandas 里面的数据类型坑,astype要慎用
- Python pandas 数据筛选与赋值升级版详解
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
pandas在数据处理过程中,除了对整列字段进行处理之外,有时还需求对每一行进行遍历,来处理每行的数据。本篇文章介绍 2 种方法,来遍历pandas 的行数据
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.5
import pandas as pd
print(pd.__version__)
#2.1.0
演示数据
方法1
pandas.DataFrame.itertuples:返回的是一个命名元组
官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.itertuples.html
1. 无任何参数
import pandas as pd
data=pd.read_excel("data.xlsx")
for row in data.itertuples():
print("row:",row,"\n")
#row: Pandas(Index=0, 序号=1, 分割字符='1&1&1', 固定宽度='111')
print("type(row):",type(row),"\n")
#type(row): <class 'pandas.core.frame.Pandas'>
print("row.序号:",row.序号)
#row.序号: 1
print("row.分割字符:",row.分割字符)
#row.分割字符: 1&1&1
print("row.固定宽度:",row.固定宽度)
#row.固定宽度: 111
break
2. 忽略掉索引
import pandas as pd
data=pd.read_excel("data.xlsx")
for row in data.itertuples(index=False): #忽律索引
print("row:",row,"\n")
#row: Pandas(序号=1, 分割字符='1&1&1', 固定宽度='111')
print("type(row):",type(row),"\n")
#type(row): <class 'pandas.core.frame.Pandas'>
print("row.序号:",row.序号)
#row.序号: 1
print("row.分割字符:",row.分割字符)
#row.分割字符: 1&1&1
print("row.固定宽度:",row.固定宽度)
#row.固定宽度: 111
break
3. 对命名元组起别名
import pandas as pd
data=pd.read_excel("data.xlsx")
for row in data.itertuples(index=False,name="data"):
print("row:",row,"\n")
#row: data(序号=1, 分割字符='1&1&1', 固定宽度='111')
print("type(row):",type(row),"\n")
#type(row): <class 'pandas.core.frame.data'>
print("row.序号:",row.序号)
#row.序号: 1
print("row.分割字符:",row.分割字符)
#row.分割字符: 1&1&1
print("row.固定宽度:",row.固定宽度)
#row.固定宽度: 111
break
方法2
pandas.DataFrame.iterrows:返回 (index, Series) 元组
官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iterrows.html
import pandas as pd
data=pd.read_excel("data.xlsx")
for index,row in data.iterrows():
print("index:",index,"\n")
#index: 0
print("row:",row,"\n")
#row: 序号 1
#分割字符 1&1&1
#固定宽度 111
#Name: 0, dtype: object
print("type(row):",type(row),"\n")
#type(row): <class 'pandas.core.series.Series'>
print("row['序号']:",row['序号'])
#row['序号']: 1
print("row['分割字符']:",row['分割字符'])
#row['分割字符']: 1&1&1
print("row['固定宽度']:",row['固定宽度'])
#row['固定宽度']: 111
break
历史相关文章
- Python 利用pandas对数据进行特定排序
- Python pandas 2.0 初探
- Python pandas.str.replace 不起作用
- Python数据处理中 pd.concat 与 pd.merge 区别
- 对比Excel,利用pandas进行数据分析各种用法
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
数据分列在数据处理中很常见,数据分列一般指的都是字符串分割,这个功能在Excel里面很实用,处理数据非常方便,那么在pandas数据框中怎么使用呢,今天这篇文章就来详细介绍下
模拟数据
以下面这9行数据作为案例来进行处理
读取数据
#加载库
import pandas as pd
#读取数据
data=pd.read_excel('data.xlsx')
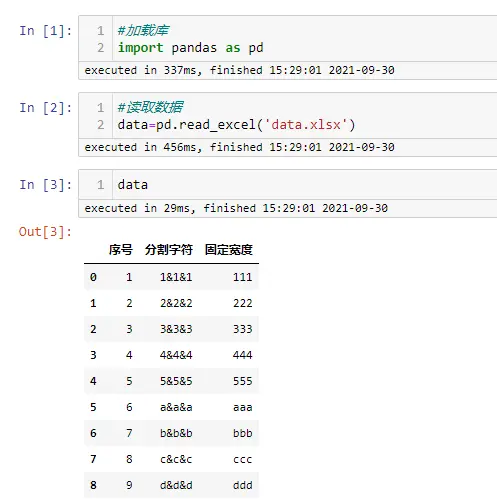
分割符号分列
主要运用了pandas里面列的str属性,str 有很多的方法,感性的同学可以自动查找,这里不做过多介绍。分割字符用到的就是split方法
重点:在分割前一定要把该列强制转换为字符型
#对指定列进行分割
split_data_1=data['分割字符'].astype('str').str.split('&',expand=True)
#修改分割后的字段名称
split_data_1.columns=['D_'+str(i) for i in split_data_1.columns]
#与原始数据进行合并
data_result=data.join(split_data_1)
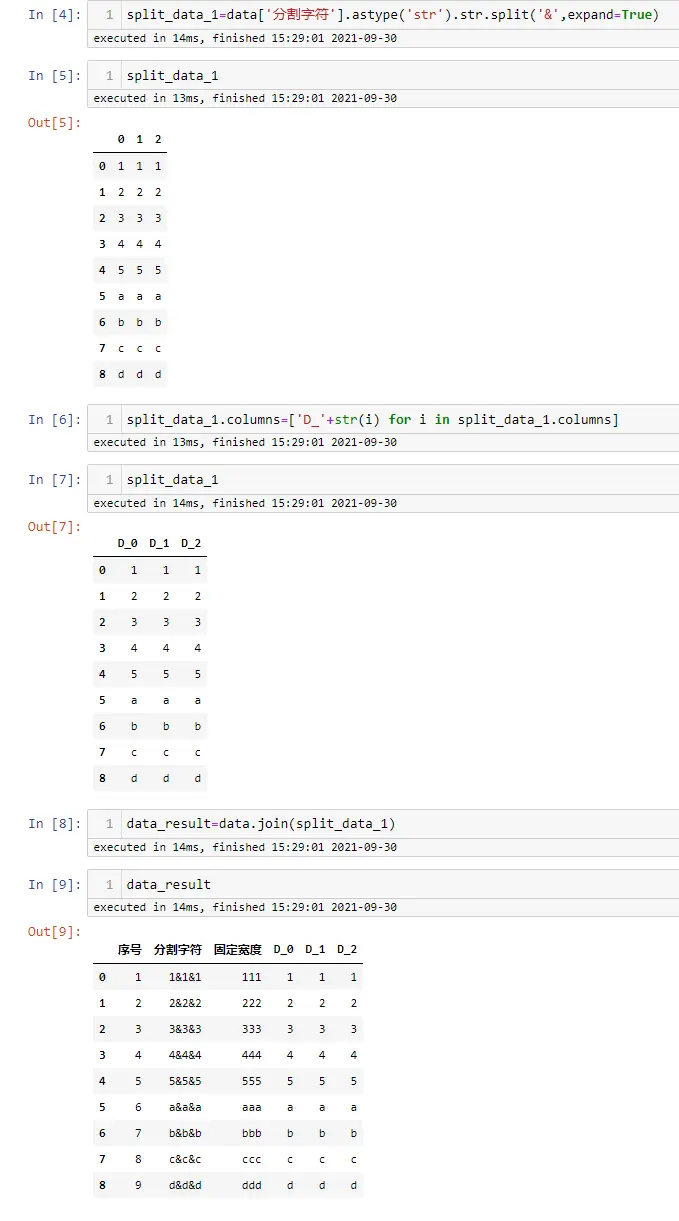
固定宽度分列
pandas里面没有固定分割的相应函数,这里巧妙的运用了辅助函数来进行处理,这里的固定宽度为1
#定义个辅助函数
def concat_split(x,width=1):
result=''
start=0
while True:
s=str(x)[start:start+width]
if s:
result =result + s + '&'
else:
break
start=start+width
return result[:-1]
#先利用辅助函数,再进行分割
split_data_2=data['固定宽度'].map(concat_split).str.split('&',expand=True)
#修改分割后的字段名称
split_data_2.columns=['W_'+str(i) for i in split_data_2.columns]
#与原始数据进行合并
data_result=data.join(split_data_2)
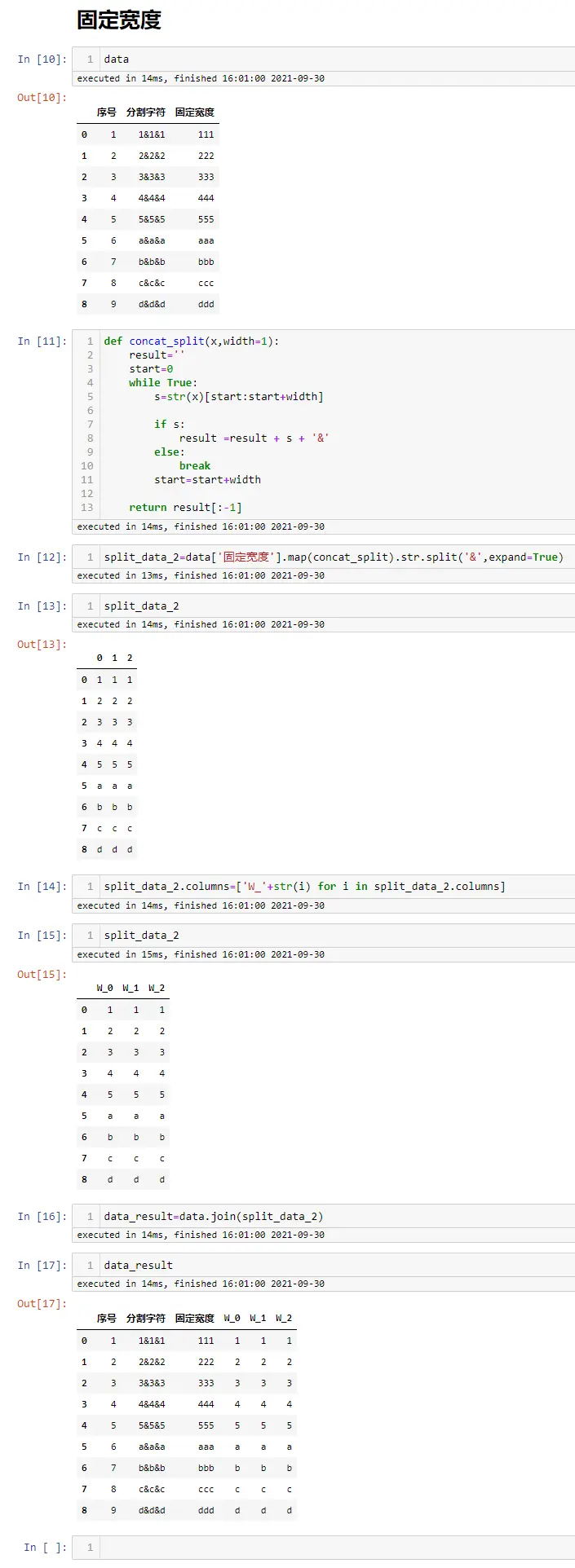
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
value_counts介绍
value_counts是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中个数,类似Excel里面的count函数
其是pandas下面的顶层函数,也可以作用在Series、DataFrame下
pd.value_counts(
values,
sort=True, #是否排序,默认是要排序
ascending=False, #默认降序排列
normalize=False, #标准化、转化成百分比形式
bins=None, #可以自定义分组区间,默认是没有,但也可以自定义区间
dropna=True, #是否删除nan,默认删除
)
常规用法:
import pandas as pd
pd.value_counts()
df.value_counts()
df['字段'].value_counts()
#创建模拟数据
>>> import pandas as pd
>>> data=pd.DataFrame({'字段1':[1,2,3,4,5,6,5,3,2,4,5,4,4,4,6],
'字段2':['A','B','B','A','A','A','B','B','B','C','C','C','C','B','B']})
>>> data
字段1 字段2
0 1 A
1 2 B
2 3 B
3 4 A
4 5 A
5 6 A
6 5 B
7 3 B
8 2 B
9 4 C
10 5 C
11 4 C
12 4 C
13 4 B
14 6 B
>>> data.dtypes
字段1 int64
字段2 object
dtype: object
Series情况下:
pandas 的 value_counts() 函数可以对Series里面的每个值进行计数并且排序,默认是降序
>>> data['字段2'].value_counts()
B 7
C 4
A 4
Name: 字段2, dtype: int64
>>> data['字段1'].value_counts()
4 5
5 3
6 2
3 2
2 2
1 1
Name: 字段1, dtype: int64
可以看出,既可以对分类变量统计,也可以对连续数值变量统计
如果是要对结果升序排列,可以添加ascending=True来改变
>>> data['字段2'].value_counts(ascending=True)
A 4
C 4
B 7
Name: 字段2, dtype: int64
如果不想看统计的个数,而是想看占比,那么可以设置normalize=True即可,结果是小数形式
>>> data['字段2'].value_counts(normalize=True)
B 0.466667
C 0.266667
A 0.266667
Name: 字段2, dtype: float64
DataFrame情况下
可以通过apply,对每一列变量进行统计
>>> data.apply(pd.value_counts)
字段1 字段2
1 1.0 NaN
2 2.0 NaN
3 2.0 NaN
4 5.0 NaN
5 3.0 NaN
6 2.0 NaN
A NaN 4.0
B NaN 7.0
C NaN 4.0
通过pandas进行调用
>>> pd.value_counts(data['字段2'])
B 7
C 4
A 4
Name: 字段2, dtype: int64
以上是自己实践中遇到的一些点,分享出来供大家参考学习,欢迎关注DataShare公众号
作者:数据人阿多
背景
最近在处理用户评论数据时,从Linux服务器上面用pandas导出的csv文件,下载到自己的Windows电脑,再用本地pandas读取时发现数据行数不一致的情况,比如在Linux服务器上面数据一共有10行,但是用自己本地电脑pandas读取时确大于10行。
问题出现的具体场景:
公司Linux服务器上面安装的有Jupyter notebook,在自己本地电脑输入网址是可以直接访问并使用,而且很方便上传、下载文件,对于Linux服务器小白来说很方便,省去了ssh连接Linux服务器的过程。 遇到的这个问题是通过本地电脑连接到Linux服务器Jupyter notebook处理了一些数据(用户评论文本数据),然后导出到csv文件,下载到自己的Windows电脑,然后使用本地的python环境读取数据,发现数据行数不一致的问题。
问题查找
首先找出了从哪一行开始出现串行,查看具体的文本数据,发现在文本数据里面出现特殊转义字符\r,于是豁然开朗,Linux的换行符为\n,而Windows的换行符为\r\n,所以在文本里面出现\r字符时,与Windows换行符有冲突,pandas读取数据时出现数据行数不一致问题。
解决方法
在pandas读取csv数据时,可利用参数lineterminator,明确指定该参数后,可以解决该问题
pd.read_csv('test.csv',lineterminator='\n')
具体可以看看pandas.to_csv这个参数的解释

案例复现
Linux服务器上面的数据
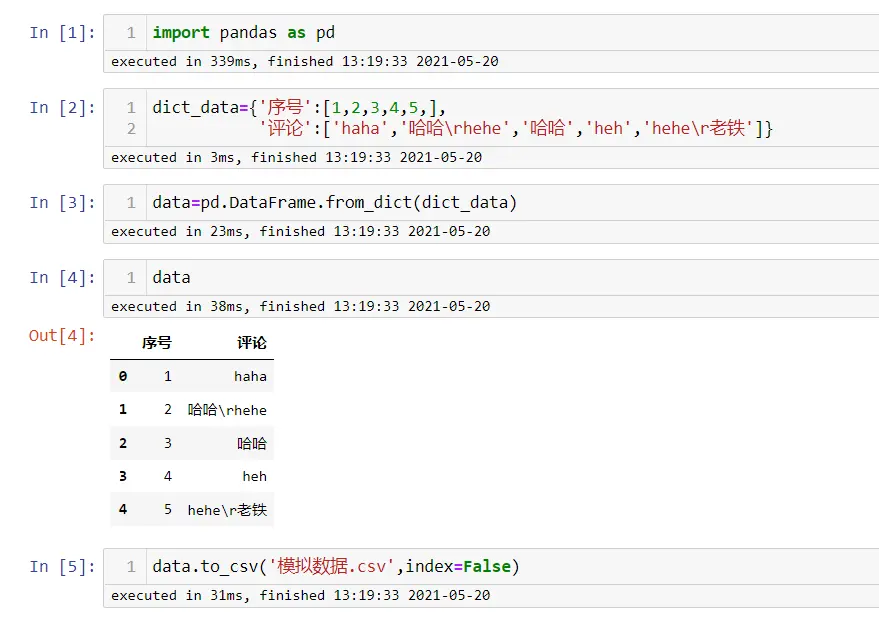
下载后用Windows来读取该数据
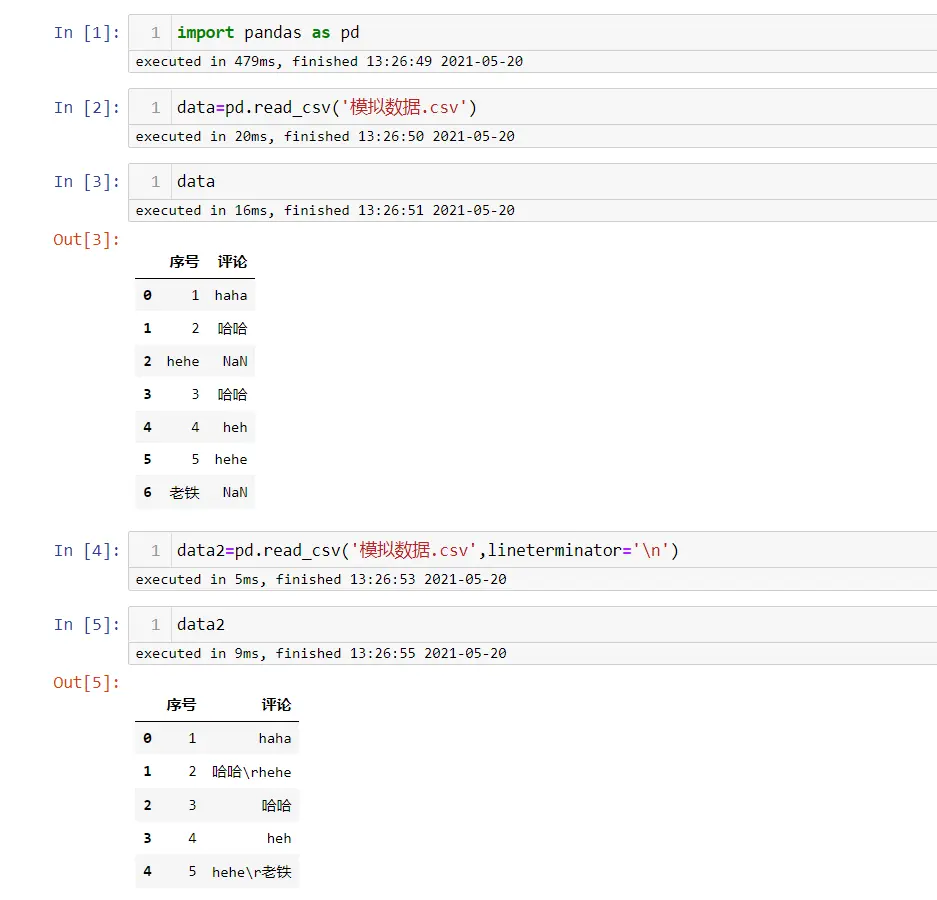
可以看出,如果不加 lineterminator 参数的话,数据行数会不一致,加了参数后,数据行数保持一致。由于Linux与Windows两个系统的换行符不一样,因此大家在处理数据时可以利用 lineterminator 参数来避免这样的问题,分享出来供大家参考
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
平时用时知道有相应的设置及相应的原理,具体设置时又不好查找,现特此整理出来供大家收藏
可左右滑动查看代码
Anaconda
pip list
#或者
conda list
#其中,pip list 只能查看库,而 conda list 则可以查看库以及库的版本
pip install scipy
pip install scipy --upgrade
# 或者
conda install scipy
conda update scipy
# 更新所有库
conda update --all
# 更新 conda 自身
conda update conda
# 更新 anaconda 自身
conda update anaconda
jupyter
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
#内嵌画图
%matplotlib inline
#单独画图
%matplotlib qt
#画图中文乱码、负号
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False
#linux指定字体
from matplotlib.font_manager import FontProperties
zhfont = FontProperties(fname="/home/public/font/SimHei.ttf", size=14)
plt.xlabel('日期',fontproperties = zhfont,fontsize=14)
plt.xticks(fontproperties=zhfont)
#让一个cell同时有多个输出print
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
主要的数据分析包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.figure import SubplotParams
#我们使用SubplotParams 调整了子图的竖直间距
#plt.figure(figsize=(12, 6), dpi=200, subplotpars=SubplotParams(hspace=0.3))
import scipy.stats as stats
import seaborn as sns
import statsmodels.api as sm
Sklearn
from sklearn import datasets #本地数据
from sklearn.model_selection import train_test_split #进行数据分割
from sklearn.feature_extraction import DictVectorizer #特征抽取和向量化
from sklearn.preprocessing import PolynomialFeatures #多项式特征构造
from sklearn.feature_selection import VarianceThreshold #基于方差特征选择
from sklearn.feature_selection import SelectKBest,SelectPercentile #特征选择
#For classification: chi2, f_classif, mutual_info_classif
#For regression: f_regression, mutual_info_regression
from sklearn.feature_selection import RFE #递归特征消除 (Recursive Feature Elimination)
from sklearn.feature_selection import SelectFromModel #基于模型选择特征
from sklearn.decomposition import PCA #主成分分析
from sklearn.manifold import MDS #多维尺度分析
from sklearn.manifold import TSNE #T分布和随机近邻嵌入
from sklearn.pipeline import Pipeline #管道
from sklearn import metrics #模型评估
from sklearn.model_selection import GridSearchCV #网格搜索交叉验证
from sklearn.model_selection import KFold #K折交叉验证
from sklearn.model_selection import cross_val_score #交叉验证
from sklearn.linear_model import LinearRegression #线性回归
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn import svm #支持向量机
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.ensemble import GradientBoostingClassifier #梯度提升树
from sklearn.naive_bayes import MultinomialNB #多项式朴素贝叶斯
from sklearn.naive_bayes import BernoulliNB #伯努利朴素贝叶斯
from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯
from sklearn.neighbors import KNeighborsClassifier #k紧邻
from sklearn.cluster import KMeans #k均值聚类
from sklearn.cluster import DBSCAN #基于密度的空间聚类
from sklearn.cluster import SpectralClustering #谱聚类
from sklearn.cluster import Birch #层次聚类
from sklearn.externals import joblib #保存模型
pycharm脚本模板
"""
===========================
@File : ${NAME}
@Author: DataShare
@Date : ${DATE} ${TIME}
===========================
"""
作者:数据人阿多
- 确定文件编码
当不知道别人给的txt文件不知道是什么编码时,可以通过chardet模块来判断是属于什么编码 chardet模块是第三方模块,需要手动安装
import chardet
data= open('111.TXT','rb').readline()
#读取一行数据即可,不用全部读取,节省时间,'rb' 指定打开文件时用二进制方法
print(data) #预览一下二进制数据
chardet.detect(data) #判断编码
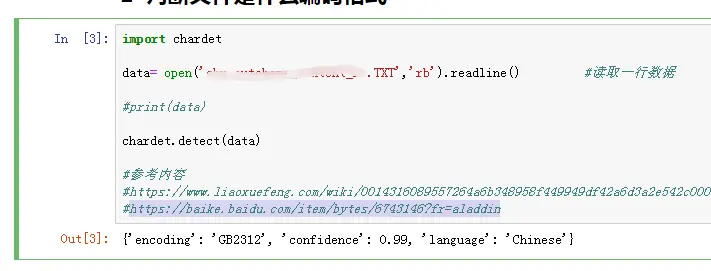
由输出结果可以判定,该txt是'GB2312'编码概率是99%,confidence: 0.99 ,所以可以确定该txt编码格式就是'GB2312'
- 用判断出来的编码打开txt文件
f = open('111.TXT','r',encoding='gb2312') #gb2312<gbk<gb18030
data=f.readlines() #把数据读取到列表里面
f.close()
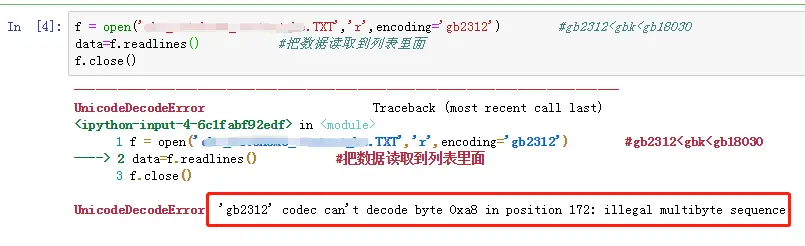
这时出现错误,为什么已经判断文件就是'GB2312',打开还是报错呢???
难道是判断的编码错误的,然后再去读取原txt文件,多读取了一些数据再判断是什么编码,结果还是'GB2312',这是为什么呢???
- 设置忽略非法字符参数
查看了open函数的参数后,里面有个errors参数,有三个级别可选,一般选择ignore即可
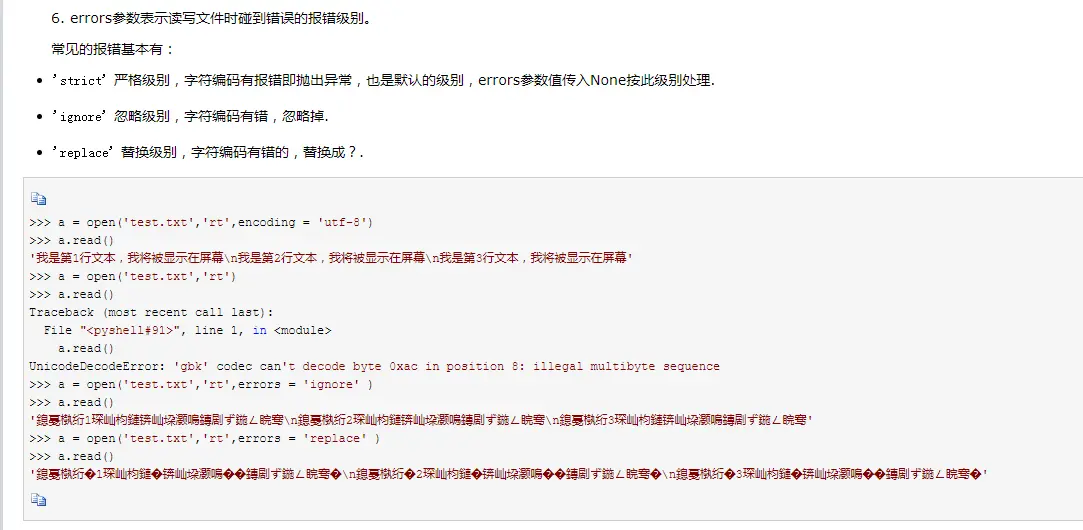
- 再次去打开文件
设置errors='ignore'后,成功打开文件
f = open('111.TXT','r',encoding='gb2312',errors='ignore')
#忽略非法字符 gb2312<gbk<gb18030
data=f.readlines() #把数据读取到列表里面
f.close()
- 思考:为什么会有不能识别的字符呢
- 网络爬取的文字,里面有一些表情、其他语言,例如:韩语、日语,不是中文的所能包含的,在再次解码时可能会报错
- 由于文件比较大,在文件拷贝时由于磁盘原因,可别字符被修改或遗漏
- 网络爬取时,信息包里面的字符错误,众所周知信息在传输时是1或0,在网线里面是波形或者激光,如果在较远传输过程中,有可能会丢失信息等一些情况,能确保99%的信息量已经很好了
参考
- https://www.cnblogs.com/sesshoumaru/p/6047046.html
- https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001510905171877ca6fdf08614e446e835ea5d9bce75cf5000
- https://baike.baidu.com/item/bytes/6743146?fr=aladdin
以上是自己在处理数据时遇到的一些阻碍,分享出来供大家参考,欢迎指正与交流
作者:数据人阿多
背景
数据的合并与关联是数据处理过程中经常遇到的问题,在SQL、HQL中大家可能都有用到 join、uion all 等 ,在 Pandas 中也有同样的功能,来满足数据处理需求,个人感觉Pandas 处理数据还是非常方便,数据处理效率比较高,能满足不同的业务需求
本篇文章主要介绍 Pandas 中的数据拼接与关联
数据拼接---pd.concat
concat 是pandas级的函数,用来拼接或合并数据,其根据不同的轴既可以横向拼接,又可以纵向拼接
函数参数
pd.concat(
objs: 'Iterable[NDFrame] | Mapping[Hashable, NDFrame]',
axis=0,
join='outer',
ignore_index: 'bool' = False,
keys=None,
levels=None,
names=None,
verify_integrity: 'bool' = False,
sort: 'bool' = False,
copy: 'bool' = True,
) -> 'FrameOrSeriesUnion'
objs:合并的数据集,一般用列表传入,例如:[df1,df2,df3]axis:指定数据拼接时的轴,0是行,在行方向上拼接;1是列,在列方向上拼接join:拼接的方式有 inner,或者outer,与sql中的意思一样
以上三个参数在实际工作中经常使用,其他参数不再做介绍
案例:
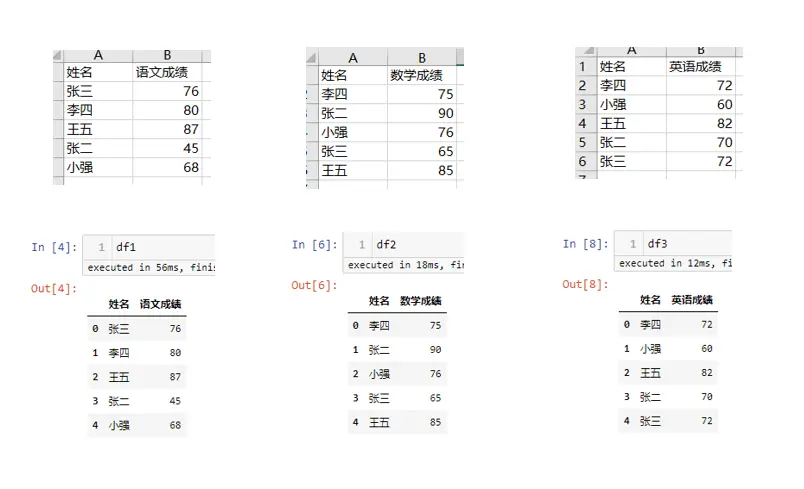
- 横向拼接
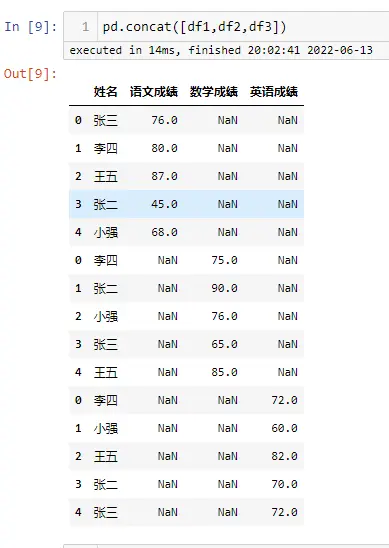 字段相同的列进行堆叠,字段不同的列分列存放,缺失值用
字段相同的列进行堆叠,字段不同的列分列存放,缺失值用NAN来填充,下面对模拟数据进行变换用相同的字段,进行演示
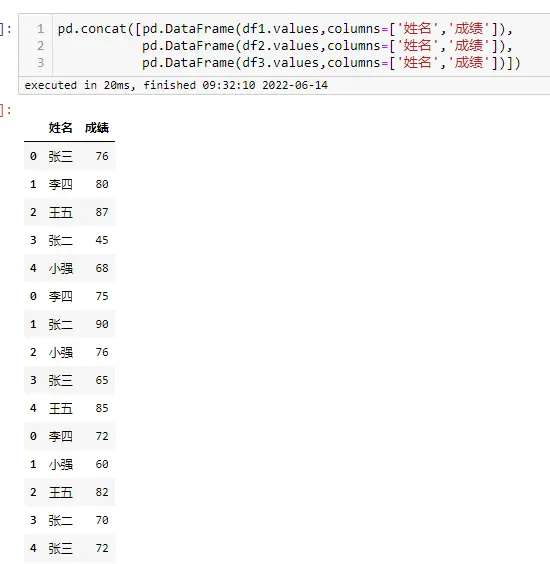
- 纵向拼接
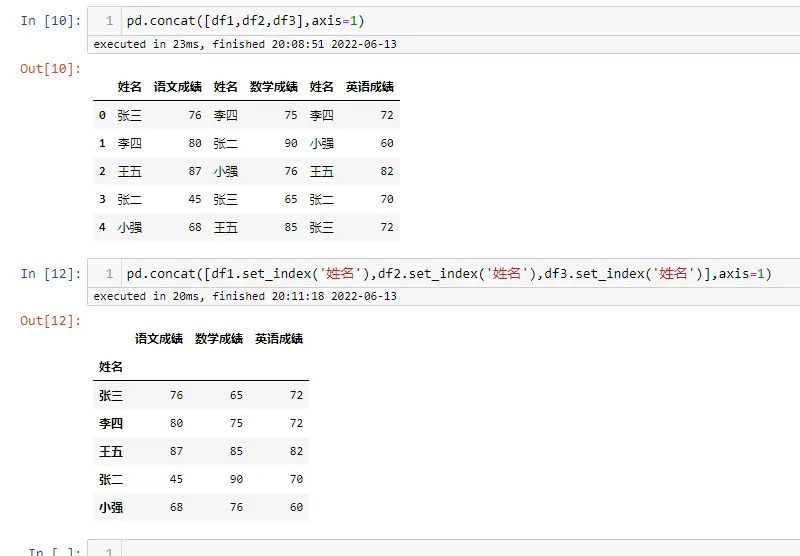
可以看出在纵向拼接的时候,会按索引进行关联,使相同名字的成绩放在一起,而不是简单的堆叠
数据关联---pd.merge
数据联接,与SQL中的join基本一样,用来关联不同的数据表,有左表、右表的区分,可以指定关联的字段
函数参数
pd.merge(
left: 'DataFrame | Series',
right: 'DataFrame | Series',
how: 'str' = 'inner',
on: 'IndexLabel | None' = None,
left_on: 'IndexLabel | None' = None,
right_on: 'IndexLabel | None' = None,
left_index: 'bool' = False,
right_index: 'bool' = False,
sort: 'bool' = False,
suffixes: 'Suffixes' = ('_x', '_y'),
copy: 'bool' = True,
indicator: 'bool' = False,
validate: 'str | None' = None,
) -> 'DataFrame'
left:左表right:右表how:关联的方式,{'left', 'right', 'outer', 'inner', 'cross'}, 默认关联方式为 'inner'on:关联时指定的字段,两个表共有的left_on:关联时用到左表中的字段,在两个表不共有关联字段时使用right_on:关联时用到右表中的字段,在两个表不共有关联字段时使用
以上参数在实际工作中经常使用,其他参数不再做介绍
案例:
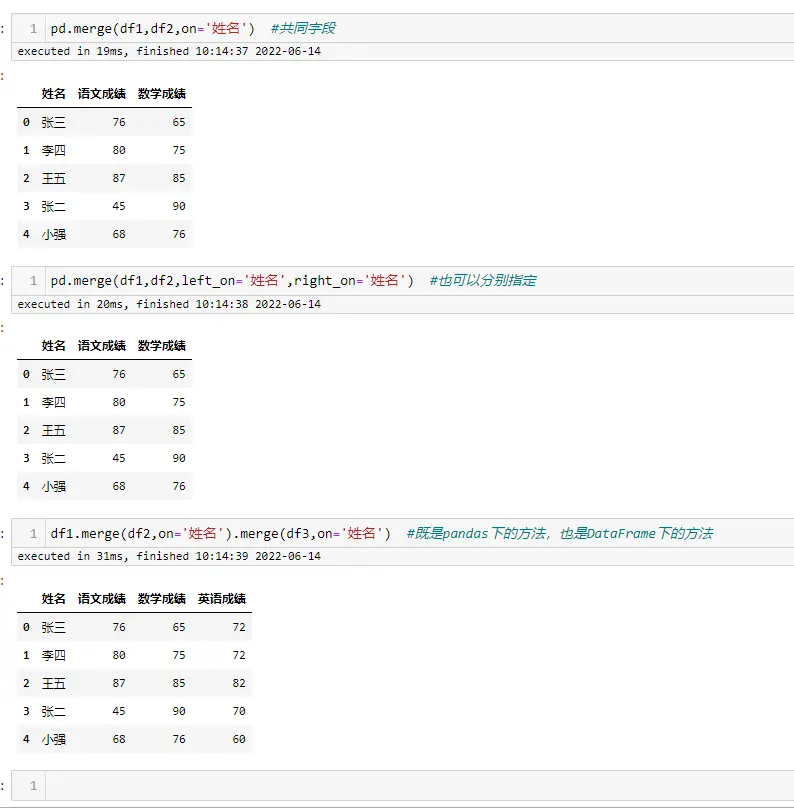
merge 的使用与SQL中的 join 很像,使用方式基本一致,既有内连接,也有外连接,用起来基本没有什么难度
两者区别
- concat 只是 pandas 下的方法,而 merge 即是 pandas 下的方法,又是DataFrame 下的方法
- concat 可以横向、纵向拼接,又起到关联的作用
- merge 只能进行关联,也就是纵向拼接
- concat 可以同时处理多个数据框DataFrame,而 merge 只能同时处理 2 个数据框
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在进行数据建模时(有时也叫训练模型),我们需要先经过数据清洗、特征选择与特征构造等预处理步骤,然后构造一个模型进行训练,其中One-Hot编码属于数据清洗步骤里面。
One-Hot意义
在进行特征处理时,分类数据和顺序数据这种字符型变量,无法直接用于计算,那么就需要进行数值化处理。
其中分类数据,比如一个特征包含红(R),绿(G),蓝(B)3个分类,那么怎么给这3个分类进行数值化处理呢,可以直接用1,2,3来表示吗?
肯定不行,如果用1,2,3表示,那么3种颜色之间就会产生等级差异,本来他们之间应该是平等的,这时就需要进行one-hot编码(哑变量),如下图所示的转换
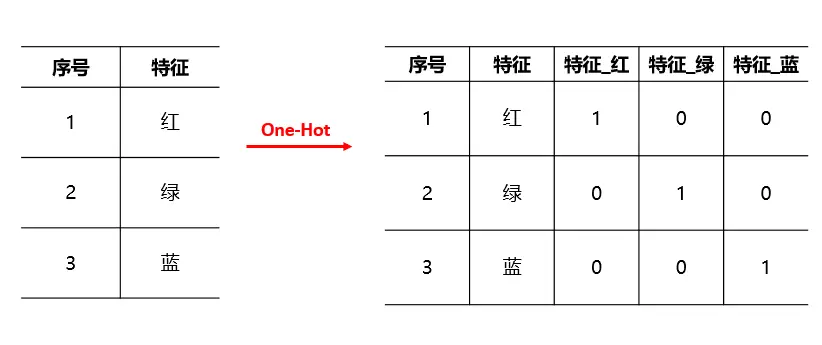
实操数据
利用西瓜数据集(部分特征)为例进行实操,这个数据在网上都可下载到
 读取西瓜数据到数据框里面
读取西瓜数据到数据框里面
import pandas as pd
data = pd.read_excel('西瓜数据集.xlsx', sheet_name='西瓜')
data.head()
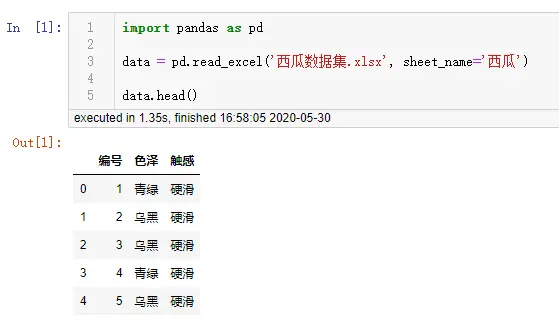
常用方法
- pandas里面的get_dummies方法
这个方法是最简单,最直接的方法
#也可以用concat,join
data_onehot=data.merge(pd.get_dummies(data,columns=['色泽','触感']),on='编号')
data_onehot.head()
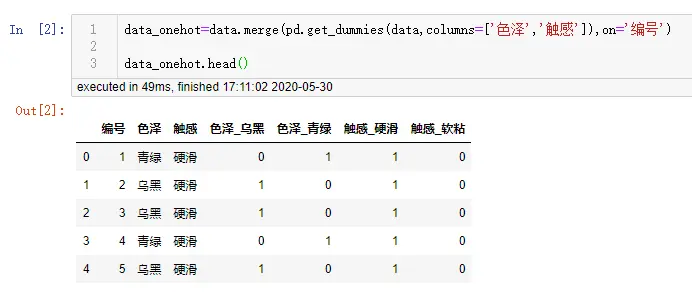
- sklearn里面的One-HotEncoder方法
利用One-HotEncoder进行转换
from sklearn.preprocessing import OneHotEncoder
one_hot=OneHotEncoder()
data_temp=pd.DataFrame(one_hot.fit_transform(data[['色泽','触感']]).toarray(),
columns=one_hot.get_feature_names(['色泽','触感']),dtype='int32')
data_onehot=pd.concat((data,data_temp),axis=1) #也可以用merge,join
data_onehot.head()

- 自定义函数方法
def OneHot(df,columns):
df_new=df.copy()
for column in columns:
value_sets=df_new[column].unique()
for value_unique in value_sets:
col_name_new=column+'_'+value_unique
df_new[col_name_new]=(df_new[column]==value_unique)
df_new[col_name_new]=df_new[col_name_new].astype('int32')
return df_new
data_onehot_def=OneHot(data,columns=['色泽','触感'])
data_onehot_def.head()
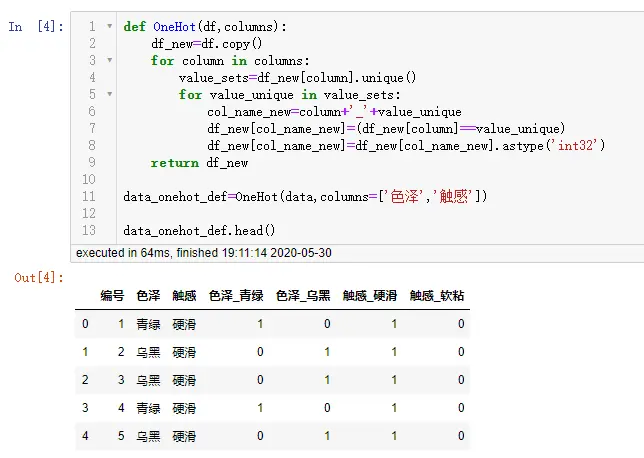
历史相关文章
- Python pandas 里面的数据类型坑,astype要慎用
- Pandas数据处理误区要知其然知其所以然
- Python pandas 数据筛选与赋值升级版详解
- 历史双色球数据分析---python
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近在进行财务平台报告自动化建设,由于涉及的都是Excel文件,并且文件里面有很多合并单元格情况,所以在处理数据时用pandas不是很方便,综合考虑后利用VBA来处理。
自己也是先学的VBA,后学的Python,所以平台上的一些功能很快开发完,接下来问题就出现了,在Python调用VBA时,出现程序不能运行的情况,经过反复排查发现是宏信任级别的问题。
出现这种情况,可以通过手动修改宏的信任级别,在文件---选项----信任中心----宏设置,把宏设置为“启用所有宏”,如下所示:
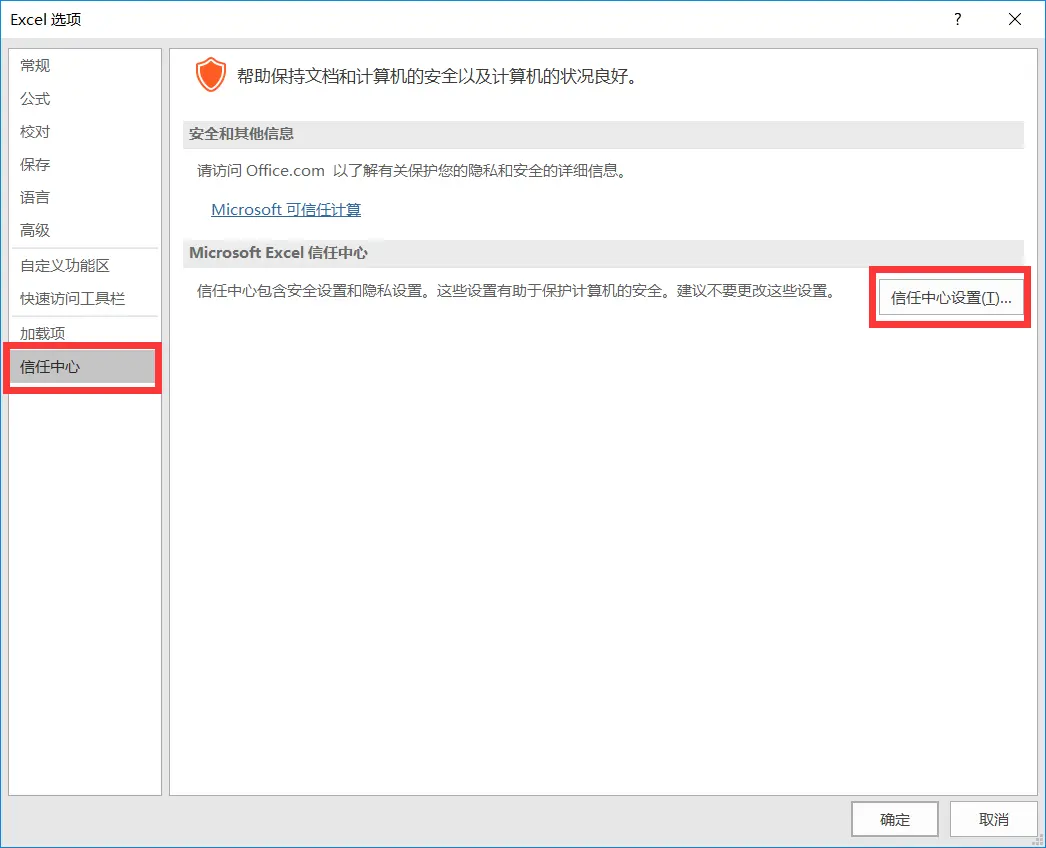

但是作为自动化平台,需要考虑到程序健壮性,不能总是手动来修改,于是在网上查找了相关资料,发现可以通过修改系统注册表的方法,来规避这个问题
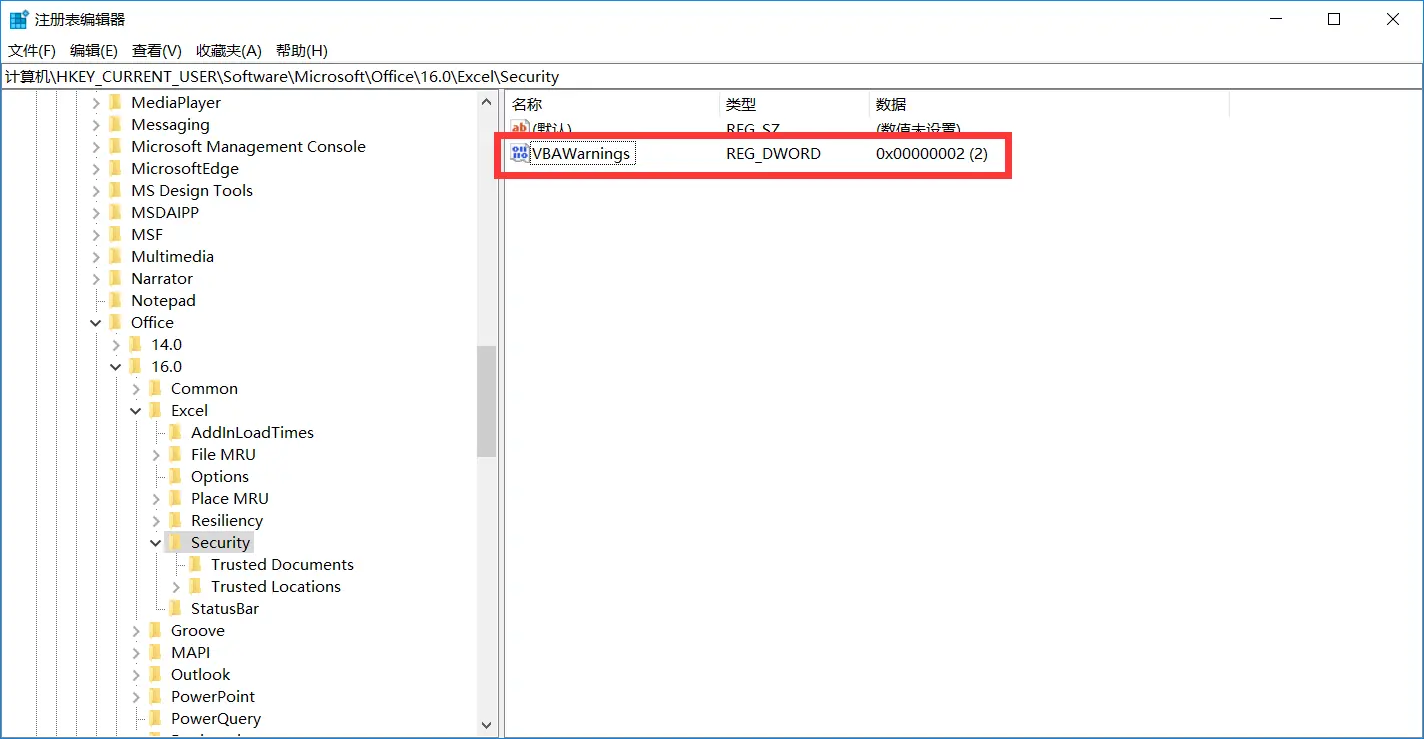
注册表是什么?
注册表(Registry,繁体中文版Windows操作系统称之为登录档)是Microsoft Windows中的一个重要的数据库,用于存储系统和应用程序的设置信息。早在Windows 3.0推出OLE技术的时候,注册表就已经出现。随后推出的Windows NT是第一个从系统级别广泛使用注册表的操作系统。但是,从Microsoft Windows 95操作系统开始,注册表才真正成为Windows用户经常接触的内容,并在其后的操作系统中继续沿用至今。
从定义来看,注册表是用于存储系统和应用程序的设置信息
通过Python修改注册表
#导入相关库
import winreg
import win32com.client
#定义Excel程序
xl=win32com.client.Dispatch("Excel.Application")
#指定注册表文件夹位置并获取
subkey='Software\\Microsoft\\Office\\' + xl.Version+'\\Excel\\Security'
key=winreg.OpenKey(winreg.HKEY_CURRENT_USER,subkey,0, winreg.KEY_SET_VALUE)
#修改宏信任级别为1
winreg.SetValueEx(key, 'VBAWarnings', 0, winreg.REG_DWORD, 1)
通过以上程序,及可以成功把Excel宏的信任级别修改为“启用所有宏”,这样就全部实现了自动化
以上是自己实践中遇到的一些点,分享出来供大家参考学习,欢迎关注微信公众号DataShare,不定期分享干货
作者:数据人阿多
在网上查看了一些python处理excel库资料,参考相关内容
Python读写Excel文件第三方库汇总,你想要的都在这儿!
经过对比后,最后选择xlwings库,来处理excel文件
 由于自己会VBA,所以xlwings里面的一些函数用起来还是比较方便的,能够看懂大概用法,如果你不会VBA的话也没关系
由于自己会VBA,所以xlwings里面的一些函数用起来还是比较方便的,能够看懂大概用法,如果你不会VBA的话也没关系
xlwings英文版文档:http://docs.xlwings.org/en/stable/api.html
也很简单、简洁,英语很low的我也能看懂,不行就百度翻译一下,基本都可以理解怎么使用,而且这个库也一直在更新,长期来看还是比较靠谱的
#以下代码在jupyter notebook 里面运行,打印时不用print
import xlwings as xw #引入xlwings模块
#创建excel程序对象,这里有点类似VBA,不过这里也使很多人感到困惑
#如果你理解了在excel文件里可以直接打开其他excel文件过程,你基本上就可以理解这个(菜单文件---打开)
app = xw.App(visible=True,add_book=False)
wb = app.books.open('01.xlsx') #指定要打开的文件
wb.sheets #查看里面的sheet
sht1=wb.sheets['grv'] #可以直接把一个sheet赋值给一个对象,相当于引用
sht2=wb.sheets.add('python',after='grv') #添加一个新的sheet,在sheet(grv)后面,并命名为python
sht1[0,0].value #打印出sheet(grv)里面 A1单元格的值,这里一定要用 .value ,与vba里面的cells(1,1)有所区别,但这里相对VBA引用相对更方便,模块里面对应excel的行、列均从0开始,这与python里面其他序列下标保持一致
sht2[0,0].value=sht1[0,0].value #可以直接引用并赋值
i=1
j=1
sht1[i,j].value #这里也可以直接用变量,在程序里面都是用变量来引用单元格
import pandas as pd #加载pandas模块
import numpy as np #加载numpy模块,这里加载两个模块目的用来生成一些数据,后面数据可以直接写入excel,不用pd.to_excel
data=np.arange(0,100).reshape(20,5)
data=pd.DataFrame(data,columns=list('ABCDE')) #创建一个数据框
sht2[1,0].value=data #可以直接把数据框写入excel,这里的.value不能省略
wb.save() #保存工作簿
wb.close() #关闭工作簿
app.quit() #退出excel程序,经测试excel程序确实退出,但任务管理器里面的进程还在运行,并没有完全退出,此处建议用下面的kill
app.kill() #完全退出excel程序,后台没有进程在运行
注意的点:
- 引用单元格数据时要加.value,这里和VBA的cell用法有所区别,cell默认就是.value,而这里不是
- 退出excel时,建议用app.kill()来终止进程
以上是自己实践中遇到的一些点,分享出来供大家参考学习,欢迎关注微信公众号DataShare,不定期分享干货
作者:数据人阿多
背景
Lambda匿名函数在Python中经常出现,小巧切灵活,使用起来特别方便,但是小编建议大家少使用,最好多写几行代码,自定义个函数。
既然Python中存在Lambda匿名函数,那么小编本着存在即合理的原则,还是介绍一下,本篇文章翻译自《Lambda Functions in Python》,分享出来供大家参考学习
原文地址:https://www.clcoding.com/2024/03/lambda-functions-in-python.html
案例1:基本语法
常规函数
def add(x, y):
return x + y
匿名函数
lambda_add = lambda x, y: x + y
调用2种类型函数
print(add(3, 5)) #8
print(lambda_add(3, 5)) #8
案例2:在sorted排序函数中使用匿名函数
students = [("Alice", 25), ("Bob", 30), ("Charlie", 22)]
sorted_students = sorted(students, key=lambda student: student[1])
print("Sorted Students by Age:", sorted_students)
#Sorted Students by Age: [('Charlie', 22), ('Alice', 25), ('Bob', 30)]
案例3:在filter过滤函数中使用匿名函数
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print("Even Numbers:", even_numbers)
#Even Numbers: [2, 4, 6, 8]
案例4:在map函数中使用匿名函数
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
print("Squared Numbers:", squared_numbers)
#Squared Numbers: [1, 4, 9, 16, 25]
案例5:在max函数中使用匿名函数
numbers = [10, 5, 8, 20, 15]
max_number = max(numbers, key=lambda x: -x)
print("Maximum Number:", max_number)
#Maximum Number: 5
案例6:在sorted排序函数中,多个排序条件
people = [{"name": "Charlie", "age": 25},
{"name": "Bob", "age": 30},
{"name": "Alice", "age": 25}]
sorted_people = sorted(people,
key=lambda person: (person["age"], person["name"]))
print("Sorted People:", sorted_people)
#Sorted People: [{'name': 'Alice', 'age': 25}, {'name': 'Charlie', 'age': 25}, {'name': 'Bob', 'age': 30}]
案例7:在reduce函数中使用匿名函数
from functools import reduce
numbers = [1, 2, 3, 4, 5]
product = reduce(lambda x, y: x * y, numbers)
print("Product of Numbers:", product)
#Product of Numbers: 120
案例8:在条件表达式中使用匿名函数
numbers = [10, 5, 8, 20, 15]
filtered_and_squared = list(map(lambda x: x**2 if x % 2 == 0 else x, numbers))
print("Filtered and Squared Numbers:", filtered_and_squared)
#Filtered and Squared Numbers: [100, 5, 64, 400, 15]
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
前言
Python里面在数据处理、数据分析、数据可视化、数据挖掘等领域,用到的库有Numpy、Pandas、Matplotlib、Sklearn、Scipy等,这些库都是建立在Numpy基础之上,因此学习Numpy是每个Pythoner进入数据科学领取的必经之路。
在练习Numpy时肯定离不开数据,可以随机生成,也可以自己去搜集,这些都可以,但是在手机发达的今天,还有一种数据更容易直接获得、而且还很真实,这就是照片,RGB值,下面就来详细介绍怎么把照片读取为Numpy数组。
通过读取照片获得Numpy数组
读取照片的库有很多,这里推荐大家直接用PIL(PIL即Python Imaging Library,也即为我们所称的Pillow,是一个很流行的图像库,它比opencv更为轻巧,正因如此,它深受大众的喜爱。)
以下面这张《家乡的风力发电基地.jpg》为案例,来介绍怎么把照片变为Numpy数组。

- 导入相关的库
import numpy as np
from PIL import Image
- 读取照片
img = Image.open('家乡的风力发电基地.jpg')
img #显示照片
- 查看照片的属性
print(img.format)
print(img.size) #(w,h) 宽,高
print(img.mode)
- 转换为Numpy数组
img_array=np.array(img)
img_array
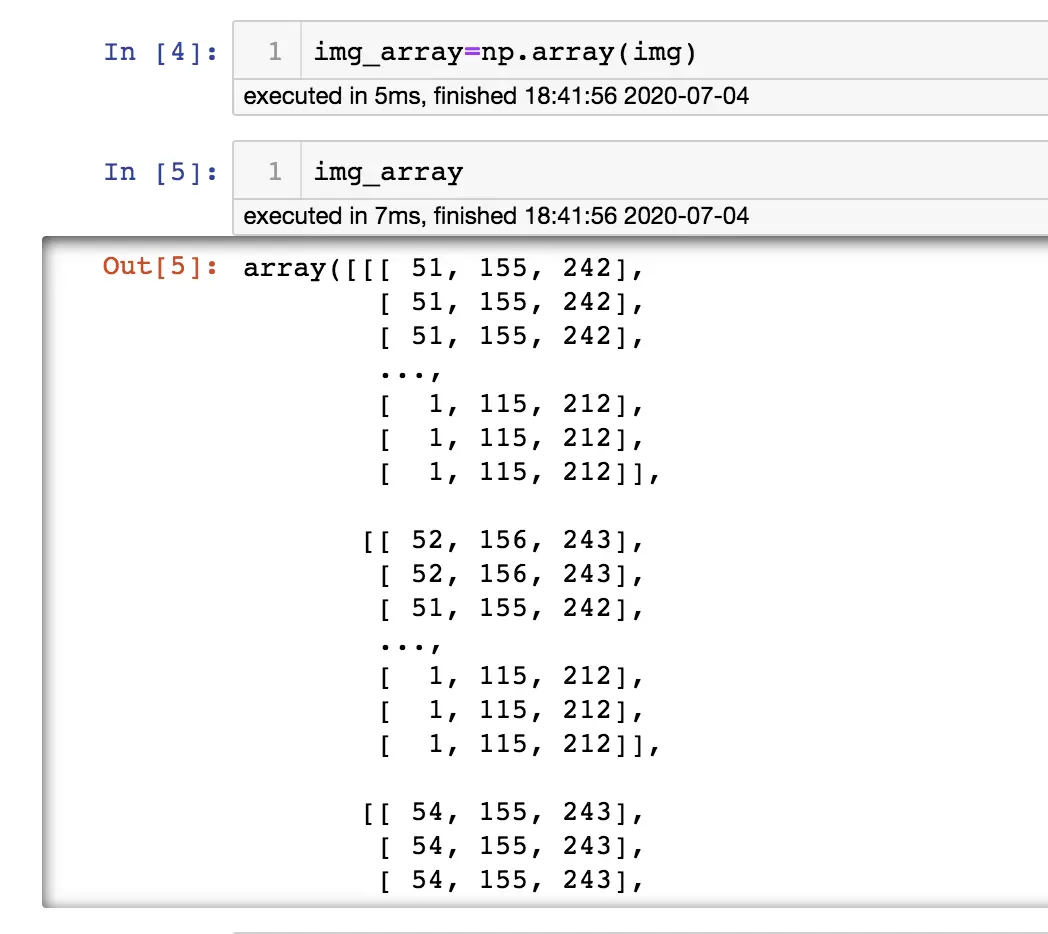
- 查看Numpy数组属性
print(img_array.shape) #(height,width,channel) 高,宽,通道数(RGB值)
print(img_array.dtype) #数据类型
print(img_array.size) #数组中所有元素的个数 400*600*3

- 开始你的各种练习
这里简单展示一下,转为RGB三列数据
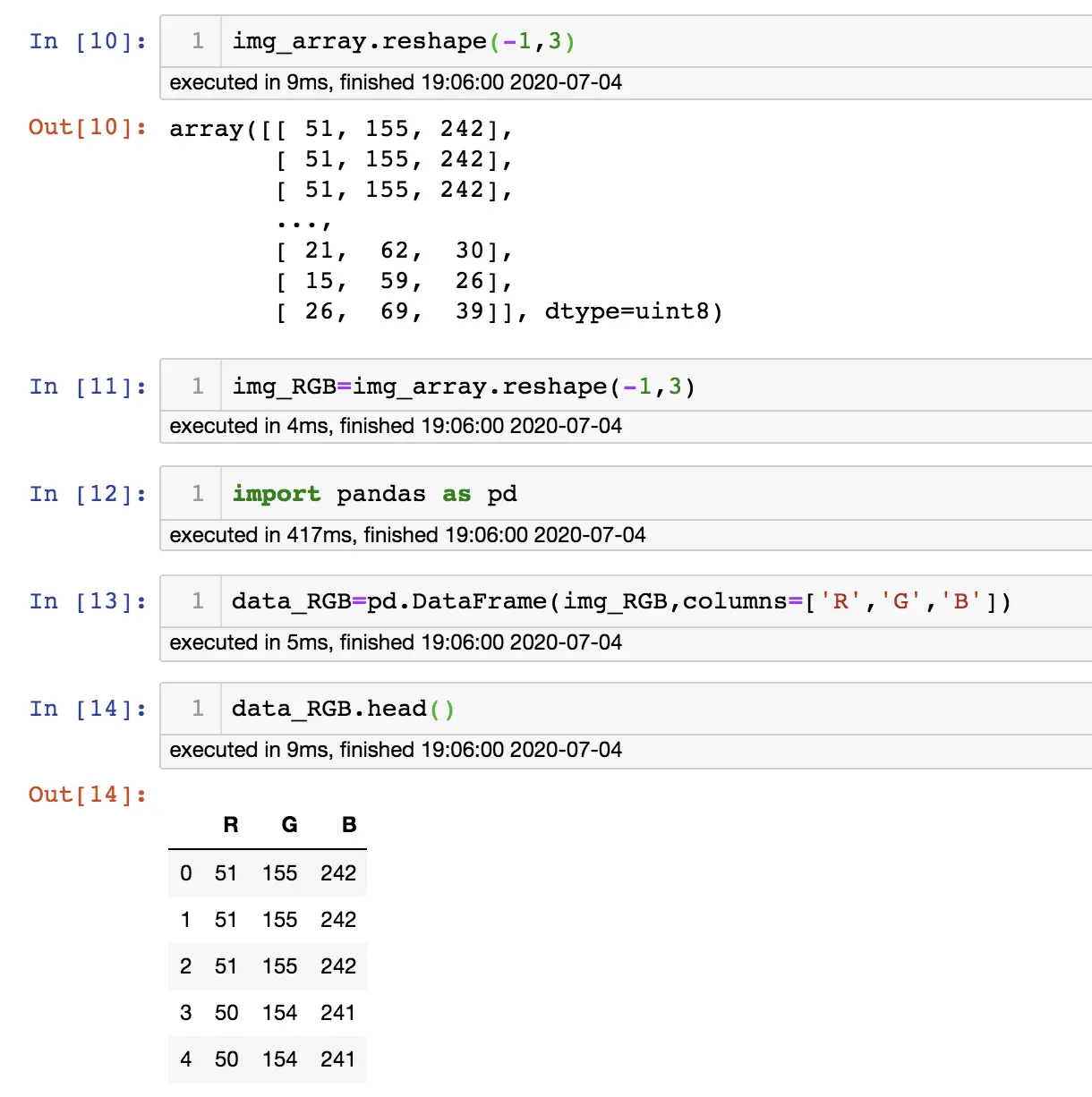
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号,不定期分享干货
作者:数据人阿多
背景
假如全国所有的酒店/民宿经纬度信息已知的情况下,基于当前位置,怎么快速计算附近5KM内的酒店/民宿呢?现实中有大量的这种业务场景,需要快速计算2点间的地球距离
本篇文章 不从地理的知识进行优化 ,比如当前的定位是在北京,那么没有必要去计算与上海的酒店/民宿距离;只从数据计算角度 来进行优化,看看性能大约能提升多少
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import pandas as pd
print("pandas 版本:",pd.__version__)
#pandas 版本: 2.2.2
模拟数据
本次小编用全国 10W个位置点来进行模拟
data=pd.read_excel('data_test.xlsx',
sheet_name='data',
engine='calamine')
print(len(data)) #100000
print(data.head())
#id longitude latitude
0 id1 114.657838 30.077734
1 id2 105.150585 27.599929
2 id3 97.396759 22.805973
3 id4 124.282532 41.283089
4 id5 115.477867 23.781731
基于单点计算距离
计算当前点与每个点之间的距离
from math import sin, asin, cos, radians, fabs, sqrt
EARTH_RADIUS = 6371 # 地球平均半径大约6371km
def hav(theta):
s = sin(theta / 2)
return s * s
def get_distance_hav(lat0, lng0, lat1, lng1):
# 用haversine公式计算球面两点间的距离
# 经纬度转换成弧度
lat0 = radians(lat0)
lat1 = radians(lat1)
lng0 = radians(lng0)
lng1 = radians(lng1)
dlng = fabs(lng0 - lng1)
dlat = fabs(lat0 - lat1)
h = hav(dlat) + cos(lat0) * cos(lat1) * hav(dlng)
distance = 2 * EARTH_RADIUS * asin(sqrt(h)) # km
return distance
下面进行测速看看花费多长时间,在jupyter中测试的
%%timeit -n10 -r10
# import timeit
result={}
for row1 in data.itertuples():
# start=time.time()
near_id=[]
for row2 in data.itertuples():
if row1.id != row2.id \
and get_distance_hav(row1.latitude,
row1.longitude,
row2.latitude,
row2.longitude)<=10.0:
near_id.append(row2.id)
result[row1.id]=near_id
# print(f"耗时:{time.time()-start}秒")
break
测速结果: 运行一次大约需要 412ms
412 ms ± 5.41 ms per loop (mean ± std. dev. of 10 runs, 10 loops each)
基于 numpy 矢量化计算距离
利用 numpy 矢量化来计算,一次计算当前点与所有点的距离,numpy 底层基于 C语言开发,可以加速运算
import numpy as np
EARTH_RADIUS = 6371 # 地球平均半径大约6371km
def hav(theta):
s = np.sin(theta / 2)
return s * s
def get_distance_hav_vectorized(lat0, lng0, lat1, lng1):
# 用haversine公式计算球面两点间的距离
# 经纬度转换成弧度
lat0 = np.radians(lat0)
lat1 = np.radians(lat1)
lng0 = np.radians(lng0)
lng1 = np.radians(lng1)
dlng = np.abs(lng0 - lng1)
dlat = np.abs(lat0 - lat1)
h = hav(dlat) + np.cos(lat0) * np.cos(lat1) * hav(dlng)
distance = 2 * EARTH_RADIUS * np.arcsin(np.sqrt(h)) # km
return distance
下面进行测速看看花费多长时间,在jupyter中测试的
%%timeit -n10 -r100
result={}
# 对 data 逐行处理
for row in data.itertuples():
# start = time.time()
t = get_distance_hav_vectorized(row.latitude,
row.longitude,
data['latitude'],
data['longitude'])
result[row.id] = ','.join(data.loc[(0<t) & (t<=10.0),'id'].to_list())
break
# print(f"耗时:{time.time() - start}秒")
测速结果: 运行一次大约需要 7ms,相比单点计算速度提升了大约 59倍
6.72 ms ± 417 µs per loop (mean ± std. dev. of 100 runs, 10 loops each)
基于 polars 矢量化计算距离
利用 polars 矢量化来计算,polars 底层基于 Rust 语言开发,也可以加速运算
import polars as pl
print(pl.__version__) #1.2.1
data_pl = pl.read_excel('data_test.xlsx',sheet_name='data')
import math
EARTH_RADIUS = 6371 # 地球平均半径大约6371km
def hav_pl(theta):
s = (theta / 2).sin()
return s * s
def get_distance_hav_vectorized_pl(lat0, lng0, lat1, lng1):
# 用haversine公式计算球面两点间的距离
# 经纬度转换成弧度
lat0 = math.radians(lat0)
lng0 = math.radians(lng0)
lat1=lat1.to_frame().select(pl.col("latitude").radians())
lng1=lng1.to_frame().select(pl.col("longitude").radians())
dlng = (lng0 - lng1.to_series()).abs()
dlat = (lat0 - lat1.to_series()).abs()
h = hav_pl(dlat) + math.cos(lat0) * lat1.to_series().cos() * hav_pl(dlng)
distance = 2 * EARTH_RADIUS * h.sqrt().arcsin() # km
return distance
下面进行测速看看花费多长时间,在jupyter中测试的
%%timeit -n10 -r100
result={}
for row in data_pl.iter_rows(named=True):
t = get_distance_hav_vectorized_pl(row['latitude'],
row['longitude'],
data_pl['latitude'],
data_pl['longitude'])
result[row['id']] = ','.join(data_pl.filter((t>0) & (t<=5))['id'].to_list())
break
测速结果:
运行多次后,测速结果稳定在 4.1ms左右,相比 numpy 略好一些
4.07 ms ± 162 µs per loop (mean ± std. dev. of 100 runs, 10 loops each)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
把数据导出到Excel中时,有时需要对列的顺序进行调整,按业务需求进行排列,并且字段名字不能是英文,这样方便业务人员查看与理解数据,在 pandas 中有相应的函数可以满足以上2个要求,让我们来学习一下吧
重排列:pandas.DataFrame.reindex
列重名:pandas.DataFrame.rename
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import pandas as pd
print("pandas 版本:",pd.__version__)
#pandas 版本: 2.2.2
模拟数据
data = pd.read_excel('演示数据.xlsx')
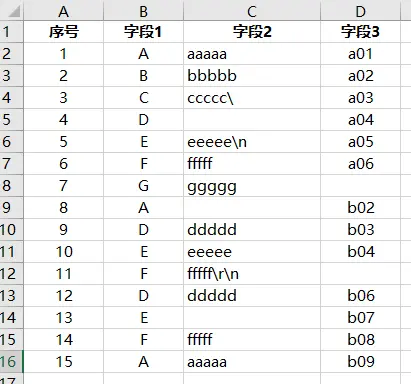
用 reindex 对字段顺序,重新排序
new_columns=['序号','字段3','字段1','字段2']
data_reindex=data.reindex(columns=new_columns)
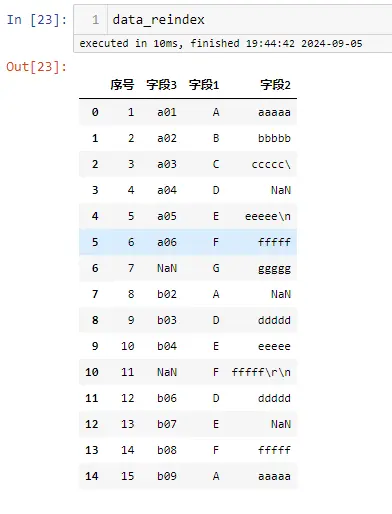
用 rename 对字段重新命名
方法1
columns_mapper ={
'序号':'index',
'字段1':'col1',
'字段2':'col2',
'字段3':'col3'
}
data_rename1 = data.rename(columns=columns_mapper)
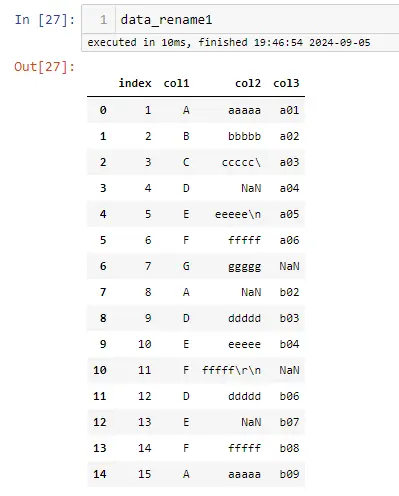
方法2
def fn_columns_mapper(col):
if '字段' in col:
new_col = col.replace('字段','col')
else:
new_col = 'col0'
return new_col
data_rename2 = data.rename(columns=fn_columns_mapper)
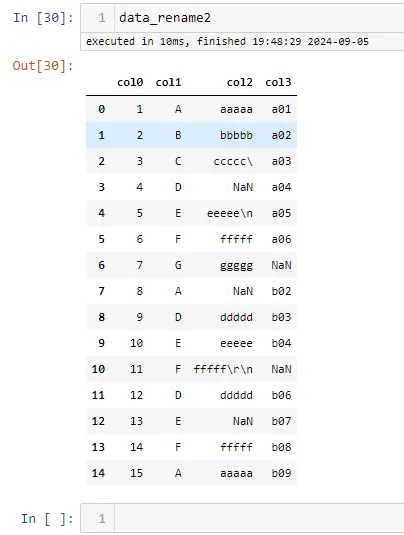
历史相关文章
- Python-pandas遍历行数据的2种方法
- Python-利用pandas对数据进行特定排序
- Python-pandas-2-0-初探
- Python-pandas-str-replace-不起作用
- Python数据处理中-pd-concat-与-pd-merge-区别
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在日常数据处理中,你是否遇到过这样的困扰?😫
当你使用 pandas 的 to_excel 方法导出包含网址的数据时,pandas会“自作主张”地将这些URL转换为Excel可点击的超链接。这个看似贴心的功能,实际上却暗藏两个让人头疼的问题:
🚨 数量超标危机
-
Excel单个工作表最多只能容纳65,530个超链接
-
一旦超过这个限制,程序就会报错,或者更糟糕——静默丢弃超出的部分,导致数据丢失!
🚨 长度截断陷阱
-
自动转换为超链接时,Excel对URL长度有严格限制(通常为255个字符)
-
超过这个长度的链接会被无情截断,生成无效的超链接
那么,有没有办法让pandas“安分守己”,老老实实地将URL保存为普通文本呢?
答案是肯定的!本文将为你揭秘如何通过简单的设置,彻底告别这些烦恼,确保你的URL数据完整无缺地导出到Excel中。
无论你是数据分析师、爬虫工程师,还是日常需要处理大量URL的办公人员,这个技巧都将为你的工作带来极大的便利!✨
接下来,让我们一起来看看具体的实现方法……
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
import pandas as pd
print("pandas 版本:", pd.__version__)
#pandas 版本: 2.2.2
默认带url导出
默认导出Excel文件时,带URL的单元格,自动会变为超链接的形式,显示为蓝色的样式
import pandas as pd
data=pd.read_excel("url测试数据.xlsx", dtype='str', engine='openpyxl')
data.to_excel('url测试数据-默认带url导出.xlsx',index=False)

禁止URL转换
禁止URL转换后,输出的单元格是不带超链接
import pandas as pd
data=pd.read_excel("url测试数据.xlsx", dtype='str', engine='openpyxl')
with pd.ExcelWriter('url测试数据-禁止URL转换.xlsx',
engine='xlsxwriter',
engine_kwargs={'options': {'strings_to_urls': False}}
) as xlsx:
data.to_excel(xlsx,index=False)

历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
你的Hive数据库是不是也悄悄“膨胀”了?
开发过程中产生的各种中间表,日积月累,占用了大量存储空间,手动清理时却犯了难:
-
哪些表最占空间?
-
哪些表早已过时?
-
谁创建的?能不能删?
为解决这个问题,我写了一个Python脚本,能一键生成统计报表,清晰列出:
📊 表存储大小
📅 最后修改时间
👨💻 表使用人
让你对库表情况了如指掌,精准清理,彻底告别存储焦虑!
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
统计结果示例

完整代码
"""
Hive表存储信息统计脚本 - 基于HDFS路径检查
"""
import subprocess
import re
import datetime
import logging
import sys
import os
from typing import Dict, List, Tuple, Optional
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("hive_table_stats_hdfs.log", encoding='utf-8'),
logging.StreamHandler(sys.stdout)
]
)
logger = logging.getLogger(__name__)
class HiveTableStatsHDFS:
def __init__(self, hdfs_cmd: str = "hadoop fs"):
self.hdfs_cmd = hdfs_cmd
# self.warehouse_base = "/user/hive/warehouse"
def execute_hdfs_command(self, command: str) -> Tuple[bool, str]:
"""执行HDFS命令"""
try:
cmd = f"{self.hdfs_cmd} {command}"
result = subprocess.run(
cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True,
timeout=60
)
if result.returncode == 0:
return True, result.stdout.strip()
else:
logger.error(f"HDFS命令失败: {result.stderr}")
return False, result.stderr
except subprocess.TimeoutExpired:
logger.error(f"HDFS命令超时: {command}")
return False, "Command timeout"
except Exception as e:
logger.error(f"执行HDFS命令时发生异常: {e}")
return False, str(e)
def get_tables_from_database(self, db_path: str) -> List[str]:
"""获取指定数据库中的所有表"""
logger.info(f"获取数据库 {db_path} 中的表列表...")
success, output = self.execute_hdfs_command(f"-ls {db_path}")
if not success:
logger.warning(f"无法访问数据库路径: {db_path}")
return []
tables = []
for line in output.split('\n'):
if line.startswith('d'):
parts = line.split()
if len(parts) >= 8:
table_path = parts[-1]
table_name = table_path.split('/')[-1]
tables.append((table_name, table_path))
logger.info(f"在 {db_path} 中找到 {len(tables)} 张表")
return tables
def get_table_size(self, table_path: str) -> Optional[str]:
"""获取表的存储大小"""
success, output = self.execute_hdfs_command(f"-du -s -h {table_path}")
if not success:
return None
# 解析输出,获取总大小
if output:
parts = output.split()
if len(parts) == 5:
return parts[0], parts[1] # 返回人类可读的大小、字节类型
if len(parts) == 3:
return parts[0], 'B' # 返回人类可读的大小、字节类型
return None
def get_table_details(self, table_path: str) -> Tuple[Optional[str], Optional[str], bool]:
"""获取表的详细信息:最后修改时间、修改人员、是否分区表"""
success, output = self.execute_hdfs_command(f"-ls -t {table_path} | head -n 5")
if not success:
return None, None, False
lines = output.strip().split('\n')
if not lines:
return None, None, False
# 获取第一条记录(最新的)
if 'Found' in lines[0]:
first_line = lines[1]
else:
first_line = lines[0]
parts = first_line.split()
if len(parts) < 8:
return None, None, False
# 解析修改时间和修改人员
mod_time = f"{parts[5]} {parts[6]}"
modifier = parts[2] # 文件所有者
# 检查是否为分区表:查看表目录下是否有子目录
is_partitioned = False
if parts[0].startswith('d'):
# 如果有子目录,则认为是分区表
is_partitioned = True
return modifier, mod_time, is_partitioned
def get_all_table_stats(self, specific_database: str = None) -> List[Dict]:
"""获取所有表的统计信息"""
results = []
# 数据库名字
db_name = specific_database.split('/')[-1].replace('.db','')
# 获取数据库路径
tables = self.get_tables_from_database(specific_database)
total_tables = len(tables)
logger.info(f"开始处理数据库 {db_name} 中的 {len(tables)} 张表...")
for i, (table_name, table_path) in enumerate(tables, 1):
logger.info(f"处理表 [{i}/{len(tables)}]: {db_name}.{table_name}")
try:
# 获取表大小
size_1, size_2 = self.get_table_size(table_path)
# 获取表详细信息
modifier, mod_time, is_partitioned = self.get_table_details(table_path)
table_info = {
'table_name': f'{db_name}.{table_name}',
'storage_size_1': float(size_1),
'storage_size_2': size_2,
'storage_location': table_path,
'last_modification_date': mod_time or "未知",
'last_modifier': modifier or "未知",
'is_partitioned': '是' if is_partitioned else '否'
}
results.append(table_info)
except Exception as e:
logger.error(f"处理表 {db_name}.{table_name} 时发生错误: {e}")
error_info = {
'database': db_name,
'table_name': table_name,
'storage_size': '错误',
'storage_location': table_path,
'last_modification_date': '错误',
'last_modifier': '错误',
'is_partitioned': '错误'
}
results.append(error_info)
logger.info(f"总共处理了 {len(results)} 张表")
return results
def export_to_excel(self, data: List[Dict], filename: str = None):
"""导出结果到Excel文件"""
try:
import pandas as pd
pd_data = pd.DataFrame(data)
# 按大小进行排序
key_type={'T':1,'G':2,'M':3,'K':4}
# 创建临时列用于排序
pd_data['temp_storage_size_2'] = pd_data['storage_size_2'].map(key_type)
pd_data_sorted = pd_data.sort_values(
by=['temp_storage_size_2','storage_size_1'],
ascending=[True,False]
)
# 删除临时列
pd_data_sorted = pd_data_sorted.drop('temp_storage_size_2', axis=1)
# 重命名字段
dic_columns={
"table_name":"表名",
"storage_size_1":"大小-1",
"storage_size_2":"大小-2",
"storage_location":"存储位置",
"last_modification_date":"最后一次修改时间",
"last_modifier":"人员",
"is_partitioned":"是否分区"
}
pd_data_sorted_rename = pd_data_sorted.rename(columns=dic_columns)
pd_data_sorted_rename.to_excel(filename, index=False, )
logger.info(f"结果已导出到: {filename}")
return True
except ModuleNotFoundError as e:
logger.error(f"没有安装 pandas : {e}")
return False
except Exception as e:
logger.error(f"导出失败: {e}")
return False
def main():
"""主函数"""
# 手动指定数据库目录
specific_db = '/user/hive/warehouse/warehouse.db'
# 创建统计对象
stats = HiveTableStatsHDFS()
try:
# 获取表统计信息
print(f"\n开始统计表信息...")
results = stats.get_all_table_stats(specific_db)
# 导出到Excel
stats.export_to_excel(results, 'hdfs_hive_table_statistics.xlsx')
print("\n统计完成! 请查看日志文件 'hive_table_stats_hdfs.log' 获取详细信息")
except KeyboardInterrupt:
print("\n用户中断操作")
except Exception as e:
print(f"\n执行过程中发生错误: {e}")
logger.exception("主程序异常")
if __name__ == "__main__":
main()
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
OpenList ------ “网盘聚合器” 近日,一个名为OpenList的开源网盘聚合神器,正成为越来越多网盘管理爱好者的新选择。它源于曾经广受欢迎的Alist项目,却在该项目走向商业化后,OpenList项目应运更生,由社区自发“接棒”继续前行
本篇文章介绍小编搜集来的一些夸克网盘资源,基于OpenList 批量下载到本地
资源小编也在这里分享一下:
- 凯叔讲故事大全(50G):https://pan.quark.cn/s/8841430d1ef6
- python电子书:https://pan.quark.cn/s/f8653098c1d4
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
搭建OpenList
小编这里是在一台空闲的linux服务器安装
- 安装 OpenList 文档:https://doc.oplist.org/guide/installation/script
curl -fsSL https://res.oplist.org/script/v4.sh > install-openlist-v4.sh && sudo bash install-openlist-v4.sh
- 添加夸克存储文档:https://doc.oplist.org/guide/drivers/quark,需要通过浏览器获取 Cookie,小编这里的挂载路径为
/kuake,后续在下载网盘中的文件时,需要提供该路径,配置时开启Web代理,WebDAV策略:本地代理
下载夸克资源完整代码
"""
===========================
@Time : 2026/1/3 19:41
@File : openlist
@Software: PyCharm
@Platform: Win10
@Author : 数据人阿多
===========================
"""
import time
import requests
import json
import pandas as pd
from pathlib import Path
class OpenList:
def __init__(self,username,password,ip,port):
self.username = username
self.password = password
self.ip = ip
self.port = port
self._login()
def _login(self):
url = f'http://{self.ip}:{self.port}/api/auth/login'
payload = json.dumps({
"username": self.username,
"password": self.password,
# "otp_code": otp_code
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
self.token=response.json()['data']['token']
def path_files(self,path,pages):
api_url = f'http://{self.ip}:{self.port}/api/fs/list'
pages_content_files = []
pages_content_dirs = []
for page in range(1,pages+1):
page_content=self.path_every_page(page, api_url, path)
if page_content:
for page_detail in page_content:
if page_detail['is_dir']:
pages_content_dirs.append(page_detail)
else:
pages_content_files.append(page_detail)
else:
print(f"获取路径 {path} 数据完成!")
break
return pd.DataFrame(pages_content_files),pd.DataFrame(pages_content_dirs)
def path_every_page(self, page, api_url, path, per_page=100):
payload = json.dumps({
"path": path,
"password": "",
"refresh": False,
"page": page,
"per_page": per_page
})
headers = {
'Authorization': self.token,
'Content-Type': 'application/json'
}
print(f"开始获取 {path} ,第{page:02}页数据")
response = requests.request("POST", api_url, headers=headers, data=payload)
return response.json()['data']['content']
def download_file(self, url, filename, local_path, retry=3):
for attempt in range(retry + 1): # 尝试次数 = 重试次数 + 1
try:
response = requests.get(url, stream=True, timeout=30)
# 检查请求是否成功
if response.status_code == 200:
total_size = int(response.headers.get('content-length', 0))
downloaded = 0
with open(local_path / filename, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
downloaded += len(chunk)
# 可选:显示下载进度
if total_size > 0:
percent = (downloaded / total_size) * 100
print(f"\r下载进度: {percent:.1f}%", end='')
print(f"\n下载成功: {filename}")
return True
elif response.status_code == 404:
print(f"文件不存在: {url}")
return False # 404错误不需要重试
else:
print(f"下载失败,状态码: {response.status_code}")
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
# 如果不是最后一次尝试,等待后重试
if attempt < retry:
wait_time = 2 ** attempt # 指数退避:1, 2, 4秒...
print(f"等待 {wait_time} 秒后重试... (剩余尝试: {retry - attempt})")
time.sleep(wait_time)
print(f"达到最大重试次数,下载失败: {filename}")
return False
def download_path_files(self, path, local_path, pages=10):
path_files, path_dirs = self.path_files(path,pages)
total_path_files=len(path_files)
total_path_dirs=len(path_dirs)
print(f"目录 {path} 下共有{total_path_files}个文件, 有{total_path_dirs}个目录")
if total_path_files:
print(f"开始下载目录 {path} 下的文件")
for row in path_files.iterrows():
# print(row)
filename = row[1]['name']
sign = row[1]['sign']
url = f'http://{self.ip}:{self.port}/p{path}/{filename}?sign={sign}'
print(f"开始下载[{row[0]+1}/{total_path_files}]:{filename}")
self.download_file(url, filename, local_path)
if total_path_dirs:
for row_dir in path_dirs.iterrows():
path_dir = path + '/' + row_dir[1]['name']
local_path_subdir = local_path / row_dir[1]['name']
if not local_path_subdir.exists():
local_path_subdir.mkdir()
print(f"\n开始获取目录内容:{path_dir} ")
self.download_path_files(path_dir, local_path_subdir)
if __name__ == '__main__':
openlist = OpenList('admin','1234566','1.1.1.1','1024')
# 获取当前路径
current_path = Path.cwd()
cloud_path = '/kuake/来自:分享/凯叔讲故事-历史集'
path = current_path / 'ks'
if not path.exists():
path.mkdir()
openlist.download_path_files(cloud_path, path)
提供linux服务器的ip、端口、用户名、密码,以及想下载的文件夹,运行后就可以下载到本地
API文档:https://fox.oplist.org/
工具与内容
在数字化生活中,我们常常面对两类选择:一个是“用什么工具”,另一个是“如何对待内容”
今天向大家介绍的 OpenList,正是众多网盘管理工具中的一个。市面上同类工具不少,你可以根据偏好自由选用,但 OpenList 背后那份 坚持开源、保持透明 的精神,尤其值得欣赏——这不仅关乎技术,更关乎一种共享、共建的社区态度。
工具本质是桥梁,最终的价值仍沉淀于内容。小编始终鼓励,在条件允许的情况下,通过付费订阅等方式支持原创作者。正是这些支持,才能让创作得以延续,让高质量的内容不断涌现。
当然,小编也观察到,有些本应开放的资源,在流转中被人为加上了不必要的门槛;看一部剧、听一首歌,往往需要跨过层层会员壁垒。当资源被过度封装,能够帮助我们更便捷、更自由地管理个人数字资产的工具,便显出了它的意义。
好的工具,应当让人更靠近内容本身,而不是更远 选择什么样的工具,其实也在表达我们如何看待内容、尊重创作以及守护自己本就应有的数字便利。
如果你也认同这样的理念,不妨尝试一下 OpenList,或者只是单纯思考一下:我们手中的工具,是否真的让我们离想看的世界更近了一点?
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在大数据处理时,基本都是基于Hadoop集群进行操作,数据相关人员在开发数仓或做临时业务需求时,基本都是利用 hive,写 sql 进行数据处理与统计分析,但是 sql 在处理一些复杂业务逻辑时会比较复杂,本文通过基于 pyhive 操作 hive,把 sql 的查询结果转为 pandas 中的 DataFrame 数据框,用于后续数据分析
pyhive 库类似于pymysql库,都是 Python 中与不同数据库系统进行交互的库。它们都提供了简洁的接口来执行 SQL 查询,处理结果集,以及管理连接
小编环境
import sys
print('python 版本:',sys.version)
#python 版本: 3.6.8 (default, Aug 7 2019, 17:28:10)
#[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)]
import pyhive
print('pyhive 版本:',pyhive.__version__)
#pyhive 版本: 0.6.3
因是在服务器集群操作,python版本较低
示例
#导入库
from pyhive import hive
import pandas as pd
def generate_sql(table,dt):
sql = f"""
select id,split(location,',')[1] as longitude,split(location,',')[0] as latitude
from {table}
where dt='{dt}'
"""
return sql
# 建立连接
conn=hive.connect(
host = '10.20.1.1',
port = 10000,
auth="CUSTOM",
database = 'bigdata',
username='datashare',
password = 'datashare'
)
# 创建游标
cur =conn.cursor()
# 执行查询
sql=generate_sql('tb_test','20241114')
cur.execute(sql)
#获取列名
cols=[]
for col in cur.description:
cols.append(col[0])
#把sql结果转换为DataFrame
data = pd.DataFrame(cur.fetchall(),columns=cols)
print(data.head())
#借助pandas对数据进行一些处理
#。。。。。。
#数据保存为Excel
data.to_excel('data.xlsx')
# 关闭连接
cursor.close()
connection.close()
这样通过python一站式对数据进行操作,可以很大程度提升工作效率,后续还可以结合sklearn、pytorch等,对数据进行机器学习等相关操作
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多 日期:2026年2月28日
引言:AI时代的计算新范式
随着人工智能和大模型技术的飞速发展,数据处理的需求已经超越了传统ETL的范畴。现代AI工作流需要处理的不再仅仅是结构化表格数据,而是包含图像、视频、音频、文本向量的多模态数据。在这种背景下,一套基于Python原生体验、能够弹性扩展、且深度优化AI负载的分布式计算栈正在崛起
本文将深入探讨以Ray为分布式底层、Daft为分布式计算引擎、Lance为列式存储格式的现代Python全栈方案,并对比传统Hadoop+Spark生态,分析其优劣势
核心技术解析
1. Ray:通用的分布式调度内核
Ray起源于UC Berkeley RISELab,是一个用于构建和运行分布式应用的开源框架。它的设计目标是将分布式计算的复杂性隐藏起来,提供从单机到集群的无缝扩展体验
核心特性:
- 统一的Python API:通过
@ray.remote装饰器,可以轻松将Python函数转化为分布式任务(Task)或将类转化为分布式Actor - 动态任务图:支持细粒度的、依赖复杂的任务调度,非常适合强化学习、模型训练等迭代式算法
- 生态丰富:Ray不仅是一个内核,还构建了完整的AI生态库,包括用于数据加载的Ray Data、分布式训练的Ray Train、超参调优的Ray Tune、模型服务的Ray Serve以及强化学习库RLlib
- 语言无关性:虽然核心API是Python,但Ray架构支持跨语言,底层采用C++构建,保证高性能
在实际部署中,Ray集群由Head节点和若干Worker节点组成。Head节点负责全局调度和状态维护,Worker节点执行具体的计算任务 。开发者只需在代码中调用ray.init(),即可连接本地或远程集群,无需关心底层的节点通信和资源管理

2. Daft:原生多模态分布式计算引擎
Daft是一个新兴的分布式DataFrame引擎,专为AI场景下的多模态数据处理而设计。它采用Rust编写核心执行引擎,通过Python API提供类似Pandas的使用体验,但底层支持分布式执行
核心特性:
- 多模态原生支持:Daft内置了
image、video、audio、embedding等数据类型,可以直接在DataFrame中处理非结构化数据,并执行图像解码、向量相似度计算等操作,无需繁琐的序列化转换 - Pipeline执行模型:与Spark的批处理模型不同,Daft采用Pipeline执行模型(类似流式计算),数据在算子间以微批(micro-batch)形式流动,降低了延迟,提高了CPU/GPU利用率
- 异构资源调度:Daft可以根据算子类型(如图像解码用CPU,Embedding用GPU)自动将任务调度到合适的硬件上,实现同一工作流中CPU与GPU的无缝协作
- 基于Ray的分布式执行:Daft的分布式版本名为Flotilla,它构建在Ray之上。每个Ray Worker节点上运行一个常驻的Swordfish执行引擎,负责执行本地计算。这种设计使得Daft既能享受Ray的弹性调度能力,又能保持Rust核心的高性能
3. Lance:面向AI的列式数据格式
Lance是一种开源的列式数据格式,可以看作是对Parquet的现代化重构,专门优化了AI工作负载。它不仅存储张量数据(如Embedding向量),还管理数据的版本和元数据
核心特性:
- 极速随机访问:得益于其底层的结构化设计,Lance支持零拷贝(zero-copy)读取,随机访问(如按行取数据)性能比Parquet快100倍以上,这对于训练时的小批量随机读取至关重要
- 内置向量索引:Lance原生支持向量索引(如IVF-PQ),可直接在存储层进行高效的近似最近邻(ANN)搜索,无需引入专门的向量数据库
- 自动版本控制:每次写入都会自动生成一个新的数据集版本,支持时间旅行(Time Travel),确保实验的可复现性
- 生态系统集成:Lance与Apache Arrow深度集成,可以零拷贝地与Pandas、DuckDB、Daft等内存格式交互
三者的协同工作流
Ray、Daft、Lance三者构成了一个从存储、计算到调度的完整闭环
架构图示:
- 存储层:Lance 格式,存放原始多模态数据(图像、文本、向量)及特征
- 计算引擎:Daft (基于Ray运行),负责读取Lance数据,执行ETL、特征工程、模型推理预处理
- 调度层:Ray Core/AIR,负责任务分发、资源管理和库的集成(如Train/Tune)
- 应用层:PyTorch/TensorFlow (通过Ray Train),直接消费Daft处理后的数据流
典型代码示例:
以下示例展示了如何利用Daft读取Lance数据集,进行向量相似度搜索,并进行分布式处理
import daft
import ray
from daft.io import IOConfig, S3Config
# 1. 初始化Ray (如果未在集群环境中自动连接)
ray.init(address="auto")
# 2. 配置S3存储访问 (假设Lance数据存放在S3)
io_config = IOConfig(s3=S3Config(region_name="us-west-2", anonymous=True))
# 3. 使用Daft分布式读取Lance数据集,并执行向量搜索
# 底层Daft会自动利用Ray集群进行分布式扫描
df = daft.read_lance(
"s3://my-bucket/lance/image_embeddings",
io_config=io_config,
# 直接在存储层进行向量近邻搜索 (Lance特性)
default_scan_options={
"nearest": {
"column": "embedding", # 向量列名
"q": query_vector, # 查询向量
"k": 10, # 返回最相似的10条
}
}
)
# 4. 继续在Daft DataFrame中进行后续处理
# 例如:过滤、连接元数据、应用Python UDF
df = df.with_column(
"image_path",
df["image_uri"].url.download() # Daft的URL处理原生函数
)
# 5. 定义一个使用GPU的UDF,对图像进行预处理
@daft.udf(return_dtype=daft.DataType.tensor(daft.DataType.float32()))
def preprocess_image(img_batch):
# 这里可以调用PyTorch的 transforms
# 假设img_batch是图片字节流
processed = [transform(image) for image in img_batch]
return processed
df = df.with_column("processed_tensor", preprocess_image(df["image_data"]))
# 6. 触发计算并显示结果 (分布式执行)
df.show(5)
在上述流程中,Daft的read_lance操作在Ray集群上被拆分成多个并行任务,每个任务读取Lance文件的不同片段(Fragment)。Lance的高效索引和列式存储确保了I/O开销最小化。UDF函数preprocess_image如果标记了GPU资源,Daft会协同Ray将其调度到具有GPU的节点上执行
与Hadoop + Spark生态的对比
Hadoop + Spark是过去十年大数据处理的标杆。Hadoop提供分布式文件系统(HDFS)和资源调度(YARN),Spark提供内存计算能力。下面我们将这套经典组合与Ray+Daft+Lance进行对比
1. 架构与设计哲学对比
| 维度 | Hadoop + Spark 生态 | Ray + Daft + Lance 生态 |
|---|---|---|
| 设计初衷 | 处理大规模结构化数据(如日志、交易记录)的批处理。 | 处理多模态数据(图像、视频、向量)的AI工作负载。 |
| 编程模型 | 以JVM(Scala/Java)为核心,Python API(PySpark)作为 wrapper。 | 原生Python优先,Rust内核,提供真正的Pythonic体验。 |
| 调度粒度 | 粗粒度调度(Stage),基于DAG,任务通常涉及整个数据集的分区。 | 细粒度任务并行,支持Actor模型,适合有状态计算和微服务化。 |
| 数据格式 | 推崇Parquet作为列式存储,但处理非结构化数据需额外序列化。 | Lance作为一等公民,原生支持向量和多模态数据类型。 |
| 资源异构 | 主要通过YARN或Kubernetes管理CPU和内存,对GPU支持需额外插件(如Spark-RAPIDS)。 | 原生支持GPU资源声明,可将特定算子(如UDF)调度到GPU上。 |
2. 优劣势详细对比
Spark的优势
- 成熟与稳定:经过十余年发展,拥有最广泛的用户群和故障模式库,是许多大型企业的默认选择
- SQL支持完善:Spark SQL是业界标准,具有强大的ANSI SQL支持和复杂的查询优化器(Catalyst),非常适合BI报表和数仓ETL
- 数据源生态丰富:几乎可以连接任何数据源(数据库、数据湖、消息队列),连接器生态非常庞大
- 统一的批流一体:Structured Streaming使得批处理和流处理API统一,降低了学习成本
Spark的劣势
- 非Python原生:虽然PySpark很流行,但底层通信依赖Py4J,调试复杂,且UDF性能较差(需在JVM和Python间序列化数据)
- 多模态处理笨重:处理图像或视频时,通常需要将其读入为二进制列,然后调用外部库处理,流程割裂且效率低下
- 机器学习集成度低:Spark MLlib虽然提供了常见算法,但远不如Python原生库(如scikit-learn、PyTorch)丰富,且分布式深度学习训练困难
- 调度灵活性差:Spark的调度以Stage为单位,对于需要细粒度控制或长时间运行的服务(如模型推理)支持不佳
Ray + Daft + Lance的优势
- AI原生体验:从存储(Lance)到计算(Daft)到调度(Ray),整个链条为AI/ML优化。Lance的向量检索和Daft的多模态类型直接解决了AI数据处理的痛点
- Pythonic与高性能:开发者可以完全使用Python,无需切换语言心智。底层Rust引擎保证了向量化执行的性能,UDF零拷贝避免了数据移动开销
- 端到端生态整合:Ray提供了从数据加载(Ray Data)、模型训练(Ray Train)、调优(Ray Tune)到部署(Ray Serve)的全套工具,与Daft无缝衔接
- 异构计算友好:能够自然地在一个流水线中混合使用CPU和GPU,例如在CPU上进行数据清洗,在GPU上执行Embedding提取
- 细粒度弹性:Ray的Actor模型和任务调度支持更灵活的并行模式,如强化学习中模拟器与神经网络的并行
Ray + Daft + Lance的劣势
- 生态成熟度不足:相比Spark十多年的积累,这三者组合相对年轻,周边工具链和第三方连接器不如Spark丰富
- SQL能力相对较弱:Daft虽然支持SQL,但在复杂查询优化和SQL标准兼容性上,短期内难以匹敌Spark SQL
- 运维经验少:企业中对Spark集群的运维(调优、排错)有大量成熟经验,而Ray集群的大规模生产运维经验仍在积累中
- 流处理能力欠缺:Spark有强大的流处理引擎,而这一组合目前主要针对离线批处理和近线推理,实时流处理并非强项
结论:如何选择?
选择哪套技术栈,取决于业务的核心场景:
-
如果您的场景是传统数仓、BI报表、大规模ETL,且数据主要以结构化行式为主,那么 Hadoop + Spark 依然是稳定且功能强大的首选。其完善的SQL支持和丰富的连接器生态无可替代
-
如果您的场景是AI/ML、大模型训练与推理,数据涉及大量图像、视频、Embedding向量,希望在一个Python环境中完成从数据预处理到模型服务的全流程,那么 Ray + Daft + Lance 的组合提供了更现代、更高效的路径。它能显著减少因数据格式转换和跨语言通信带来的开销,并原生支持GPU等异构资源
正如Azure Databricks文档所建议的,未来的趋势可能是混合使用——用Spark做大规模数据清洗和ETL,然后用Ray做计算密集型的模型训练和推理,两者在同一个平台(如Databricks)上共享数据和资源
Python全栈的分布式计算并非要完全取代JVM生态,而是为数据密集型和计算密集型的AI时代,提供了一把更趁手、更贴合开发者心智的瑞士军刀
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在Python数据处理与分析中,大家在处理数据时,使用的基本都是 Pandas ,该库非常好用。随着 Rust 的出圈,基于其开发的 Polars 库,逐渐赢得大家的喜爱,在某些功能上更优于 Pandas。于是小编在自学的过程中,逐步整理一些资料供大家参考学习,这些资料会分享到github
仓库地址:https://github.com/DataShare-duo/polars_learn
PS:为了学习 Polars,小编先了解一遍 Rust,《Rust权威指南》
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.5
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 0.20.22
读取文件
polars读取文件数据的方式基本与pands一致,所以上手起来很方便,以下演示是在jupyter notebook中执行
- 读取csv文件
data_csv=pl.read_csv('./data/iris.csv')
data_csv.shape
#(150, 6)
- 读取 excel 文件
- 默认解析引擎
xlsx2csv,需要额外安装pip install xlsx2csv - 设置
engine='calamine'时,需要额外安装pip install fastexcel,建议用该解析引擎,速度更快
data_excel=pl.read_excel('./data/iris.xlsx',sheet_name='iris',engine='calamine')
data_excel.shape
#(150, 6)
%timeit pl.read_excel('./data/iris.xlsx',sheet_name='iris')
#13.9 ms ± 69.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit pl.read_excel('./data/iris.xlsx',sheet_name='iris',engine='calamine')
#2.9 ms ± 69.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
- 读取 txt 文件
data_txt=pl.read_csv('./data/iris.txt',separator='\t')
data_txt.shape
#(150, 6)
- 读取网络上的文件
url='https://raw.githubusercontent.com/DataShare-duo/Data_for_ML-Deeplearning/master/iris.csv'
data_url=pl.read_csv(url)
data_url.shape
#(150, 6)
写入文件
- 写入csv文件
data_csv.write_csv('./data/data_write.csv')
- 写入excel文件
默认的浮点数为3位,可以通过
float_precision参数进行设置
data_csv.write_excel('./data/data_write.xlsx',float_precision=1)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第2篇,上下文与表达式。
该系列文章会分享到github,大家可以去下载jupyter文件
仓库地址:https://github.com/DataShare-duo/polars_learn
上下文与表达式概述
官方文档表述:
Polars has developed its own Domain Specific Language (DSL) for transforming data. The language is very easy to use and allows for complex queries that remain human readable. The two core components of the language are Contexts and Expressions
机器翻译: Polars 开发了自己的特定领域语言 (DSL),用于转换数据。 该语言非常容易使用,允许进行复杂的查询,但仍保持人类可读性。 该语言的两个核心组成部分是上下文和表达式
小编加工后的翻译: Polars 自己设计了一套用于处理数据的功能。 该功能易于使用,而且能以易理解的方式进行复杂的数据处理。 上下文与表达式是该功能的两个核心组成部分。
1. Contexts 上下文 上下文是指需要计算表达式的上下文
- 选择:df.select(...),df.with_columns(...)
- 过滤:df.filter()
- 分组聚合:df.group_by(...).agg(...)
2. Expressions 表达式 表达式是许多数据科学运算的核心:
- 选取特定的列
- 从一列中抽取特定的行
- 将一列与值相乘
- 从一个日期列中,提取年份
- 将一列字符串转换为小写
- ......
综上所述,在Polars中,Contexts 上下文 与 Expressions 表达式,需要结合使用
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.5
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 0.20.22
演示数据
df=pl.read_csv('./data/iris.csv')
print(df.head(10))
#shape: (10, 6)
┌───────┬──────────────┬─────────────┬──────────────┬─────────────┬─────────┐
│ index ┆ Sepal.Length ┆ Sepal.Width ┆ Petal.Length ┆ Petal.Width ┆ Species │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ f64 ┆ f64 ┆ f64 ┆ f64 ┆ str │
╞═══════╪══════════════╪═════════════╪══════════════╪═════════════╪═════════╡
│ 1 ┆ 5.1 ┆ 3.5 ┆ 1.4 ┆ 0.2 ┆ setosa │
│ 2 ┆ 4.9 ┆ 3.0 ┆ 1.4 ┆ 0.2 ┆ setosa │
│ 3 ┆ 4.7 ┆ 3.2 ┆ 1.3 ┆ 0.2 ┆ setosa │
│ 4 ┆ 4.6 ┆ 3.1 ┆ 1.5 ┆ 0.2 ┆ setosa │
│ 5 ┆ 5.0 ┆ 3.6 ┆ 1.4 ┆ 0.2 ┆ setosa │
│ 6 ┆ 5.4 ┆ 3.9 ┆ 1.7 ┆ 0.4 ┆ setosa │
│ 7 ┆ 4.6 ┆ 3.4 ┆ 1.4 ┆ 0.3 ┆ setosa │
│ 8 ┆ 5.0 ┆ 3.4 ┆ 1.5 ┆ 0.2 ┆ setosa │
│ 9 ┆ 4.4 ┆ 2.9 ┆ 1.4 ┆ 0.2 ┆ setosa │
│ 10 ┆ 4.9 ┆ 3.1 ┆ 1.5 ┆ 0.1 ┆ setosa │
└───────┴──────────────┴─────────────┴──────────────┴─────────────┴─────────┘
df.shape
#(150, 6)
选取需要的列
df.select(pl.col("Sepal.Length")) #选取特定的列
df.select(pl.col("Sepal.Length","Petal.Length"))
df.select(pl.col("*")) #选取所有列
df.select(pl.all()) #选取所有列
df.select(pl.col("*").exclude("index", "Species")) #选取列时,排除特定列
df.select(pl.col("^.*Length$")) #支持正则表达式,需要以 ^ 开始 $ 结尾
df.select(pl.col(pl.Float64)) #根据列的类型,进行选取
筛选出需要的行
df.filter(pl.col("Sepal.Length")>5)
df.filter((pl.col("Sepal.Length")>5) & (pl.col("Petal.Length")>5))
#需要把2个条件分别括起来!!!
df.filter((pl.col("Sepal.Length")>5) | (pl.col("Petal.Length")>5))
df.select(pl.col("Sepal.Width","Petal.Width").filter(pl.col("Sepal.Length")>5))
#根据过滤条件,选取特定列
增加新列
df.with_columns(pl.lit(10),pl.lit(2).alias("lit_5")) #增加常数列,并设置别名
df.with_columns(pl.max("Sepal.Length").alias("max_Sepal.Length"),
pl.min("Sepal.Length").alias("min_Sepal.Length"),
pl.mean("Sepal.Length").alias("avg_Sepal.Length"),
pl.std("Sepal.Length").alias("std_Sepal.Length")
) #有点类似窗口函数
数值列运算
df.select(pl.col("Sepal.Length"),
(pl.col("Sepal.Length")*100).alias("Sepal.Length * 100"),
(pl.col("Sepal.Length")/100).alias("Sepal.Length / 100"),
(pl.col("Sepal.Length")/pl.max("Sepal.Length")).alias("Sepal.Length /max_Sepal.Length")
)
字段串列运算
df.select(pl.col("Species"),
pl.col("Species").str.len_bytes().alias("byte_count"),
pl.col("Species").str.len_chars().alias("chars_count")
)
df.select(pl.col("Species"),
pl.col("Species").str.contains("set|vir").alias("regex"),
pl.col("Species").str.starts_with("set").alias("starts_with"),
pl.col("Species").str.ends_with("ca").alias("ends_with"),
)
去重统计
df.select(pl.col("Species").n_unique())
分组聚合运算
df.group_by("Species").agg(
pl.len(),
pl.col("index"),
pl.count("Sepal.Length").name.suffix("_count_1"), #别名,另一种方式
pl.col("Sepal.Length").count().name.suffix("_count_2"),
pl.mean("Sepal.Length").name.suffix("_mean"),
pl.std("Sepal.Length").name.suffix("_std"),
)
df.group_by("Species").agg(
(pl.col("Sepal.Length")>5).sum().alias("Sepal.Length>5"),
(pl.col("Petal.Length")>5).sum().alias("Petal.Length>5"),
)
排序
df.sort("Sepal.Length",descending=True)
df.sort(["Sepal.Length","Petal.Length"],descending=[True,False])
历史相关文章
- Python polars学习-01 读取与写入文件
- Python pandas遍历行数据的2种方法
- Python 利用pandas对数据进行特定排序
- Python pandas.str.replace 不起作用
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第3篇 数据类型转换。
该系列文章会分享到github,大家可以去下载jupyter文件
仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.5
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 0.20.22
数据类型转换
数据类型转换,主要是通过 cast 方法来进行操作,该方法中有个参数 strict ,该参数决定当原数据类型不能转换为目标数据类型时,应该如何处理
- 严格模式,
strict=True(该参数默认是True),就会进行报错,打印出详细的错误信息 - 非严格模式,
strict=False,不会报错,无法转换为目标数据类型的值都会被置为null
pandas 中数据类型转换使用的是 astype 方法
示例
数值类型 Numerics
浮点型数值转换为整型时,会向下取整;大范围的数据类型转换为小范围数据类型时,如果数值溢出时,默认会报错,如果设置了 strict=False,则会被置为 null
df = pl.DataFrame(
{
"integers": [1, 2, 3, 4, 5],
"big_integers": [1, 10000002, 3, 10000004, 10000005],
"floats": [4.0, 5.0, 6.0, 7.0, 8.0],
"floats_with_decimal": [4.532, 5.5, 6.5, 7.5, 8.5],
}
)
print(df)
shape: (5, 4)
┌──────────┬──────────────┬────────┬─────────────────────┐
│ integers ┆ big_integers ┆ floats ┆ floats_with_decimal │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ f64 ┆ f64 │
╞══════════╪══════════════╪════════╪═════════════════════╡
│ 1 ┆ 1 ┆ 4.0 ┆ 4.532 │
│ 2 ┆ 10000002 ┆ 5.0 ┆ 5.5 │
│ 3 ┆ 3 ┆ 6.0 ┆ 6.5 │
│ 4 ┆ 10000004 ┆ 7.0 ┆ 7.5 │
│ 5 ┆ 10000005 ┆ 8.0 ┆ 8.5 │
└──────────┴──────────────┴────────┴─────────────────────┘
out=df.select(
pl.col("integers").cast(pl.Float32).alias("integers_as_floats"),
pl.col("floats").cast(pl.Int32).alias("floats_as_integers"),
pl.col("floats_with_decimal").cast(pl.Int32).alias("floats_with_decimal_as_integers")
)
print(out)
shape: (5, 3)
┌────────────────────┬────────────────────┬─────────────────────────────────┐
│ integers_as_floats ┆ floats_as_integers ┆ floats_with_decimal_as_integers │
│ --- ┆ --- ┆ --- │
│ f32 ┆ i32 ┆ i32 │
╞════════════════════╪════════════════════╪═════════════════════════════════╡
│ 1.0 ┆ 4 ┆ 4 │
│ 2.0 ┆ 5 ┆ 5 │
│ 3.0 ┆ 6 ┆ 6 │
│ 4.0 ┆ 7 ┆ 7 │
│ 5.0 ┆ 8 ┆ 8 │
└────────────────────┴────────────────────┴─────────────────────────────────┘
#如果不溢出的类型转换,可以节省内存
out=df.select(
pl.col("integers").cast(pl.Int16).alias("integers_smallfootprint"),
pl.col("floats").cast(pl.Float32).alias("floats_smallfootprint"),
)
print(out)
shape: (5, 2)
┌─────────────────────────┬───────────────────────┐
│ integers_smallfootprint ┆ floats_smallfootprint │
│ --- ┆ --- │
│ i16 ┆ f32 │
╞═════════════════════════╪═══════════════════════╡
│ 1 ┆ 4.0 │
│ 2 ┆ 5.0 │
│ 3 ┆ 6.0 │
│ 4 ┆ 7.0 │
│ 5 ┆ 8.0 │
└─────────────────────────┴───────────────────────┘
try:
out = df.select(pl.col("big_integers").cast(pl.Int8))
print(out)
except Exception as e:
print(e)
#conversion from `i64` to `i8` failed in column 'big_integers' for 3 out of 5 values: [10000002, 10000004, 10000005]
out=df.select(pl.col("big_integers").cast(pl.Int8, strict=False))
print(out)
shape: (5, 1)
┌──────────────┐
│ big_integers │
│ --- │
│ i8 │
╞══════════════╡
│ 1 │
│ null │
│ 3 │
│ null │
│ null │
└──────────────┘
字符串类型 Strings
df = pl.DataFrame(
{
"integers": [1, 2, 3, 4, 5],
"float": [4.0, 5.03, 6.0, 7.0, 8.0],
"floats_as_string": ["4.0", "5.0", "6.0", "7.0", "8.0"],
}
)
print(df)
shape: (5, 3)
┌──────────┬───────┬──────────────────┐
│ integers ┆ float ┆ floats_as_string │
│ --- ┆ --- ┆ --- │
│ i64 ┆ f64 ┆ str │
╞══════════╪═══════╪══════════════════╡
│ 1 ┆ 4.0 ┆ 4.0 │
│ 2 ┆ 5.03 ┆ 5.0 │
│ 3 ┆ 6.0 ┆ 6.0 │
│ 4 ┆ 7.0 ┆ 7.0 │
│ 5 ┆ 8.0 ┆ 8.0 │
└──────────┴───────┴──────────────────┘
out=df.select(
pl.col("integers").cast(pl.String),
pl.col("float").cast(pl.String),
pl.col("floats_as_string").cast(pl.Float64),
)
print(out)
shape: (5, 3)
┌──────────┬───────┬──────────────────┐
│ integers ┆ float ┆ floats_as_string │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ f64 │
╞══════════╪═══════╪══════════════════╡
│ 1 ┆ 4.0 ┆ 4.0 │
│ 2 ┆ 5.03 ┆ 5.0 │
│ 3 ┆ 6.0 ┆ 6.0 │
│ 4 ┆ 7.0 ┆ 7.0 │
│ 5 ┆ 8.0 ┆ 8.0 │
└──────────┴───────┴──────────────────┘
df = pl.DataFrame({"strings_not_float": ["4.0", "not_a_number", "6.0", "7.0", "8.0"]})
print(df)
shape: (5, 1)
┌───────────────────┐
│ strings_not_float │
│ --- │
│ str │
╞═══════════════════╡
│ 4.0 │
│ not_a_number │
│ 6.0 │
│ 7.0 │
│ 8.0 │
└───────────────────┘
#运行会报错
out=df.select(pl.col("strings_not_float").cast(pl.Float64))
#设置非严格模式,忽略错误,置为null
out=df.select(pl.col("strings_not_float").cast(pl.Float64,strict=False))
print(out)
shape: (5, 1)
┌───────────────────┐
│ strings_not_float │
│ --- │
│ f64 │
╞═══════════════════╡
│ 4.0 │
│ null │
│ 6.0 │
│ 7.0 │
│ 8.0 │
└───────────────────┘
布尔类型 Booleans
数值型与布尔型可以相互转换,但是不允许字符型转换为布尔型
df = pl.DataFrame(
{
"integers": [-1, 0, 2, 3, 4],
"floats": [0.0, 1.0, 2.0, 3.0, 4.0],
"bools": [True, False, True, False, True],
}
)
print(df)
shape: (5, 3)
┌──────────┬────────┬───────┐
│ integers ┆ floats ┆ bools │
│ --- ┆ --- ┆ --- │
│ i64 ┆ f64 ┆ bool │
╞══════════╪════════╪═══════╡
│ -1 ┆ 0.0 ┆ true │
│ 0 ┆ 1.0 ┆ false │
│ 2 ┆ 2.0 ┆ true │
│ 3 ┆ 3.0 ┆ false │
│ 4 ┆ 4.0 ┆ true │
└──────────┴────────┴───────┘
out=df.select(pl.col("integers").cast(pl.Boolean),
pl.col("floats").cast(pl.Boolean)
)
print(out)
shape: (5, 2)
┌──────────┬────────┐
│ integers ┆ floats │
│ --- ┆ --- │
│ bool ┆ bool │
╞══════════╪════════╡
│ true ┆ false │
│ false ┆ true │
│ true ┆ true │
│ true ┆ true │
│ true ┆ true │
└──────────┴────────┘
时间类型 Dates
Date 或 Datetime 等时间数据类型表示为自纪元(1970年1月1日)以来的天数(Date)和微秒数(Datetime),因此数值类型与时间数据类型能直接相互转换
字符串类型与时间类型,可以通过 dt.to_string、str.to_datetime进行相互转换
from datetime import date, datetime
df = pl.DataFrame(
{
"date": pl.date_range(date(2022, 1, 1), date(2022, 1, 5), eager=True),
"datetime": pl.datetime_range(
datetime(2022, 1, 1), datetime(2022, 1, 5), eager=True
),
}
)
print(df)
shape: (5, 2)
┌────────────┬─────────────────────┐
│ date ┆ datetime │
│ --- ┆ --- │
│ date ┆ datetime[μs] │
╞════════════╪═════════════════════╡
│ 2022-01-01 ┆ 2022-01-01 00:00:00 │
│ 2022-01-02 ┆ 2022-01-02 00:00:00 │
│ 2022-01-03 ┆ 2022-01-03 00:00:00 │
│ 2022-01-04 ┆ 2022-01-04 00:00:00 │
│ 2022-01-05 ┆ 2022-01-05 00:00:00 │
└────────────┴─────────────────────┘
out=df.select(pl.col("date").cast(pl.Int64),
pl.col("datetime").cast(pl.Int64)
)
print(out)
shape: (5, 2)
┌───────┬──────────────────┐
│ date ┆ datetime │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞═══════╪══════════════════╡
│ 18993 ┆ 1640995200000000 │
│ 18994 ┆ 1641081600000000 │
│ 18995 ┆ 1641168000000000 │
│ 18996 ┆ 1641254400000000 │
│ 18997 ┆ 1641340800000000 │
└───────┴──────────────────┘
df = pl.DataFrame(
{
"date": pl.date_range(date(2022, 1, 1), date(2022, 1, 5), eager=True),
"string": [
"2022-01-01",
"2022-01-02",
"2022-01-03",
"2022-01-04",
"2022-01-05",
],
}
)
print(df)
shape: (5, 2)
┌────────────┬────────────┐
│ date ┆ string │
│ --- ┆ --- │
│ date ┆ str │
╞════════════╪════════════╡
│ 2022-01-01 ┆ 2022-01-01 │
│ 2022-01-02 ┆ 2022-01-02 │
│ 2022-01-03 ┆ 2022-01-03 │
│ 2022-01-04 ┆ 2022-01-04 │
│ 2022-01-05 ┆ 2022-01-05 │
└────────────┴────────────┘
out=df.select(
pl.col("date").dt.to_string("%Y-%m-%d"),
pl.col("string").str.to_datetime("%Y-%m-%d"),
pl.col("string").str.to_date("%Y-%m-%d").alias("string_to_data")
)
print(out)
shape: (5, 3)
┌────────────┬─────────────────────┬────────────────┐
│ date ┆ string ┆ string_to_data │
│ --- ┆ --- ┆ --- │
│ str ┆ datetime[μs] ┆ date │
╞════════════╪═════════════════════╪════════════════╡
│ 2022-01-01 ┆ 2022-01-01 00:00:00 ┆ 2022-01-01 │
│ 2022-01-02 ┆ 2022-01-02 00:00:00 ┆ 2022-01-02 │
│ 2022-01-03 ┆ 2022-01-03 00:00:00 ┆ 2022-01-03 │
│ 2022-01-04 ┆ 2022-01-04 00:00:00 ┆ 2022-01-04 │
│ 2022-01-05 ┆ 2022-01-05 00:00:00 ┆ 2022-01-05 │
└────────────┴─────────────────────┴────────────────┘
历史相关文章
- Python polars学习-01 读取与写入文件
- Python polars学习-02 上下文与表达式
- Python pandas 里面的数据类型坑,astype要慎用
- Python pandas.str.replace 不起作用
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第4篇 字符串数据处理
该系列文章会分享到github,大家可以去下载jupyter文件,进行参考学习
仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 0.20.22
字符串长度
可以获取字符串中的字符数或者字节数
df = pl.DataFrame({"animal": ["Crab", "cat and dog", "rab$bit", '张',None]})
out = df.select(
pl.col("animal").str.len_bytes().alias("byte_count"), #字节数
pl.col("animal").str.len_chars().alias("letter_count"), #字符串数
)
print(out)
shape: (5, 2)
┌────────────┬──────────────┐
│ byte_count ┆ letter_count │
│ --- ┆ --- │
│ u32 ┆ u32 │
╞════════════╪══════════════╡
│ 4 ┆ 4 │
│ 11 ┆ 11 │
│ 7 ┆ 7 │
│ 3 ┆ 1 │
│ null ┆ null │
└────────────┴──────────────┘
判断是否包含特定字符串或正则字符串
- contains:包含指定的字符串,或正则表达式字符串,返回ture/false
- starts_with:判断是否以指定的字符串开头,返回ture/false
- ends_with:判断是否以指定的字符串结尾,返回ture/false
如果包含了特殊的字符,但又不是正则表达式,需要设置参数literal=True,literal默认是 False,代表字符是正则表达式字符串
out = df.select(
pl.col("animal"),
pl.col("animal").str.contains("cat|bit").alias("regex"),
pl.col("animal").str.contains("rab$", literal=True).alias("literal"), #匹配$原始字符
pl.col("animal").str.contains("rab$").alias("regex_pattern"),
pl.col("animal").str.starts_with("rab").alias("starts_with"),
pl.col("animal").str.ends_with("dog").alias("ends_with"),
)
print(out)
shape: (5, 6)
┌─────────────┬───────┬─────────┬───────────────┬─────────────┬───────────┐
│ animal ┆ regex ┆ literal ┆ regex_pattern ┆ starts_with ┆ ends_with │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ bool ┆ bool ┆ bool ┆ bool ┆ bool │
╞═════════════╪═══════╪═════════╪═══════════════╪═════════════╪═══════════╡
│ Crab ┆ false ┆ false ┆ true ┆ false ┆ false │
│ cat and dog ┆ true ┆ false ┆ false ┆ false ┆ true │
│ rab$bit ┆ true ┆ true ┆ false ┆ true ┆ false │
│ 张 ┆ false ┆ false ┆ false ┆ false ┆ false │
│ null ┆ null ┆ null ┆ null ┆ null ┆ null │
└─────────────┴───────┴─────────┴───────────────┴─────────────┴───────────┘
正则表达式的各种标识,需要写到字符串开始,用括号括起来,(?iLmsuxU)
out=pl.DataFrame({"s": ["AAA", "aAa", "aaa"]}).with_columns(
default_match=pl.col("s").str.contains("AA"),
insensitive_match=pl.col("s").str.contains("(?i)AA") #忽略大小写
)
print(out)
shape: (3, 3)
┌─────┬───────────────┬───────────────────┐
│ s ┆ default_match ┆ insensitive_match │
│ --- ┆ --- ┆ --- │
│ str ┆ bool ┆ bool │
╞═════╪═══════════════╪═══════════════════╡
│ AAA ┆ true ┆ true │
│ aAa ┆ false ┆ true │
│ aaa ┆ false ┆ true │
└─────┴───────────────┴───────────────────┘
根据正则表达式提取特定字符
使用extract方法,根据提供的正则表达式模式,进行提取匹配到的字符串,需要提供想要获取的组索引 group_index,默认是第1个
df = pl.DataFrame(
{
"a": [
"http://vote.com/ballon_dor?candidate=messi&ref=polars",
"http://vote.com/ballon_dor?candidat=jorginho&ref=polars",
"http://vote.com/ballon_dor?candidate=ronaldo&ref=polars",
]
}
)
out = df.select(
a1=pl.col("a").str.extract(r"candidate=(\w+)", group_index=1),
a2=pl.col("a").str.extract(r"candidate=(\w+)", group_index=0),
a3=pl.col("a").str.extract(r"candidate=(\w+)") #默认获取第1个
)
print(out)
shape: (3, 3)
┌─────────┬───────────────────┬─────────┐
│ a1 ┆ a2 ┆ a3 │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str │
╞═════════╪═══════════════════╪═════════╡
│ messi ┆ candidate=messi ┆ messi │
│ null ┆ null ┆ null │
│ ronaldo ┆ candidate=ronaldo ┆ ronaldo │
└─────────┴───────────────────┴─────────┘
如果想获取所有正则表达式匹配到的字符串,需要使用 extract_all 方法,结果是一个列表
df = pl.DataFrame({"foo": ["123 bla 45 asd", "xyz 678 910t"]})
out = df.select(
pl.col("foo").str.extract_all(r"(\d+)").alias("extracted_nrs"),
)
print(out)
shape: (2, 1)
┌────────────────┐
│ extracted_nrs │
│ --- │
│ list[str] │
╞════════════════╡
│ ["123", "45"] │
│ ["678", "910"] │
└────────────────┘
字符串替换
- replace:替换第一次匹配到的字符串,为新的字符串
- replace_all:替换所有匹配到的字符串,为新的字符串
df = pl.DataFrame({"id": [1, 2], "text": ["abc123abc", "abc456"]})
out = df.with_columns(
s1=pl.col("text").str.replace(r"abc\b", "ABC"), #\b 字符串结束位置,以 abc 出现在字符串结尾处
s2=pl.col("text").str.replace("a", "-"), #只替换第一次出现的 a
s3=pl.col("text").str.replace_all("a", "-", literal=True) #替换所有的 a
)
print(out)
shape: (2, 5)
┌─────┬───────────┬───────────┬───────────┬───────────┐
│ id ┆ text ┆ s1 ┆ s2 ┆ s3 │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ str │
╞═════╪═══════════╪═══════════╪═══════════╪═══════════╡
│ 1 ┆ abc123abc ┆ abc123ABC ┆ -bc123abc ┆ -bc123-bc │
│ 2 ┆ abc456 ┆ abc456 ┆ -bc456 ┆ -bc456 │
└─────┴───────────┴───────────┴───────────┴───────────┘
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第5篇 包含的数据结构,与 pandas 一样,polars 包含的数据结构是:Series、DataFrame,大部分操作与pandas 保持一致,减少了大家的学习难度
该系列文章会分享到github,大家可以去下载jupyter文件,进行参考学习
仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 0.20.22
Series 数据列
Series 是一维的数据结构,其有相同的数据类型,可以理解为数据库中的一列
import polars as pl
s = pl.Series("a", [1, 2, 3, 4, 5])
print(s)
shape: (5,)
Series: 'a' [i64]
[
1
2
3
4
5
]
数据列的操作
print(s.min()) #1
print(s.max()) #5
print(s.mean()) #3.0
print(s.count()) #5
DataFrame 数据框
DataFrame 是一个二维的数据结构,其是由一系列的 Series 组成,可以理解为一张数据表,包含很多列
from datetime import datetime
df = pl.DataFrame(
{
"integer": [1, 2, 3, 4, 5],
"date": [
datetime(2022, 1, 1),
datetime(2022, 1, 2),
datetime(2022, 1, 3),
datetime(2022, 1, 4),
datetime(2022, 1, 5),
],
"float": [4.0, 5.0, 6.0, 7.0, 8.0],
}
)
print(df)
shape: (5, 3)
┌─────────┬─────────────────────┬───────┐
│ integer ┆ date ┆ float │
│ --- ┆ --- ┆ --- │
│ i64 ┆ datetime[μs] ┆ f64 │
╞═════════╪═════════════════════╪═══════╡
│ 1 ┆ 2022-01-01 00:00:00 ┆ 4.0 │
│ 2 ┆ 2022-01-02 00:00:00 ┆ 5.0 │
│ 3 ┆ 2022-01-03 00:00:00 ┆ 6.0 │
│ 4 ┆ 2022-01-04 00:00:00 ┆ 7.0 │
│ 5 ┆ 2022-01-05 00:00:00 ┆ 8.0 │
└─────────┴─────────────────────┴───────┘
Head
默认展示前5行数据,也可以传出要展示的行数
print(df.head())
#shape: (5, 3)
┌─────────┬─────────────────────┬───────┐
│ integer ┆ date ┆ float │
│ --- ┆ --- ┆ --- │
│ i64 ┆ datetime[μs] ┆ f64 │
╞═════════╪═════════════════════╪═══════╡
│ 1 ┆ 2022-01-01 00:00:00 ┆ 4.0 │
│ 2 ┆ 2022-01-02 00:00:00 ┆ 5.0 │
│ 3 ┆ 2022-01-03 00:00:00 ┆ 6.0 │
│ 4 ┆ 2022-01-04 00:00:00 ┆ 7.0 │
│ 5 ┆ 2022-01-05 00:00:00 ┆ 8.0 │
└─────────┴─────────────────────┴───────┘
print(df.head(3))
#shape: (3, 3)
┌─────────┬─────────────────────┬───────┐
│ integer ┆ date ┆ float │
│ --- ┆ --- ┆ --- │
│ i64 ┆ datetime[μs] ┆ f64 │
╞═════════╪═════════════════════╪═══════╡
│ 1 ┆ 2022-01-01 00:00:00 ┆ 4.0 │
│ 2 ┆ 2022-01-02 00:00:00 ┆ 5.0 │
│ 3 ┆ 2022-01-03 00:00:00 ┆ 6.0 │
└─────────┴─────────────────────┴───────┘
Tail
默认展示最后5行数据,也可以传出要展示的行数
print(df.tail())
#shape: (5, 3)
┌─────────┬─────────────────────┬───────┐
│ integer ┆ date ┆ float │
│ --- ┆ --- ┆ --- │
│ i64 ┆ datetime[μs] ┆ f64 │
╞═════════╪═════════════════════╪═══════╡
│ 1 ┆ 2022-01-01 00:00:00 ┆ 4.0 │
│ 2 ┆ 2022-01-02 00:00:00 ┆ 5.0 │
│ 3 ┆ 2022-01-03 00:00:00 ┆ 6.0 │
│ 4 ┆ 2022-01-04 00:00:00 ┆ 7.0 │
│ 5 ┆ 2022-01-05 00:00:00 ┆ 8.0 │
└─────────┴─────────────────────┴───────┘
print(df.tail(3))
#shape: (3, 3)
┌─────────┬─────────────────────┬───────┐
│ integer ┆ date ┆ float │
│ --- ┆ --- ┆ --- │
│ i64 ┆ datetime[μs] ┆ f64 │
╞═════════╪═════════════════════╪═══════╡
│ 3 ┆ 2022-01-03 00:00:00 ┆ 6.0 │
│ 4 ┆ 2022-01-04 00:00:00 ┆ 7.0 │
│ 5 ┆ 2022-01-05 00:00:00 ┆ 8.0 │
└─────────┴─────────────────────┴───────┘
Sample 随机抽样
print(df.sample(3))
#shape: (3, 3)
┌─────────┬─────────────────────┬───────┐
│ integer ┆ date ┆ float │
│ --- ┆ --- ┆ --- │
│ i64 ┆ datetime[μs] ┆ f64 │
╞═════════╪═════════════════════╪═══════╡
│ 5 ┆ 2022-01-05 00:00:00 ┆ 8.0 │
│ 3 ┆ 2022-01-03 00:00:00 ┆ 6.0 │
│ 1 ┆ 2022-01-01 00:00:00 ┆ 4.0 │
└─────────┴─────────────────────┴───────┘
Describe 数据概况
print(df.describe())
#shape: (9, 4)
┌────────────┬──────────┬─────────────────────┬──────────┐
│ statistic ┆ integer ┆ date ┆ float │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ str ┆ f64 │
╞════════════╪══════════╪═════════════════════╪══════════╡
│ count ┆ 5.0 ┆ 5 ┆ 5.0 │
│ null_count ┆ 0.0 ┆ 0 ┆ 0.0 │
│ mean ┆ 3.0 ┆ 2022-01-03 00:00:00 ┆ 6.0 │
│ std ┆ 1.581139 ┆ null ┆ 1.581139 │
│ min ┆ 1.0 ┆ 2022-01-01 00:00:00 ┆ 4.0 │
│ 25% ┆ 2.0 ┆ 2022-01-02 00:00:00 ┆ 5.0 │
│ 50% ┆ 3.0 ┆ 2022-01-03 00:00:00 ┆ 6.0 │
│ 75% ┆ 4.0 ┆ 2022-01-04 00:00:00 ┆ 7.0 │
│ max ┆ 5.0 ┆ 2022-01-05 00:00:00 ┆ 8.0 │
└────────────┴──────────┴─────────────────────┴──────────┘
历史相关文章
- Python polars学习-01 读取与写入文件
- Python polars学习-02 上下文与表达式
- Python polars学习-03 数据类型转换
- Python polars学习-04 字符串数据处理
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第6篇 Lazy / Eager API
Lazy: 延迟、惰性
Eager: 即时、实时
该系列文章会分享到github,大家可以去下载jupyter文件,进行参考学习
仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 0.20.22
Lazy / Eager API 区别
-
Eager API(即时、实时) 实时进行计算,每一步操作都会进行计算,类似pandas那样,每操作一步都会进行计算,得到这一步的结果,所见即所得,如果没有明确指定或者调用特定的方法之外,polars 基本都是使用该模式
-
Lazy API(延迟、惰性) 推迟进行计算,把所有的操作步骤先记下来,Query plan(查询计划),等到需要结果时,才统一进行计算,polars 会对这些计算步骤自动进行优化,提升性能
pl.scan_csv等pl.scan_函数- 调用DataFrame 的
.lazy方法,转换为 Lazy 模式
Eager API 数据处理案例
df = pl.read_csv("./data/iris.csv")
df_small = df.filter(pl.col("Sepal.Length") > 5)
df_agg = df_small.group_by("Species").agg(pl.col("Sepal.Width").mean())
print(df_agg)
#shape: (3, 2)
┌────────────┬─────────────┐
│ Species ┆ Sepal.Width │
│ --- ┆ --- │
│ str ┆ f64 │
╞════════════╪═════════════╡
│ versicolor ┆ 2.804255 │
│ virginica ┆ 2.983673 │
│ setosa ┆ 3.713636 │
└────────────┴─────────────┘
Lazy API 数据处理案例
q = (
pl.scan_csv("./data/iris.csv")
.filter(pl.col("Sepal.Length") > 5)
.group_by("Species")
.agg(pl.col("Sepal.Width").mean())
)
df = q.collect()
print(df)
#shape: (3, 2)
┌────────────┬─────────────┐
│ Species ┆ Sepal.Width │
│ --- ┆ --- │
│ str ┆ f64 │
╞════════════╪═════════════╡
│ virginica ┆ 2.983673 │
│ versicolor ┆ 2.804255 │
│ setosa ┆ 3.713636 │
└────────────┴─────────────┘
在数据处理中会对Sepal.Length进行过滤,polars 在把数据加载进内存时,只会加载符合条件的数据行,同时计算时只用到了 Species、Sepal.Width 2列,polars 只会加载这2 列到内存,进行计算
这样的话会显著降低内存和CPU的负载,从而能够在内存中容纳更大的数据集并加快处理速度
使用建议
- 如果你是在进行探索性分析,想知道中间的每个步骤数据情况,那么可以使用 Eager 模式
- 如果想得到最终的计算结果,那么可以使用 Lazy 模式,让polars对中间的计算进行优化,提升数据处理效率
注:在大部分情况下,Eager API 背后其实调用的是 Lazy API,Eager 模式其实也是有查询优化
历史相关文章
- Python polars学习-01 读取与写入文件
- Python polars学习-02 上下文与表达式
- Python polars学习-03 数据类型转换
- Python polars学习-04 字符串数据处理
- Python polars学习-05 包含的数据结构
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第7篇 缺失值
该系列文章会分享到github,大家可以去下载jupyter文件,进行参考学习
仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 0.20.22
polars 中缺失值的定义
在 polars 中缺失值用 null 来表示,只有这1种表示方式,这个与 pandas 不同,在 pandas 中 NaN(NotaNumber)也代表是缺失值,但在polars中把 NaN 归属为一种浮点数据
df = pl.DataFrame(
{
"value": [1,2,3, None,5,6,None,8,9],
},
)
print(df)
#shape: (9, 1)
┌───────┐
│ value │
│ --- │
│ i64 │
╞═══════╡
│ 1 │
│ 2 │
│ 3 │
│ null │
│ 5 │
│ 6 │
│ null │
│ 8 │
│ 9 │
└───────┘
polars中缺失值包括的2种元信息
- 缺失值数量,可以通过
null_count方法来快速获取,因为已经是计算好的,所以调用该方法会立即返回结果 - 有效位图(validity bitmap),代表是否是缺失值,在内存中用 0 或 1 进行编码来表示,所占的内存空间非常小,通常占用空间为(数据框长度 / 8) bytes,通过
is_null方法来查看数据是否是缺失值
null_count_df = df.null_count()
print(null_count_df)
#shape: (1, 1)
┌───────┐
│ value │
│ --- │
│ u32 │
╞═══════╡
│ 2 │
└───────┘
is_null_series = df.select(
pl.col("value").is_null(),
)
print(is_null_series)
#shape: (9, 1)
┌───────┐
│ value │
│ --- │
│ bool │
╞═══════╡
│ false │
│ false │
│ false │
│ true │
│ false │
│ false │
│ true │
│ false │
│ false │
└───────┘
缺失值填充
缺失值填充主要通过 fill_null方法来处理,但是需求指定填充缺失值的方法
- 常量,比如用 0 来填充
- 填充策略,例如:向前、向后 等
- 通过表达式,比如利用其他列来填充
- 插值法
df = pl.DataFrame(
{
"col1": [1, 2, 3],
"col2": [1, None, 3],
},
)
print(df)
#shape: (3, 2)
┌──────┬──────┐
│ col1 ┆ col2 │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞══════╪══════╡
│ 1 ┆ 1 │
│ 2 ┆ null │
│ 3 ┆ 3 │
└──────┴──────┘
常量填充
fill_literal_df = df.with_columns(
fill=pl.col("col2").fill_null(pl.lit(2)),
)
print(fill_literal_df)
#shape: (3, 3)
┌──────┬──────┬──────┐
│ col1 ┆ col2 ┆ fill │
│ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ i64 │
╞══════╪══════╪══════╡
│ 1 ┆ 1 ┆ 1 │
│ 2 ┆ null ┆ 2 │
│ 3 ┆ 3 ┆ 3 │
└──────┴──────┴──────┘
填充策略
填充策略:{'forward', 'backward', 'min', 'max', 'mean', 'zero', 'one'}
fill_df = df.with_columns(
forward=pl.col("col2").fill_null(strategy="forward"),
backward=pl.col("col2").fill_null(strategy="backward"),
)
print(fill_df)
#shape: (3, 4)
┌──────┬──────┬─────────┬──────────┐
│ col1 ┆ col2 ┆ forward ┆ backward │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ i64 ┆ i64 │
╞══════╪══════╪═════════╪══════════╡
│ 1 ┆ 1 ┆ 1 ┆ 1 │
│ 2 ┆ null ┆ 1 ┆ 3 │
│ 3 ┆ 3 ┆ 3 ┆ 3 │
└──────┴──────┴─────────┴──────────┘
通过表达式
fill_median_df = df.with_columns(
fill=pl.col("col2").fill_null(pl.median("col2")), #类型会转换为浮点型
)
print(fill_median_df)
#shape: (3, 3)
┌──────┬──────┬──────┐
│ col1 ┆ col2 ┆ fill │
│ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ f64 │
╞══════╪══════╪══════╡
│ 1 ┆ 1 ┆ 1.0 │
│ 2 ┆ null ┆ 2.0 │
│ 3 ┆ 3 ┆ 3.0 │
└──────┴──────┴──────┘
通过插值法
fill_interpolation_df = df.with_columns(
fill=pl.col("col2").interpolate(),
)
print(fill_interpolation_df)
#shape: (3, 3)
┌──────┬──────┬──────┐
│ col1 ┆ col2 ┆ fill │
│ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ f64 │
╞══════╪══════╪══════╡
│ 1 ┆ 1 ┆ 1.0 │
│ 2 ┆ null ┆ 2.0 │
│ 3 ┆ 3 ┆ 3.0 │
└──────┴──────┴──────┘
历史相关文章
- Python polars学习-01 读取与写入文件
- Python polars学习-02 上下文与表达式
- Python polars学习-03 数据类型转换
- Python polars学习-04 字符串数据处理
- Python polars学习-05 包含的数据结构
- Python polars学习-06 Lazy / Eager API
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第8篇 分类数据处理(Categorical data)
该系列文章会分享到github,大家可以去下载jupyter文件,进行参考学习
仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 0.20.22
分类数据 Categorical data
分类数据就是平时在数据库中能进行编码的数据,比如:性别、年龄、国家、城市、职业 等等,可以对这些数据进行编码,可以节省存储空间
Polars 支持两种不同的数据类型来处理分类数据:Enum 和 Categorical
- 当类别预先已知时使用
Enum,需要提前提供所有类别 - 当不知道类别或类别不固定时,可以使用
Categorical
enum_dtype = pl.Enum(["Polar", "Panda", "Brown"])
enum_series = pl.Series(
["Polar", "Panda", "Brown", "Brown", "Polar"],
dtype=enum_dtype)
cat_series = pl.Series(
["Polar", "Panda", "Brown", "Brown", "Polar"],
dtype=pl.Categorical
)
Categorical 类型
Categorical 相对比较灵活,不用提前获取所有的类别,当有新类别时,会自动进行编码
当对来自2个不同的 Categorical 类别列直接进行拼接时,以下这种方式会比较慢,polars 是根据字符串出现的先后顺序进行编码,不同的字符串在不同的序列里面编码可能不一样,直接合并的话全局会再进行一次编码,速度会比较慢:
cat_series = pl.Series(
["Polar", "Panda", "Brown", "Brown", "Polar"], dtype=pl.Categorical
)
cat2_series = pl.Series(
["Panda", "Brown", "Brown", "Polar", "Polar"], dtype=pl.Categorical
)
#CategoricalRemappingWarning: Local categoricals have different encodings,
#expensive re-encoding is done to perform this merge operation.
#Consider using a StringCache or an Enum type if the categories are known in advance
print(cat_series.append(cat2_series))
可以通过使用 polars 提供的全局字符缓存 StringCache,来提升数据处理效率
with pl.StringCache():
cat_series = pl.Series(
["Polar", "Panda", "Brown", "Brown", "Polar"], dtype=pl.Categorical
)
cat2_series = pl.Series(
["Panda", "Brown", "Brown", "Polar", "Polar"], dtype=pl.Categorical
)
print(cat_series.append(cat2_series))
Enum
上面来自2个不同类型列进行拼接的耗时的情况,在Enum中不会存在,因为已经提前获取到了全部的类别
dtype = pl.Enum(["Polar", "Panda", "Brown"])
cat_series = pl.Series(["Polar", "Panda", "Brown", "Brown", "Polar"], dtype=dtype)
cat2_series = pl.Series(["Panda", "Brown", "Brown", "Polar", "Polar"], dtype=dtype)
print(cat_series.append(cat2_series))
#shape: (10,)
#Series: '' [enum]
[
"Polar"
"Panda"
"Brown"
"Brown"
"Polar"
"Panda"
"Brown"
"Brown"
"Polar"
"Polar"
]
如果有编码的字符串类别,当不在提前获取的Enum中时,则会报错:OutOfBounds
dtype = pl.Enum(["Polar", "Panda", "Brown"])
try:
cat_series = pl.Series(["Polar", "Panda", "Brown", "Black"], dtype=dtype)
except Exception as e:
print(e)
#conversion from `str` to `enum` failed
#in column '' for 1 out of 4 values: ["Black"]
#Ensure that all values in the input column are present
#in the categories of the enum datatype.
比较
- Categorical vs Categorical
- Categorical vs String
- Enum vs Enum
- Enum vs String(该字符串必须要在提前获取的Enum中)
Categorical vs Categorical
with pl.StringCache():
cat_series = pl.Series(["Brown", "Panda", "Polar"], dtype=pl.Categorical)
cat_series2 = pl.Series(["Polar", "Panda", "Black"], dtype=pl.Categorical)
print(cat_series == cat_series2)
#shape: (3,)
#Series: '' [bool]
[
false
true
false
]
Categorical vs String
cat_series = pl.Series(["Brown", "Panda", "Polar"], dtype=pl.Categorical)
print(cat_series <= "Cat")
#shape: (3,)
#Series: '' [bool]
[
true
false
false
]
cat_series = pl.Series(["Brown", "Panda", "Polar"], dtype=pl.Categorical)
cat_series_utf = pl.Series(["Panda", "Panda", "A Polar"])
print(cat_series <= cat_series_utf)
#shape: (3,)
#Series: '' [bool]
[
true
true
false
]
Enum vs Enum
dtype = pl.Enum(["Polar", "Panda", "Brown"])
cat_series = pl.Series(["Brown", "Panda", "Polar"], dtype=dtype)
cat_series2 = pl.Series(["Polar", "Panda", "Brown"], dtype=dtype)
print(cat_series == cat_series2)
#shape: (3,)
#Series: '' [bool]
[
false
true
false
]
Enum vs String(该字符串必须要在提前获取的Enum中)
try:
cat_series = pl.Series(
["Low", "Medium", "High"], dtype=pl.Enum(["Low", "Medium", "High"])
)
cat_series <= "Excellent"
except Exception as e:
print(e)
#conversion from `str` to `enum` failed
#in column '' for 1 out of 1 values: ["Excellent"]
#Ensure that all values in the input column are present
#in the categories of the enum datatype.
dtype = pl.Enum(["Low", "Medium", "High"])
cat_series = pl.Series(["Low", "Medium", "High"], dtype=dtype)
print(cat_series <= "Medium")
#shape: (3,)
#Series: '' [bool]
[
true
true
false
]
dtype = pl.Enum(["Low", "Medium", "High"])
cat_series = pl.Series(["Low", "Medium", "High"], dtype=dtype)
cat_series2 = pl.Series(["High", "High", "Low"])
print(cat_series <= cat_series2)
#shape: (3,)
#Series: '' [bool]
[
true
true
false
]
历史相关文章
- Python polars学习-01 读取与写入文件
- Python polars学习-02 上下文与表达式
- Python polars学习-03 数据类型转换
- Python polars学习-04 字符串数据处理
- Python polars学习-05 包含的数据结构
- Python polars学习-06 Lazy / Eager API
- Python polars学习-07 缺失值
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第9篇 数据框关联与拼接(Join 、Concat)
该系列文章会分享到github,大家可以去下载jupyter文件,进行参考学习
仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 1.2.1
数据框关联 Join
polars 通过指定参数 how,支持以下方式的关联:
- inner:类似sql中的 inner join,取2个数据框共同的部分
- left:类似sql中的 left join,取左边数据框所有数据,匹配右边数据框数据,能匹配到的进行匹配,匹配不到的用
null填充 - full:类似sql中的 full outer join,返回2个数据框的全量数据,匹配不到的用
null填充 - cross:2个数据框的笛卡尔积,数据行数为,
len(A) × len(B) - semi:用的相对比较少,左边数据框中关联字段同时存在右边数据框中,只返回左边数据框的行,有点类似
inner join,但是不全完一样,即使右边数据框有多行的,左边返回的还是单行,也就是遇到关联字段存在于右边数据框,就返回 - anti:用的相对比较少,返回左边数据框中关联字段不存在右边数据框中的行,与
semi相反
数据准备
df_customers = pl.DataFrame(
{
"customer_id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
}
)
print(df_customers)
#shape: (3, 2)
┌─────────────┬─────────┐
│ customer_id ┆ name │
│ --- ┆ --- │
│ i64 ┆ str │
╞═════════════╪═════════╡
│ 1 ┆ Alice │
│ 2 ┆ Bob │
│ 3 ┆ Charlie │
└─────────────┴─────────┘
df_orders = pl.DataFrame(
{
"order_id": ["a", "b", "c"],
"customer_id": [1, 2, 2],
"amount": [100, 200, 300],
}
)
print(df_orders)
#shape: (3, 3)
┌──────────┬─────────────┬────────┐
│ order_id ┆ customer_id ┆ amount │
│ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ i64 │
╞══════════╪═════════════╪════════╡
│ a ┆ 1 ┆ 100 │
│ b ┆ 2 ┆ 200 │
│ c ┆ 2 ┆ 300 │
└──────────┴─────────────┴────────┘
Inner join
df_inner_customer_join = df_customers.join(df_orders,
on="customer_id",
how="inner")
print(df_inner_customer_join)
#shape: (3, 4)
┌─────────────┬───────┬──────────┬────────┐
│ customer_id ┆ name ┆ order_id ┆ amount │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ i64 │
╞═════════════╪═══════╪══════════╪════════╡
│ 1 ┆ Alice ┆ a ┆ 100 │
│ 2 ┆ Bob ┆ b ┆ 200 │
│ 2 ┆ Bob ┆ c ┆ 300 │
└─────────────┴───────┴──────────┴────────┘
Left join
df_left_join = df_customers.join(df_orders,
on="customer_id",
how="left")
print(df_left_join)
#shape: (4, 4)
┌─────────────┬─────────┬──────────┬────────┐
│ customer_id ┆ name ┆ order_id ┆ amount │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ i64 │
╞═════════════╪═════════╪══════════╪════════╡
│ 1 ┆ Alice ┆ a ┆ 100 │
│ 2 ┆ Bob ┆ b ┆ 200 │
│ 2 ┆ Bob ┆ c ┆ 300 │
│ 3 ┆ Charlie ┆ null ┆ null │
└─────────────┴─────────┴──────────┴────────┘
Outer join
df_outer_join = df_customers.join(df_orders,
on="customer_id",
how="full")
print(df_outer_join)
#shape: (4, 5)
┌─────────────┬─────────┬──────────┬───────────────────┬────────┐
│ customer_id ┆ name ┆ order_id ┆ customer_id_right ┆ amount │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ i64 ┆ i64 │
╞═════════════╪═════════╪══════════╪═══════════════════╪════════╡
│ 1 ┆ Alice ┆ a ┆ 1 ┆ 100 │
│ 2 ┆ Bob ┆ b ┆ 2 ┆ 200 │
│ 2 ┆ Bob ┆ c ┆ 2 ┆ 300 │
│ 3 ┆ Charlie ┆ null ┆ null ┆ null │
└─────────────┴─────────┴──────────┴───────────────────┴────────┘
Cross join
df_colors = pl.DataFrame(
{
"color": ["red", "blue", "green"],
}
)
print(df_colors)
#shape: (3, 1)
┌───────┐
│ color │
│ --- │
│ str │
╞═══════╡
│ red │
│ blue │
│ green │
└───────┘
df_sizes = pl.DataFrame(
{
"size": ["S", "M", "L"],
}
)
#print(df_sizes)
df_cross_join = df_colors.join(df_sizes,
how="cross")
print(df_cross_join)
#shape: (9, 2)
┌───────┬──────┐
│ color ┆ size │
│ --- ┆ --- │
│ str ┆ str │
╞═══════╪══════╡
│ red ┆ S │
│ red ┆ M │
│ red ┆ L │
│ blue ┆ S │
│ blue ┆ M │
│ blue ┆ L │
│ green ┆ S │
│ green ┆ M │
│ green ┆ L │
└───────┴──────┘
Semi join
df_cars = pl.DataFrame(
{
"id": ["a", "b", "c"],
"make": ["ford", "toyota", "bmw"],
}
)
print(df_cars)
shape: (3, 2)
┌─────┬────────┐
│ id ┆ make │
│ --- ┆ --- │
│ str ┆ str │
╞═════╪════════╡
│ a ┆ ford │
│ b ┆ toyota │
│ c ┆ bmw │
└─────┴────────┘
df_repairs = pl.DataFrame(
{
"id": ["c", "c"],
"cost": [100, 200],
}
)
print(df_repairs)
#shape: (2, 2)
┌─────┬──────┐
│ id ┆ cost │
│ --- ┆ --- │
│ str ┆ i64 │
╞═════╪══════╡
│ c ┆ 100 │
│ c ┆ 200 │
└─────┴──────┘
df_semi_join = df_cars.join(df_repairs,
on="id",
how="semi")
print(df_semi_join)
#shape: (1, 2)
┌─────┬──────┐
│ id ┆ make │
│ --- ┆ --- │
│ str ┆ str │
╞═════╪══════╡
│ c ┆ bmw │
└─────┴──────┘
Anti join
df_anti_join = df_cars.join(df_repairs,
on="id",
how="anti")
print(df_anti_join)
#shape: (2, 2)
┌─────┬────────┐
│ id ┆ make │
│ --- ┆ --- │
│ str ┆ str │
╞═════╪════════╡
│ a ┆ ford │
│ b ┆ toyota │
└─────┴────────┘
数据框拼接 Concat
有以下3种方式的数据框拼接:
- 纵向拼接/垂直拼接:2个数据框有相同的字段,拼接后产生更长的数据框
- 横向拼接/水平拼接:2个数据框没有重叠的字段,拼接后产生更宽的数据框
- 对角拼接:2个数据框有不同的行与列,既有重叠的字段,也有非重叠的字段,拼接后产生即长又宽的数据框
纵向拼接/垂直拼接 Vertical concatenation
当没有相同的列字段时,纵向拼接会失败
df_v1 = pl.DataFrame(
{
"a": [1],
"b": [3],
}
)
df_v2 = pl.DataFrame(
{
"a": [2],
"b": [4],
}
)
df_vertical_concat = pl.concat(
[
df_v1,
df_v2,
],
how="vertical",
)
print(df_vertical_concat)
#shape: (2, 2)
┌─────┬─────┐
│ a ┆ b │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞═════╪═════╡
│ 1 ┆ 3 │
│ 2 ┆ 4 │
└─────┴─────┘
横向拼接/水平拼接 Horizontal concatenation
当2个数据框有不同的行数时,拼接后短的行会用 null 进行填充
df_h1 = pl.DataFrame(
{
"l1": [1, 2],
"l2": [3, 4],
}
)
df_h2 = pl.DataFrame(
{
"r1": [5, 6],
"r2": [7, 8],
"r3": [9, 10],
}
)
df_horizontal_concat = pl.concat(
[
df_h1,
df_h2,
],
how="horizontal",
)
print(df_horizontal_concat)
#shape: (2, 5)
┌─────┬─────┬─────┬─────┬─────┐
│ l1 ┆ l2 ┆ r1 ┆ r2 ┆ r3 │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞═════╪═════╪═════╪═════╪═════╡
│ 1 ┆ 3 ┆ 5 ┆ 7 ┆ 9 │
│ 2 ┆ 4 ┆ 6 ┆ 8 ┆ 10 │
└─────┴─────┴─────┴─────┴─────┘
对角拼接 Diagonal concatenation
df_d1 = pl.DataFrame(
{
"a": [1],
"b": [3],
}
)
df_d2 = pl.DataFrame(
{
"a": [2],
"d": [4],
}
)
df_diagonal_concat = pl.concat(
[
df_d1,
df_d2,
],
how="diagonal",
)
print(df_diagonal_concat)
#shape: (2, 3)
┌─────┬──────┬──────┐
│ a ┆ b ┆ d │
│ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ i64 │
╞═════╪══════╪══════╡
│ 1 ┆ 3 ┆ null │
│ 2 ┆ null ┆ 4 │
└─────┴──────┴──────┘
历史相关文章
- Python polars学习-01 读取与写入文件
- Python polars学习-02 上下文与表达式
- Python polars学习-03 数据类型转换
- Python polars学习-04 字符串数据处理
- Python polars学习-05 包含的数据结构
- Python polars学习-06 Lazy / Eager API
- Python polars学习-07 缺失值
- Python polars学习-08 分类数据处理
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第10篇 时间序列类型(Time series)
该系列文章会分享到github,大家可以去下载jupyter文件,进行参考学习 仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import polars as pl
print("polars 版本:",pl.__version__)
#polars 版本: 1.2.1
日期时间类型
Polars 原生支持解析时间序列数据,而且能执行一些复杂的操作
包含的日期时间类型:
- Date:日期类型,例如:2014-07-08,内部表示为自1970-01-01的天数,用32位有符号整数表示
- Datetime:日期时间类型,例如:2014-07-08 07:00:00
- Duration:时间间隔类型
- Time:时间类型
从文件加载数据时,解析时间
从csv文件加载数据时,可以指定 try_parse_dates=True,让polars去尝试解析日期时间
df = pl.read_csv("./data/apple_stock.csv", try_parse_dates=True)
print(df)
#shape: (100, 2)
┌────────────┬────────┐
│ Date ┆ Close │
│ --- ┆ --- │
│ date ┆ f64 │
╞════════════╪════════╡
│ 1981-02-23 ┆ 24.62 │
│ 1981-05-06 ┆ 27.38 │
│ 1981-05-18 ┆ 28.0 │
│ 1981-09-25 ┆ 14.25 │
│ 1982-07-08 ┆ 11.0 │
│ … ┆ … │
│ 2012-05-16 ┆ 546.08 │
│ 2012-12-04 ┆ 575.85 │
│ 2013-07-05 ┆ 417.42 │
│ 2013-11-07 ┆ 512.49 │
│ 2014-02-25 ┆ 522.06 │
└────────────┴────────┘
字符串转换为日期时间类型
通过调用字符串的 str.to_date 方法,需要指定日期时间解析时的格式
日期时间解析格式,可参考该文档:
https://docs.rs/chrono/latest/chrono/format/strftime/index.html
df = pl.read_csv("./data/apple_stock.csv", try_parse_dates=False)
df = df.with_columns(pl.col("Date").str.to_date("%Y-%m-%d"))
print(df)
shape: (100, 2)
┌────────────┬────────┐
│ Date ┆ Close │
│ --- ┆ --- │
│ date ┆ f64 │
╞════════════╪════════╡
│ 1981-02-23 ┆ 24.62 │
│ 1981-05-06 ┆ 27.38 │
│ 1981-05-18 ┆ 28.0 │
│ 1981-09-25 ┆ 14.25 │
│ 1982-07-08 ┆ 11.0 │
│ … ┆ … │
│ 2012-05-16 ┆ 546.08 │
│ 2012-12-04 ┆ 575.85 │
│ 2013-07-05 ┆ 417.42 │
│ 2013-11-07 ┆ 512.49 │
│ 2014-02-25 ┆ 522.06 │
└────────────┴────────┘
从日期时间类型中提取特定的日期类型
比如从日期时间类型列中提取年份、日期等,通过 .dt 来提取
df_with_year = df.with_columns(pl.col("Date").dt.year().alias("year"))
print(df_with_year)
#shape: (100, 3)
┌────────────┬────────┬──────┐
│ Date ┆ Close ┆ year │
│ --- ┆ --- ┆ --- │
│ date ┆ f64 ┆ i32 │
╞════════════╪════════╪══════╡
│ 1981-02-23 ┆ 24.62 ┆ 1981 │
│ 1981-05-06 ┆ 27.38 ┆ 1981 │
│ 1981-05-18 ┆ 28.0 ┆ 1981 │
│ 1981-09-25 ┆ 14.25 ┆ 1981 │
│ 1982-07-08 ┆ 11.0 ┆ 1982 │
│ … ┆ … ┆ … │
│ 2012-05-16 ┆ 546.08 ┆ 2012 │
│ 2012-12-04 ┆ 575.85 ┆ 2012 │
│ 2013-07-05 ┆ 417.42 ┆ 2013 │
│ 2013-11-07 ┆ 512.49 ┆ 2013 │
│ 2014-02-25 ┆ 522.06 ┆ 2014 │
└────────────┴────────┴──────┘
混合时差
当有混合时差(例如,由于跨越夏令时),可以使用 dt.convert_time_zone 来进行转换
data = [
"2021-03-27T00:00:00+0100",
"2021-03-28T00:00:00+0100",
"2021-03-29T00:00:00+0200",
"2021-03-30T00:00:00+0200",
]
mixed_parsed = (
pl.Series(data)
.str.to_datetime("%Y-%m-%dT%H:%M:%S%z")
.dt.convert_time_zone("Europe/Brussels")
)
print(mixed_parsed)
#shape: (4,)
Series: '' [datetime[μs, Europe/Brussels]]
[
2021-03-27 00:00:00 CET
2021-03-28 00:00:00 CET
2021-03-29 00:00:00 CEST
2021-03-30 00:00:00 CEST
]
日期时间数据筛选
from datetime import datetime
df = pl.read_csv("./data/apple_stock.csv", try_parse_dates=True)
print(df)
#shape: (100, 2)
┌────────────┬────────┐
│ Date ┆ Close │
│ --- ┆ --- │
│ date ┆ f64 │
╞════════════╪════════╡
│ 1981-02-23 ┆ 24.62 │
│ 1981-05-06 ┆ 27.38 │
│ 1981-05-18 ┆ 28.0 │
│ 1981-09-25 ┆ 14.25 │
│ 1982-07-08 ┆ 11.0 │
│ … ┆ … │
│ 2012-05-16 ┆ 546.08 │
│ 2012-12-04 ┆ 575.85 │
│ 2013-07-05 ┆ 417.42 │
│ 2013-11-07 ┆ 512.49 │
│ 2014-02-25 ┆ 522.06 │
└────────────┴────────┘
筛选单个日期时间对象
filtered_df = df.filter(
pl.col("Date") == datetime(1995, 10, 16),
)
print(filtered_df)
#shape: (1, 2)
┌────────────┬───────┐
│ Date ┆ Close │
│ --- ┆ --- │
│ date ┆ f64 │
╞════════════╪═══════╡
│ 1995-10-16 ┆ 36.13 │
└────────────┴───────┘
筛选一个日期范围
通过 is_between 方法,指定一个范围
filtered_range_df = df.filter(
pl.col("Date").is_between(datetime(1995, 7, 1), datetime(1995, 11, 1)),
)
print(filtered_range_df)
#shape: (2, 2)
┌────────────┬───────┐
│ Date ┆ Close │
│ --- ┆ --- │
│ date ┆ f64 │
╞════════════╪═══════╡
│ 1995-07-06 ┆ 47.0 │
│ 1995-10-16 ┆ 36.13 │
└────────────┴───────┘
筛选 负数日期
考古领域数据可能会涉及这类日期
ts = pl.Series(["-1300-05-23", "-1400-03-02"]).str.to_date()
negative_dates_df = pl.DataFrame({"ts": ts, "values": [3, 4]})
negative_dates_filtered_df = negative_dates_df.filter(pl.col("ts").dt.year() < -1300)
print(negative_dates_filtered_df)
#shape: (1, 2)
┌─────────────┬────────┐
│ ts ┆ values │
│ --- ┆ --- │
│ date ┆ i64 │
╞═════════════╪════════╡
│ -1400-03-02 ┆ 4 │
└─────────────┴────────┘
历史相关文章
- Python polars学习-01 读取与写入文件
- Python polars学习-02 上下文与表达式
- Python polars学习-03 数据类型转换
- Python polars学习-04 字符串数据处理
- Python polars学习-05 包含的数据结构
- Python polars学习-06 Lazy / Eager API
- Python polars学习-07 缺失值
- Python polars学习-08 分类数据处理
- Python polars学习-09 数据框关联与拼接
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
polars学习系列文章,第11篇 用户自定义函数,python 自定义函数如何与 polars 结合使用
该库目前已更新到 1.37.1 版本,近一年版本更新迭代的速度非常快,之前分享的前10篇文章的版本是 1.2.1
该系列文章会分享到github,大家可以去下载jupyter文件,进行参考学习 仓库地址:https://github.com/DataShare-duo/polars_learn
小编运行环境
import sys
print('python 版本:', sys.version.split('|')[0])
#python 版本: 3.11.11
import polars as pl
print("polars 版本:", pl.__version__)
#polars 版本: 1.37.1
提供的 api 函数/接口/方法
map_elements:对列中的每个值,传入函数,类似pandas中的mapmap_batches:整个列全部传入函数,类似pandas中的apply
示例数据
df = pl.DataFrame(
{
"keys": ["a", "a", "b", "b"],
"values": [10, 7, 1, 23],
}
)
print(df)
shape: (4, 2)
┌──────┬────────┐
│ keys ┆ values │
│ --- ┆ --- │
│ str ┆ i64 │
╞══════╪════════╡
│ a ┆ 10 │
│ a ┆ 7 │
│ b ┆ 1 │
│ b ┆ 23 │
└──────┴────────┘
map_elements 用法
import math
def my_log(value):
return math.log(value) # math.log 应用与每个值
out = df.select(pl.col("values").map_elements(my_log, return_dtype=pl.Float64))
print(out)
shape: (4, 1)
┌──────────┐
│ values │
│ --- │
│ f64 │
╞══════════╡
│ 2.302585 │
│ 1.94591 │
│ 0.0 │
│ 3.135494 │
└──────────┘
存在问题:
- 限于单个项:只用应用在单个值上面,而不能一次应用到整个列
- 性能开销:为每个单独的项调用函数也很慢,所有这些额外的函数调用会增加大量的开销
map_batches 用法
def diff_from_mean(series):
total = 0
for value in series:
total += value
mean = total / len(series)
return pl.Series([value - mean for value in series])
out = df.select(pl.col("values").map_batches(diff_from_mean, return_dtype=pl.Float64))
print("== select() with UDF ==")
print(out)
== select() with UDF ==
shape: (4, 1)
┌────────┐
│ values │
│ --- │
│ f64 │
╞════════╡
│ -0.25 │
│ -3.25 │
│ -9.25 │
│ 12.75 │
└────────┘
print("== group_by() with UDF ==")
out = df.group_by("keys").agg(
pl.col("values").map_batches(diff_from_mean, return_dtype=pl.Float64)
)
print(out)
== group_by() with UDF ==
shape: (2, 2)
┌──────┬───────────────┐
│ keys ┆ values │
│ --- ┆ --- │
│ str ┆ list[f64] │
╞══════╪═══════════════╡
│ a ┆ [1.5, -1.5] │
│ b ┆ [-11.0, 11.0] │
└──────┴───────────────┘
提升用户自定义函数性能
numpy 通用函数
纯python实现的自定义函数一般速度都比较慢,要尽量减少代用python实现的方法,可以调用 numpy 中的实现的通用函数/算子,来加速,实际是通过调用C语言的轮子来加速
import numpy as np
out = df.select(pl.col("values").map_batches(np.log, return_dtype=pl.Float64))
print(out)
通过 Numba 提升自定义函数性能
如果 numpy 中没有可用的函数,那么自定义函数可以通过 Numba 来提速,即时编译
from numba import guvectorize, int64, float64
@guvectorize([(int64[:], float64[:])], "(n)->(n)")
def diff_from_mean_numba(arr, result):
total = 0
for value in arr:
total += value
mean = total / len(arr)
for i, value in enumerate(arr):
result[i] = value - mean
out = df.select(
pl.col("values").map_batches(diff_from_mean_numba, return_dtype=pl.Float64)
)
print("== select() with UDF ==")
print(out)
out = df.group_by("keys").agg(
pl.col("values").map_batches(diff_from_mean_numba, return_dtype=pl.Float64)
)
print("== group_by() with UDF ==")
print(out)
注意事项
加速时,数据缺失是不行的,在利用numba装饰器@guvectorize加速时,要么填充缺失值,要么删除缺失值,否则polars会报错
组合多列
@guvectorize([(int64[:], int64[:], float64[:])], "(n),(n)->(n)")
def add(arr, arr2, result):
for i in range(len(arr)):
result[i] = arr[i] + arr2[i]
df3 = pl.DataFrame({"values_1": [1, 2, 3], "values_2": [10, 20, 30]})
out = df3.select(
pl.struct(["values_1", "values_2"])
.map_batches(
lambda combined: add(
combined.struct.field("values_1"), combined.struct.field("values_2")
),
return_dtype=pl.Float64,
)
.alias("add_columns")
)
print(out)
流式计算
可以使用 map_batches 的 is_elementwise=True 参数将结果流式传输到函数中
设置流式计算,需要确保是针对每个值进行计算,更节省内存
返回数据类型
返回数据类型是自动推断的,第一个非空值类型,作为结果类型
python 与 polars 数据类型映射:
- int -> Int64
- float -> Float64
- bool -> Boolean
- str -> String
- list[tp] -> List[tp]
- dict[str, [tp]] -> struct
- any -> object 尽量禁止这种情况
可以将 return_dtype 参数传递给 map_batches
历史相关文章
- Python polars学习-01 读取与写入文件
- Python polars学习-02 上下文与表达式
- Python polars学习-03 数据类型转换
- Python polars学习-04 字符串数据处理
- Python polars学习-05 包含的数据结构
- Python polars学习-06 Lazy / Eager API
- Python polars学习-07 缺失值
- Python polars学习-08 分类数据处理
- Python polars学习-09 数据框关联与拼接
- Python-polars学习-10-时间序列类型
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
由于昨天利用基础库Matplotlib画的不是很完美,今天借助高级可视化库pyecharts来重新再实现一下人民日报的各国疫情图。
pyecharts简介
Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了。
《人民日报》 VS pyecharts制作
数据均是截至到2020年3月14日0时,各国疫情累计确诊人数,可以明显看出人民日报的图可能是PS出来的~~~
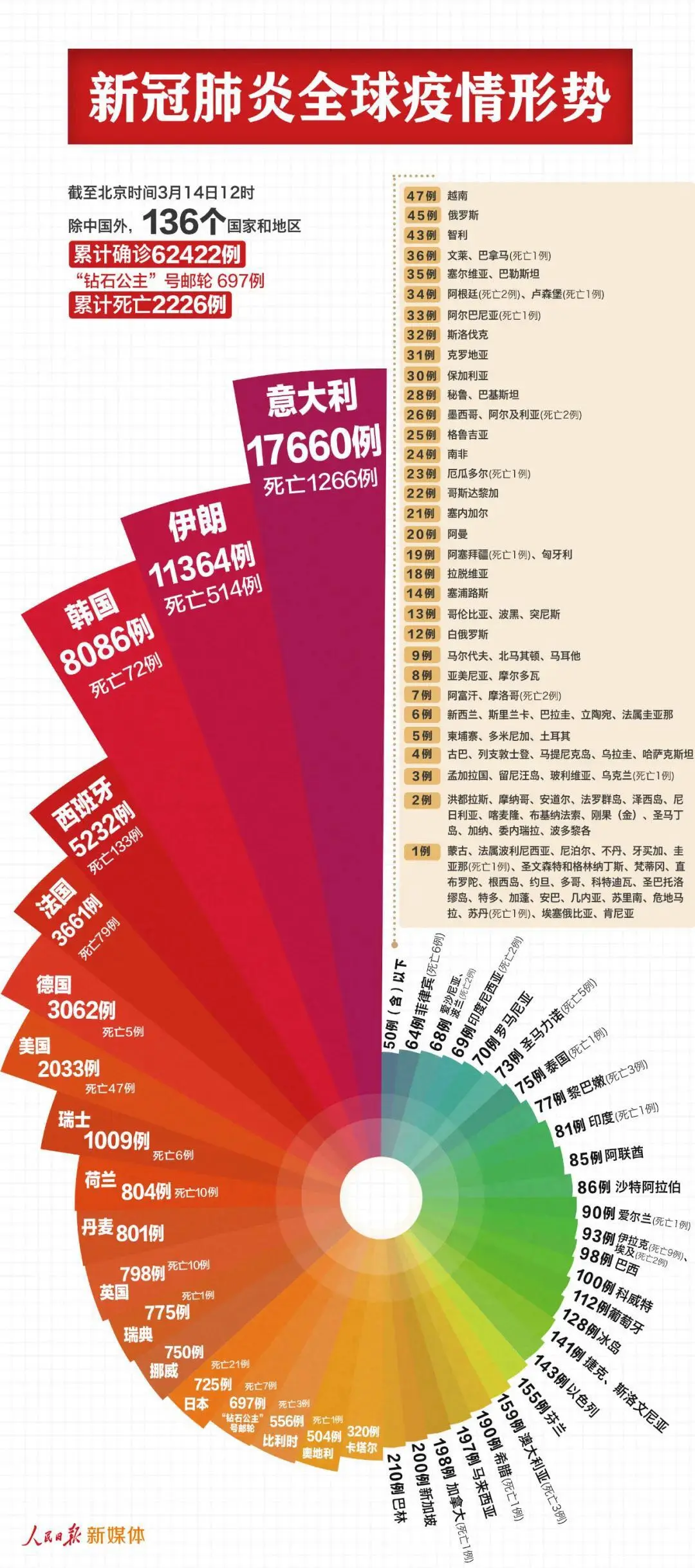

安装pyecharts
#在终端中安装,或者Anaconda Prompt 中
pip install pyecharts
#conda install pyecharts
#查看是否安装成功
import pyecharts
print(pyecharts.__version__)
# 1.7.1
整个画图代码
#导入pandas
import pandas as pd
#读取数据
data=pd.read_excel('海外疫情.xlsx')
#自定义了一个人民日报的颜色主题
from pyecharts.globals import CurrentConfig
CurrentConfig.ONLINE_HOST = "http://127.0.0.1:8000/assets/"
from pyecharts.datasets import register_files
register_files({"people_COVID": ["themes/people_COVID", "js"]})
#导入pyecharts用到的内容
from pyecharts import options as opts
from pyecharts.charts import Pie
#画图
p=Pie(init_opts=opts.InitOpts(width="1000px", height="1200px",theme='people_COVID'))
p.add('',
[list(z) for z in zip(data['国家'][:30],data['累计'][:30])],
radius=["7%", '100%'], #内半径,外半径
center=["50%", "60%"], #中心点的坐标位置
rosetype="area",
is_clockwise=False, #逆时针
label_opts=opts.LabelOpts(is_show=False)) #标签显示设置
p.set_global_opts(title_opts=opts.TitleOpts(title="新冠肺炎全球疫情形势",
pos_left="30%",
pos_top="12%",
title_textstyle_opts=opts.TextStyleOpts(font_size=30)
),
legend_opts=opts.LegendOpts(is_show=False)
)
p.render_notebook()
# p.render("pie.html")
参考资料
- http://gallery.pyecharts.org/#/Pie/pie_rosetype
- https://echarts.baidu.com/theme-builder/
- https://github.com/pyecharts/pyecharts-assets
- https://www.sioe.cn/yingyong/yanse-rgb-16/
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
中国在经历了非典后(2002年在中国广东发生),今年有经历了新冠肺炎,2020年注定是不平凡的一年。前一段时间人民日报的新冠肺炎全球疫情形势可视化图片在朋友圈疯狂传播,相信大部分人都不陌生,如下所示,自己闲暇之余就想用Python来实现一下,如下所示。
SARS事件是指严重急性呼吸综合征(英语:SARS)于2002年在中国广东发生,并扩散至东南亚乃至全球,直至2003年中期疫情才被逐渐消灭的一次全球性传染病疫潮。
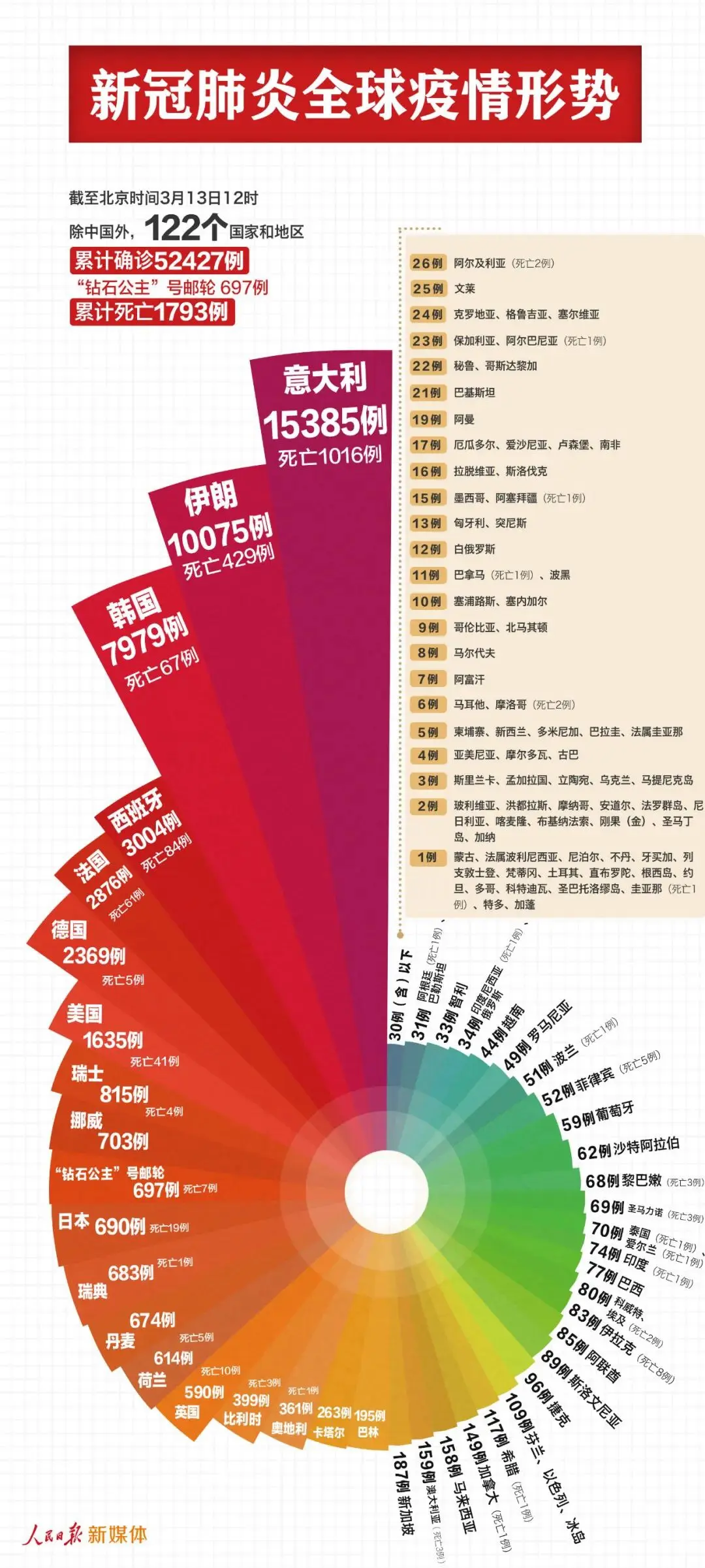

实现过程
- 数据源
各国的数据在网上都能查到,所以数据来源可以有很多方法。
由于自己主要是想画图,所以就直接手动创建了Excel,手动输入数据。
- 用到的Python库(轮子 or 模块)
Python在可视化方面有很多的库,比如:Matplotlib、Seaborn、ggplot、Pyecharts等,在这里使用的是最基础的Matplotlib库,数据读取用到的Pandas库,计算时用到Numpy库
- 具体代码如下所示
#导入相应的库
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#设置字体,可以在图上显示中文
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
#读取数据
data=pd.read_excel('海外疫情.xlsx',index_col=0)
#数据计算,这里只取前20个国家
radius = data['累计'][:20]
n=radius.count()
theta = np.arange(0, 2*np.pi, 2*np.pi/n)+2*np.pi/(2*n) #360度分成20分,外加偏移
#在画图时用到的 plt.cm.spring_r(r) r的范围要求时[0,1]
radius_maxmin=(radius-radius.min())/(radius.max()-radius.min()) #x-min/max-min 归一化
#画图
fig = plt.figure(figsize=(20,5),dpi=256)
ax = fig.add_subplot(projection='polar') #启用极坐标
bar = ax.bar(theta, radius,width=2*np.pi/n)
ax.set_theta_zero_location('N') #分别为N, NW, W, SW, S, SE, E, NE
ax.set_rgrids([]) #用于设置极径网格线显示
# ax.set_rticks() #用于设置极径网格线的显示范围
# ax.set_theta_direction(-1) #设置极坐标的正方向
ax.set_thetagrids([]) #用于设置极坐标角度网格线显示
# ax.set_theta_offset(np.pi/2) #用于设置角度偏离
ax.set_title('新冠肺炎全球疫情形势',fontdict={'fontsize':8}) #设置标题
#设置扇形各片的颜色
for r, bar in zip(radius_maxmin, bar):
bar.set_facecolor(plt.cm.spring_r(r))
bar.set_alpha(0.8)
#设置边框显示
for key, spine in ax.spines.items():
if key=='polar':
spine.set_visible(False)
plt.show()
#保存图片
fig.savefig('COVID.png')
总结
目前自己所实现的比较复杂的图形,有罗兰贝格图、本文的南丁格尔玫瑰图,用到的数据知识相对来说比较多,可见数学基础知识是多么重要,华为任正非的做法非常对,必须得注重基础数学的研发,不能总是在别人的基础之上搞应用,华为才有了今天的成绩
相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近项目在写报告时需要用到罗兰贝格图进行数据可视化呈现,罗兰贝格图如下所示,是用红色代表相对更强的方面,蓝色代表相对比较弱的方面,比如两个品牌在对比时,A品牌与B品牌,A品牌在哪些方面更有优势,在哪些方便相对比较薄弱。通过罗兰贝格图可以给人直观的印象,可视化出来能够使客户一眼判断出来。
Python等高线图
罗兰贝格图放在Python里面对应就是等高线图,等高线图在matplotlib库里面对应plt.contourf函数与plt.contour函数,熟悉里面的参数后基本都可以进行画图,由于我们的数据是一个表格(矩阵),只有对应的几个点,要想画出这种不规则的图,只能利用插值方法进行处理,然后需要把图形转换成平滑的形状。
遇到的难点:
- 0应该为白色,需要用来区分红色和蓝色,在画图时需要用自定义函数来处理
- 画的图要进行平滑处理,需要利用矩阵二次样条插值法
下面一步一步进行介绍:
-
1、添加上下边界
这个需要在Excel里面手动进行处理,放在python中也是可以处理,但是相对来说Excel里面更灵活,后面可以直接进行读取数据,然后画图。目的主要用来画图时,图的周边是白色
-
2、读取数据
从Excel文件里面读取数据
-
3、自定义插值函数
这里面用的是线性插值,在两个点中间插入一个新的点,新点的值为两边点的均值:$新点值x=\frac{a+b}{2}$,下面一共自定义两个,一个是用来对二维数据进行插值处理,一个是用来对一维数据进行插值
-
4、自定义颜色分割界线函数
主要用来规避等高线图里面自带的cmp参数的缺点,使0值作为红色与蓝色的对称中心,使红色分为5个区间,蓝色分为5个区间。这个自定义函数里面progression参数可以选择用等差还是等比来分割,默认的是等比,画图结果相对更美观一些
-
5、定义坐标点
定义坐标点后,并利用上面自定义的插值函数对x、y、Height各进行一次线性插值
-
6、进行平滑处理
运用scipy库里面的矩阵样条插值函数进行平滑度处理,详细参数含义可以查看官方文档https://docs.scipy.org/doc/scipy/reference/generated/scipy.interpolate.RectBivariateSpline.html#scipy.interpolate.RectBivariateSpline
- 7、画图
首先需要用到上面自定义的颜色分割界线函数计算一下分割界线,然后剩下的和正常的画图一样
- 8、最终结果
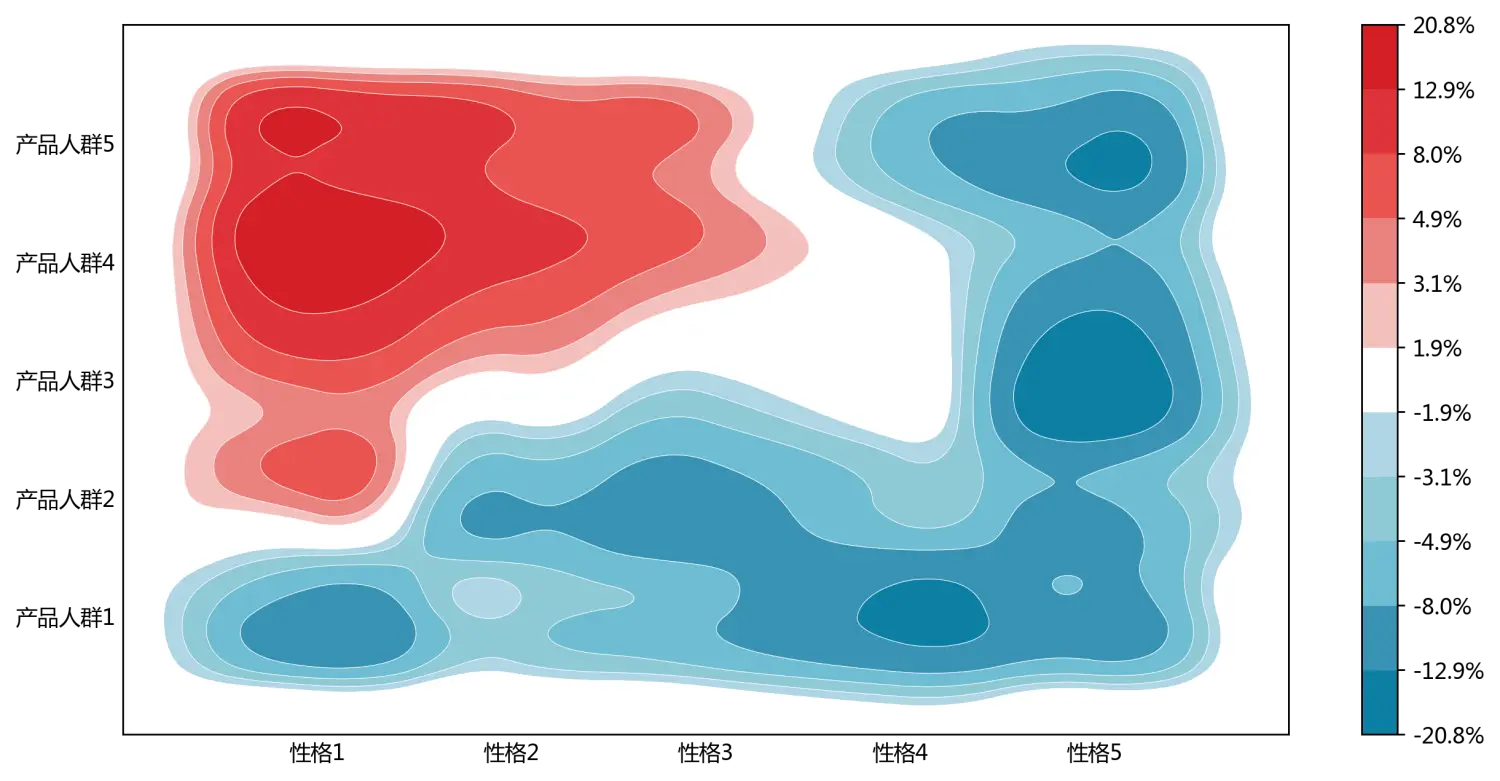
以上为整个罗兰贝格的画图步骤,下面展示全部的详细代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import interpolate #插值引用
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False
#加载数据
data=pd.read_excel('红蓝图制作数据.xlsx',sheet_name='python-简书',index_col=0)
data
#自定义插值函数---二维
def extend_data(data):
data=np.array(data)
def extend_x(X):
data=X.copy()
n=data.shape[1]
mid_extend=np.zeros(shape=(data.shape[0],n-1))
out=np.zeros(shape=(data.shape[0],2*n-1))
for i in range(n-1):
mid_extend[:,i]=(data[:,i]+data[:,i+1])/2.0
for i in range(2*n-1):
if i%2==0:
out[:,i]=data[:,0]
data=np.delete(data, 0, axis=1)
else:
out[:,i]=mid_extend[:,0]
mid_extend=np.delete(mid_extend, 0, axis=1)
return out
def extend_y(Y):
data=Y.T.copy()
return extend_x(data).T
data=extend_x(data)
data=extend_y(data)
return data
#自定义插值函数---一维
def extend_x(X):
data=X.copy()
n=data.shape[0]
mid_extend=np.zeros(n-1)
out=np.zeros(2*n-1)
for i in range(n-1):
mid_extend[i]=(data[i]+data[i+1])/2.0
for i in range(2*n-1):
if i%2==0:
out[i]=data[0]
data=np.delete(data, 0)
else:
out[i]=mid_extend[0]
mid_extend=np.delete(mid_extend, 0)
return out
#自定义颜色分割界线
def cmap_def(Height,progression='logspace'):
'''
white_min 白色下界
white_max 白色上界,与白色下界对称
n 在extend_Height最大值与白色上界等分的数量
progression 'logspace' 等差数列 'logspace'等比数列
返回:levels
'''
white_min=-1*np.max(np.abs(Height))/10 #白色下界
white_max=1*np.max(np.abs(Height))/10 #白色上界,与白色下界对称
n=6 #在Height最大值与白色上界等分的数量
Height_max=np.max(np.abs(Height))+np.max(np.abs(Height))/10
if progression=='linspace': #线性等差分割点
levels=list(np.linspace(-1*Height_max,white_min,n)) #小于白色下界值等分n
levels.extend(list(np.linspace(white_max,Height_max,n)))
else : #等比分割点
levels=-1*np.logspace(np.log(white_max),np.log(Height_max),n,base=np.e)
levels.sort()
levels=list(levels)
levels.extend(list(np.logspace(np.log(white_max),np.log(Height_max),n,base=np.e)))
return levels
x=np.array([0,1,2,3,4,5,6])
y=np.array([0,1,2,3,4,5,6])
Height=data.values
#先进行一次线性插值
n=1
x_extend=x.copy()
y_extend=y.copy()
Height_extend=Height.copy()
for i in range(n):
x_extend=extend_x(x_extend)
y_extend=extend_x(y_extend)
Height_extend=extend_data(Height_extend)
#进行矩阵二元样条插值
Height_R= interpolate.RectBivariateSpline(x_extend,y_extend,Height_extend,kx=2, ky=2,s=0.0000001)
x_new=np.linspace(0,6,2000)
y_new=np.linspace(0,6,2000)
X_new,Y_new=np.meshgrid(x_new, y_new)
Height_new=Height_R(x_new,y_new)
#颜色分割界线
levels=cmap_def(Height)
#自定义颜色阶
colors=['#0c7fa4','#3893b4','#6ebcd2','#8ec9d6','#afd5e4','#ffffff','#f4c0bd','#eb827f','#ea5350','#de333a','#d41f26']
#画图
fig=plt.figure(figsize=(12, 6),dpi=255)
# 填充颜色
a=plt.contourf(X_new, Y_new, Height_new, levels=levels, alpha =1,colors=colors)
# 绘制等高线
c= plt.contour(X_new, Y_new, Height_new, levels=levels, colors = 'white', linewidths=0.3,alpha=1,linestyles='solid')
b=plt.colorbar(a,ticks=levels)
b.set_ticklabels(ticklabels=[format(i,'.1%') for i in levels])
plt.xticks([1,2,3,4,5],labels=['性格1','性格2','性格3','性格4','性格5'])
plt.yticks([1,2,3,4,5],labels=['产品人群1','产品人群2','产品人群3','产品人群4','产品人群5'])
plt.tick_params(length=0) #不显示刻度线
# #去掉顶部、右边 边框
# ax = plt.gca()
# ax.spines['top'].set_visible(False)
# ax.spines['right'].set_visible(False)
plt.xlim(0,6)
plt.ylim(0,6)
# plt.grid() #网格线
plt.savefig('a_vs_b红蓝图.png',dpi=255) #保存图片
plt.show()
以上是自己实践中遇到的一些点,分享出来供大家参考学习,欢迎关注本简书号
作者:数据人阿多
背景
在复杂的数字中找规律,不如从一张图中看出规律,在平时的汇报时,PPT里面能展示的也就那么几种图表,但是合理的把数据展示出来,有时能让人眼前一亮,在数据分析中合理的运用可视化技术,有时可以起到事半功倍的效果
数据可视化是一门艺术,有时清晰的图表胜过千言万语,数据可视化的成功,往往并不在于数据可视化本身。
效果
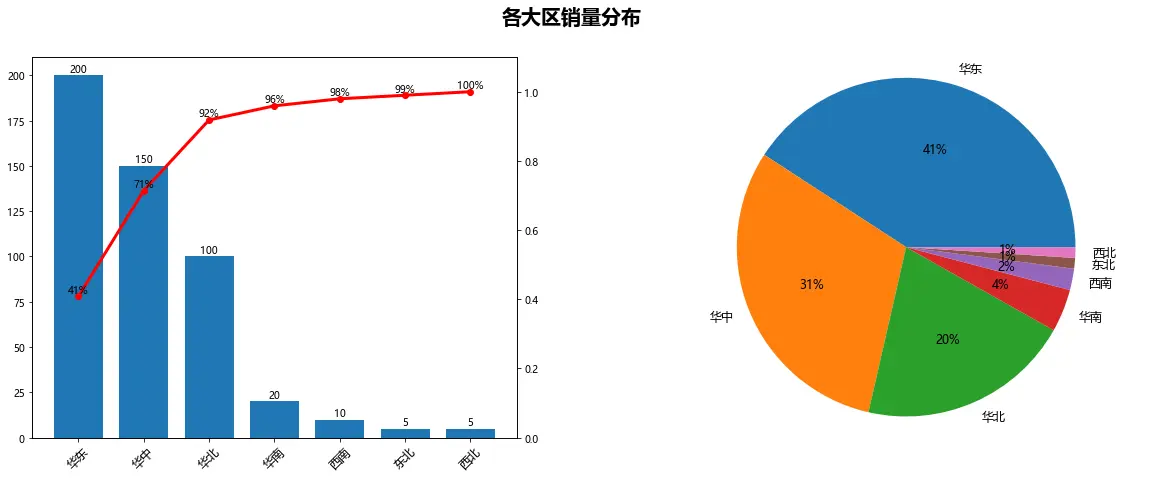
利用自定义函数画图
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import matplotlib.ticker as mticker
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#中文乱码的处理
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False
data=pd.read_excel('模拟数据.xlsx')
def axes_plot(axs1,axs2,x,y,rotation=0,axs1_twinx=False):
#柱形图个数
axs1.bar(x,y,width=0.75,align='center')
for a,b in zip(x,y):
axs1.text(a,b,b,ha='center',va='bottom')
axs1.tick_params(axis='x')
#修改x坐标轴
axs1.xaxis.set_major_locator(mticker.FixedLocator(range(len(x))))
axs1.set_xticklabels(x,rotation=rotation,fontsize=12)
#累计百分比
if axs1_twinx:
axs_twinx=axs1.twinx()
y_twinx=np.array(y).cumsum()/np.array(y).sum()
axs_twinx.plot(x,y_twinx,'r-o',linewidth=3)
axs_twinx.set_ylim(0,1.1)
for a,b in zip(x,y_twinx):
axs_twinx.text(a,b,f'{b:.0%}',ha='center',va='bottom')
#饼图
axs2.pie(y,labels=x,autopct='%.0f%%',textprops={'fontsize':12,'color':'k'})
axs2.axis('equal')
%matplotlib inline
fig,axes=plt.subplots(1,2,figsize=(20,7),facecolor='white')
fontsize=15
x=data['地区']
y=data['销量']
axes_plot(axes[0],axes[1],x,y,rotation=45,axs1_twinx=True)
fig.suptitle('各大区销量分布',fontsize=20,fontweight ="bold",y=0.98)
plt.subplots_adjust(hspace=0.35,wspace=0.3)
plt.show()
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在业务数据统计分析中基本都会涉及到各省区的分析,数据可视化是数据分析的一把利器,这些省区的数据一般会用地图可视化出来,这样一些规律可以被一面了然发现
地图有很多可视化类型,比如:基本地理图、热力图、路径图、涟漪图 等,本篇文章主要介绍 热力图,使用的工具百度开源 pyecharts
模拟数据以十一期间全国旅游景点热度为例(虚构数据)
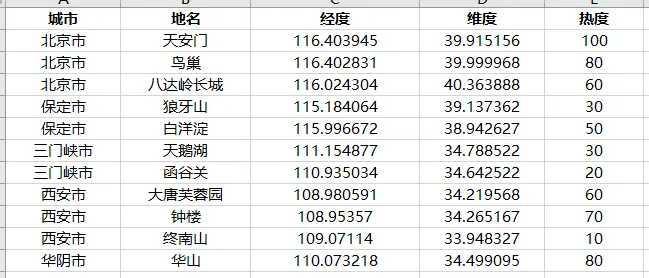
基于pyecharts内置经纬度的热力图
pyecharts 中自带了一些城市的经纬度,在画图时只要列出城市 or 省份的名字,即可在地图中自动展示,pyecharts会根据城市 or 省份的名字自动提取到经纬度
安装完pyecharts包之后,可以在pyecharts包文件夹里面找到相应的文件 city_coordinates.json ,里面保存了大量的地理名与经纬度的信息
一般路径如下:
xxxxxx\Lib\site-packages\pyecharts\datasets\city_coordinates.json
下面用模拟数据中 城市、热度 列来进行热力图可视化
左右滑动查看完整代码
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import BMap
from pyecharts.globals import BMapType
import json
data=pd.read_excel('热力图模拟数据.xlsx')
hotmap = (
BMap(is_ignore_nonexistent_coord=True, #忽略不存在的坐标
init_opts=opts.InitOpts(width="1300px", height="600px"))
.add_schema(baidu_ak="自己申请的key", center=[120.13066322374, 30.240018034923],
zoom=5, # 当前视角的缩放比例
is_roam=True # 是否开启鼠标缩放和平移漫游
)
.add(
"热度", #图例
data_pair=[list(z) for z in zip(data['城市'].to_list(), data['热度'].to_list())],
type_="heatmap",
label_opts=opts.LabelOpts(formatter="{b}"),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="十一期间全国旅游景点热度",
pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=32)
),
legend_opts=opts.LegendOpts(pos_right='20%'),
visualmap_opts=opts.VisualMapOpts()
)
.add_control_panel(
copyright_control_opts=opts.BMapCopyrightTypeOpts(position=3),
maptype_control_opts=opts.BMapTypeControlOpts(
type_=BMapType.MAPTYPE_CONTROL_DROPDOWN
),
scale_control_opts=opts.BMapScaleControlOpts(),
overview_map_opts=opts.BMapOverviewMapControlOpts(is_open=True),
navigation_control_opts=opts.BMapNavigationControlOpts(),
geo_location_control_opts=opts.BMapGeoLocationControlOpts(),
)
.render("基于pyecharts内置经纬度的热力图.html")
)
#hotmap.render_notebook()
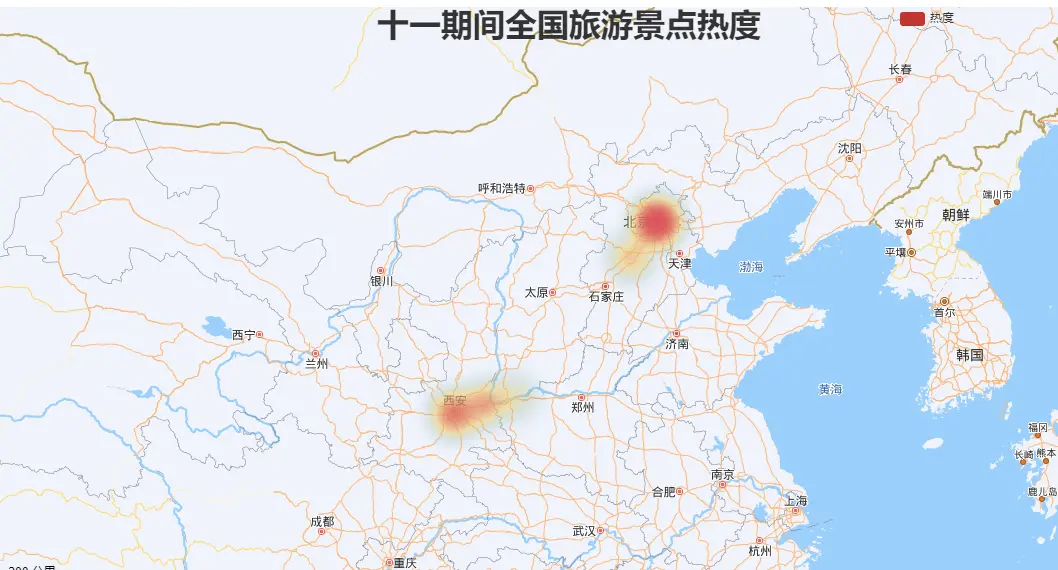
基于自定义经纬度的热力图
因pyecharts中的 city_coordinates.json 里面存放的均是一些常用的地理经纬度,如果想使用自定义的经纬度,pyecharts也是支持的
下面用模拟数据中 经度、维度、热度 列来进行热力图可视化
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import BMap
from pyecharts.globals import BMapType
import json
data=pd.read_excel('热力图模拟数据.xlsx')
data_json={}
for index,row in data.iterrows():
data_json[row['地名']]=[float(row['经度']),float(row['维度'])]
with open("BMAP.json","w") as f:
json.dump(data_json,f)
hotmap = (
BMap(is_ignore_nonexistent_coord=True, #忽略不存在的坐标
init_opts=opts.InitOpts(width="1300px", height="600px"))
.add_schema(baidu_ak="自己申请的key", center=[120.13066322374, 30.240018034923],
zoom=5, # 当前视角的缩放比例
is_roam=True # 是否开启鼠标缩放和平移漫游
)
.add_coordinate_json("BMAP.json") #加载自定义坐标
.add(
"热度", #图例
data_pair=[list(z) for z in zip(data['地名'].to_list(), data['热度'].to_list())],
type_="heatmap",
label_opts=opts.LabelOpts(formatter="{b}"),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="十一期间全国旅游景点热度",
pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=32)
),
legend_opts=opts.LegendOpts(pos_right='20%'),
visualmap_opts=opts.VisualMapOpts(max_=20) #设置最大值,目的是为了能够精确查看自定坐标位置
)
.add_control_panel(
copyright_control_opts=opts.BMapCopyrightTypeOpts(position=3),
maptype_control_opts=opts.BMapTypeControlOpts(
type_=BMapType.MAPTYPE_CONTROL_DROPDOWN
),
scale_control_opts=opts.BMapScaleControlOpts(),
overview_map_opts=opts.BMapOverviewMapControlOpts(is_open=True),
navigation_control_opts=opts.BMapNavigationControlOpts(),
geo_location_control_opts=opts.BMapGeoLocationControlOpts(),
)
.render("基于自定义经纬度的热力图.html")
)
#hotmap.render_notebook()
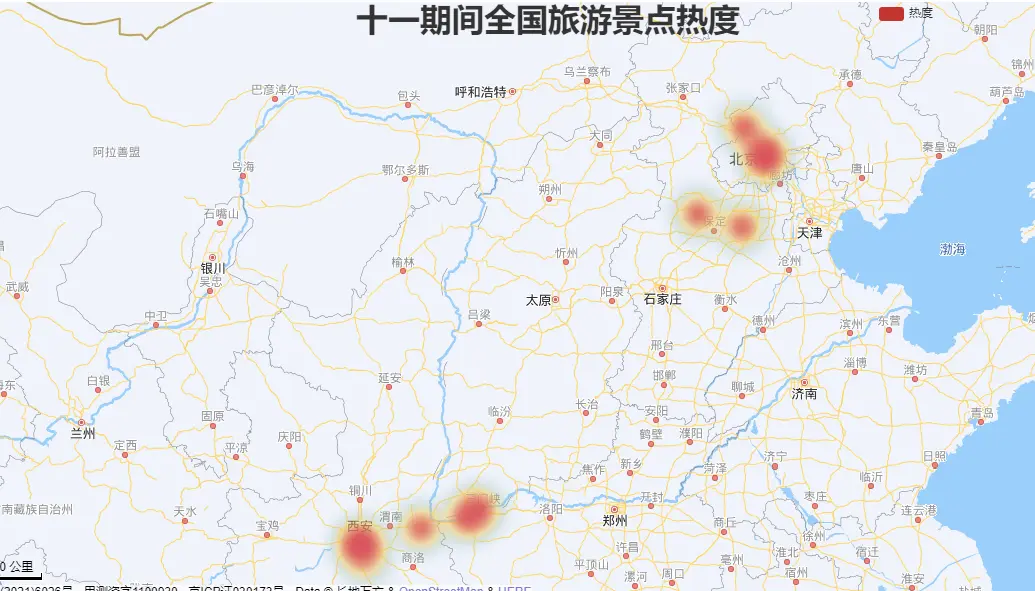
pyecharts库缺点
没有现成的方法用来直接导入自定义坐标,需要先把自定义坐标写在json文件中,然后再通过加载文件实现导入,而没有一个直接导入自定义坐标的方法,这个可以从源码中看出来,如果有一个 add_coordinate_dict 函数就完美了
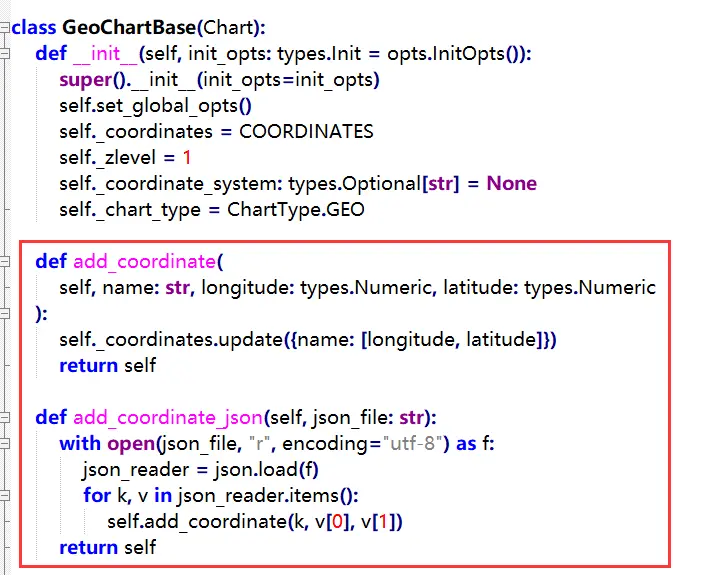
不同地图坐标系区别
我们通常用经纬度来表示一个地理位置,但是由于一些原因,我们从不同渠道得到的经纬度信息可能并不是在同一个坐标系下。
- 高德地图、腾讯地图以及谷歌中国区地图使用的是GCJ-02坐标系
- 百度地图使用的是BD-09坐标系
- 底层接口(HTML5 Geolocation或ios、安卓API)通过GPS设备获取的坐标使用的是WGS-84坐标系
不同的坐标系之间可能有几十到几百米的偏移,所以在开发基于地图的产品,或者做地理数据可视化时,我们需要修正不同坐标系之间的偏差。
WGS-84 - 世界大地测量系统
WGS-84(World Geodetic System, WGS)是使用最广泛的坐标系,也是世界通用的坐标系,GPS设备得到的经纬度就是在WGS84坐标系下的经纬度。通常通过底层接口得到的定位信息都是WGS84坐标系
GCJ-02 - 国测局坐标
GCJ-02(G-Guojia国家,C-Cehui测绘,J-Ju局),又被称为火星坐标系,是一种基于WGS-84制定的大地测量系统,由中国国测局制定。此坐标系所采用的混淆算法会在经纬度中加入随机的偏移。
国家规定,中国大陆所有公开地理数据都需要至少用GCJ-02进行加密,也就是说我们从国内公司的产品中得到的数据,一定是经过了加密的。绝大部分国内互联网地图提供商都是使用GCJ-02坐标系,包括高德地图,谷歌地图中国区等。
BD-09 - 百度坐标系
BD-09(Baidu, BD)是百度地图使用的地理坐标系,其在GCJ-02上多增加了一次变换,用来保护用户隐私。从百度产品中得到的坐标都是BD-09坐标系
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
大家在初中时,开始学习圆相关的知识,涉及圆的半径、周长、面积 等等,那会每位同学基本都会买一套圆规、三角板,来辅助学习和做作业使用,这些学习工具在闲暇时光也被用来玩耍,偶然间就拿着圆规在纸上画了这么一个图形,所有的圆心在同一个圆上,该图形一直记忆很深刻。自从学了Python 后就一直有这么一个念头,用Python把它实现出来,最近利用业余时间就给画了出来,分享出来供大家参考学习,也是数据可视化的一部分
效果图:
画圆的方法
画圆的方法,参考该篇文章:如何在 Matplotlib 中绘制圆,该文章一共介绍了3种方法,其中第2种方法:在 Matplotlib 中用圆方程绘制圆,可能有点不好理解,这里小编专门绘制了一个图来做解释,大家看了后应该可以理解
文章地址:https://www.delftstack.com/zh/howto/matplotlib/how-to-plot-a-circle-in-matplotlib/
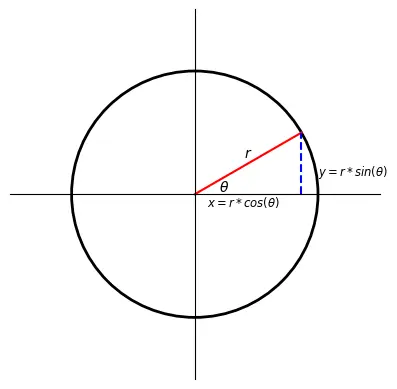
圆方程示例代码:
import numpy as np
from matplotlib import pyplot as plt
figure, axes = plt.subplots()
draw_circle = plt.Circle((0, 0), 1,fill=False,linewidth=2)
axes.set_aspect(1)
axes.add_artist(draw_circle)
#设置上边和右边无边框
axes.spines['right'].set_color('none')
axes.spines['top'].set_color('none')
#设置坐标轴位置
axes.spines['bottom'].set_position(('data', 0))
axes.spines['left'].set_position(('data',0))
plt.plot([0, np.cos(1/6*np.pi)], [0, np.sin(1/6*np.pi)],'r')
plt.plot([np.cos(1/6*np.pi), np.cos(1/6*np.pi)], [0, np.sin(1/6*np.pi)],'b--')
plt.xticks([])
plt.yticks([])
plt.xlim(-1.5,1.5)
plt.ylim(-1.5,1.5)
plt.text(x=0.4,y=0.3,s='$r$')
plt.text(x=0.2,y=0.02,s='$\\theta$')
plt.text(x=0.1,y=-0.1,s='$x=r * cos(\\theta)$',fontsize='small')
plt.text(x=1.,y=0.15,s='$y=r * sin(\\theta)$',fontsize='small')
plt.show()
初中时圆规画的图
圆心在同一个圆上代码:
import numpy as np
from matplotlib import pyplot as plt
theta = np.linspace(0, 2*np.pi, 25) #生成一些数据,用来计算圆上的点
radius = 2 #半径
x = radius*np.cos(theta) #圆心的横坐标 x
y = radius*np.sin(theta) #圆心的横坐标 y
figure, axes = plt.subplots(1,1,figsize=(20,7),facecolor='white',dpi=500)
for circle_x,circle_y in zip(x,y):
draw_circle = plt.Circle((circle_x, circle_y), radius,fill=False) #画圆
axes.add_artist(draw_circle)
axes.set_aspect(1)
plt.xlim(-5,5)
plt.ylim(-5,5)
plt.axis('off')
plt.show()
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
一图胜千言,优秀的可视化图表不仅能以直观、简洁的方式呈现复杂的信息,还能够通过图形、颜色和布局的巧妙设计,引发观众的情感共鸣,增强数据背后故事的表达力与说服力。它们超越了单纯的数据展示,更能帮助观众深入理解潜在的趋势、关系和模式,从而更有效地支持决策和行动
小编环境
import sys
print('python 版本:',sys.version)
#python 版本: 3.11.11 | packaged by Anaconda, Inc. |
#(main, Dec 11 2024, 16:34:19) [MSC v.1929 64 bit (AMD64)]
import matplotlib
print(matplotlib.__version__)
#3.10.0
import numpy
print(numpy.__version__)
#2.2.2
效果展示
完整代码
#导入库
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import numpy as np
#生成数据
num_points = 100
x,y = np.random.rand(2,num_points)*10
#生成颜色和大小数据
colors = np.random.rand(num_points)
sizes =np.random.rand(num_points)*1000
#创建图形和散点图
fig, ax = plt.subplots()
scat =ax.scatter(x,y,c=colors,s=sizes, alpha=0.7, cmap='plasma') #viridis
ax.set_xlim(0,10)
ax.set_ylim(0,10)
#创建动画更新函数
def animate(i):
new_x=x+np.random.randn(num_points)*0.1
new_y=y+np.random.randn(num_points)*0.1
scat.set_offsets(np.c_[new_x,new_y]) #更新散点图中所有点的坐标
return scat,
ani = animation.FuncAnimation(fig,animate,frames=100,interval=150)
ani.save('plasma.gif', writer='pillow', fps=10) #viridis
这里重点是创建动画更新函数 animate,用于更新每一帧散点图中的点的位置,传入的参数 i 代表帧编号参数,是 FuncAnimation 每次调用更新函数时传入的参数,表示当前动画帧的索引
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
本文借助 plotly 库来画旭日图,该库是一个高级可视化库,相对 Matplotlib 更高级一些,上手起来相对比较容易
- 低阶API:Plotly Graph Objects(go)
- 高阶API:Plotly Express(px)
效果展示

小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.9
import plotly
print("plotly 版本:",plotly.__version__)
#plotly 版本: 5.23.0
方法1
import plotly.express as px
#数据
data ={
'id':['A','B','C','D','E','F','G'],
'parent':['','A','A','B','B','C','D'],
'value':[10,15,7,8,12,6,5]
}
#创建旭日图
fig = px.sunburst(data, names='id', parents='parent', values='value')
#设置标题
fig.update_layout(title_text="旭日图",title_x=0.5)
#展示图片
fig.show()
方法2
import plotly.graph_objects as go
data ={
'id':['A','B','C','D','E','F','G'],
'parent':['','A','A','B','B','C','D'],
'value':[10,15,7,8,12,6,5]
}
fig = go.Figure(go.Sunburst(
labels=data['id'],
parents=data['parent'],
values=data['value'],
))
fig.update_layout(
{'title':{
'text':'<b>旭日图</b>',
'x':0.5, #居中对齐
'xanchor': 'center',
'yanchor': 'top',
'font': {'size': 32, 'color':'black', 'family':'微软雅黑'},
}}
)
fig.show()
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
本文借助 plotly 库来绘制时间线图,该库是一个高级可视化库,相对 Matplotlib 更高级一些,上手相对比较容易
- 低阶API:Plotly Graph Objects(go)
- 高阶API:Plotly Express(px)
小编环境
import sys
import plotly
import pandas as pd
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
print("plotly 版本:",plotly.__version__)
#plotly 版本: 5.24.1
print("pandas 版本:", pd.__version__)
#pandas 版本: 2.2.2
时间线图效果
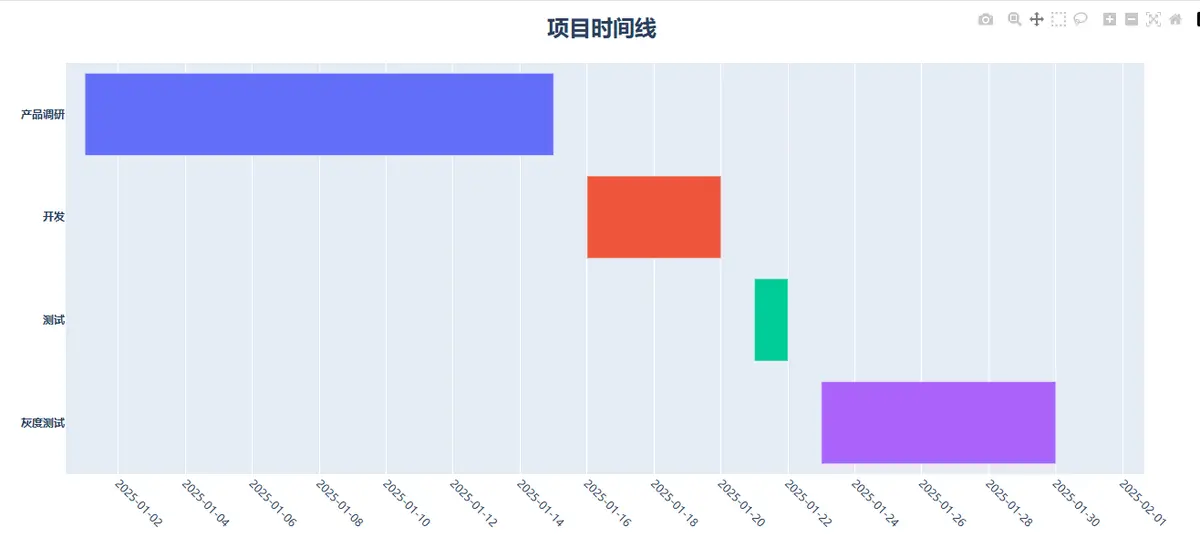
完整代码
import plotly.express as px
import pandas as pd
import plotly.io as pio
pio.renderers.default = "browser" # 设置默认渲染器为浏览器
#创建模拟数据
df = pd.DataFrame([
dict(Task='产品调研',Start='2025-01-01',Finish='2025-01-15'),
dict(Task='开发',Start='2025-01-16',Finish='2025-01-20'),
dict(Task='测试',Start='2025-01-21',Finish='2025-01-22'),
dict(Task='灰度测试',Start='2025-01-23',Finish='2025-01-30')
]
)
#画图
fig=px.timeline(
df,
x_start='Start',
x_end='Finish',
y='Task',
color='Task'
)
# 设置全局字体为微软雅黑
fig.update_layout(
font_family="Microsoft YaHei", # 设置全局字体家族
showlegend=False, # 隐藏图例
title_text='项目时间线', # 图表标题
title_font_size=24, # 标题字体大小
title_x=0.5,
title_font_weight='bold',
xaxis_tickfont_size=16, # X轴刻度标签字体大小
# xaxis_tickfont_weight='bold',
yaxis_tickfont_weight='bold',
)
# fig.update_yaxes(autorange='reversed') #y轴翻转显示
fig.update_yaxes(title_text='')
# 精细控制X轴(日期轴)的显示
fig.update_xaxes(
tickmode='auto', # 让Plotly自动选择刻度位置,但我们会规定格式
tickformat='%Y-%m-%d', # 设置x轴日期格式为 yyyy-MM-dd
nticks=20, # 建议显示的刻度数量(Plotly可能不会完全遵守)
tickangle=45, # 刻度标签旋转45度,避免重叠
tickfont_size=12, # 刻度标签的字体大小
)
fig.show()
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
动漫效果的头像最近比较火,微信里面有大量的朋友都是使用这种风格的头像,在一些软件里面也慢慢开始集成该功能,在手机里面可以直接制作出动漫效果的图片
这种风格的图片是怎么生成的呢,那就不得不说最近这几年大火的AI,也就是神经网络模型,可以用来处理目前的一些问题,比如:自然语言/NLP类、图像/CV类、声音类 等,动漫图片就归属于图像/CV类中的一种,本篇文章主要是介绍一个开源的模型,来生成这种动漫效果的图片
动漫效果

开源项目介绍
最近发现一个开源项目可以实现该功能,其模型的权重只有 8.2M ,相对一些大的模型来说已经很轻量级了,并且该模型在自己的笔记本电脑能够很好运行,你可以直接下载该项目到自己的电脑里面,来处理自己想要的图片
pytorch版本地址:(本文基于pytorch版本)
https://github.com/bryandlee/animegan2-pytorch
tensorflow版本地址:
https://github.com/TachibanaYoshino/AnimeGANv2
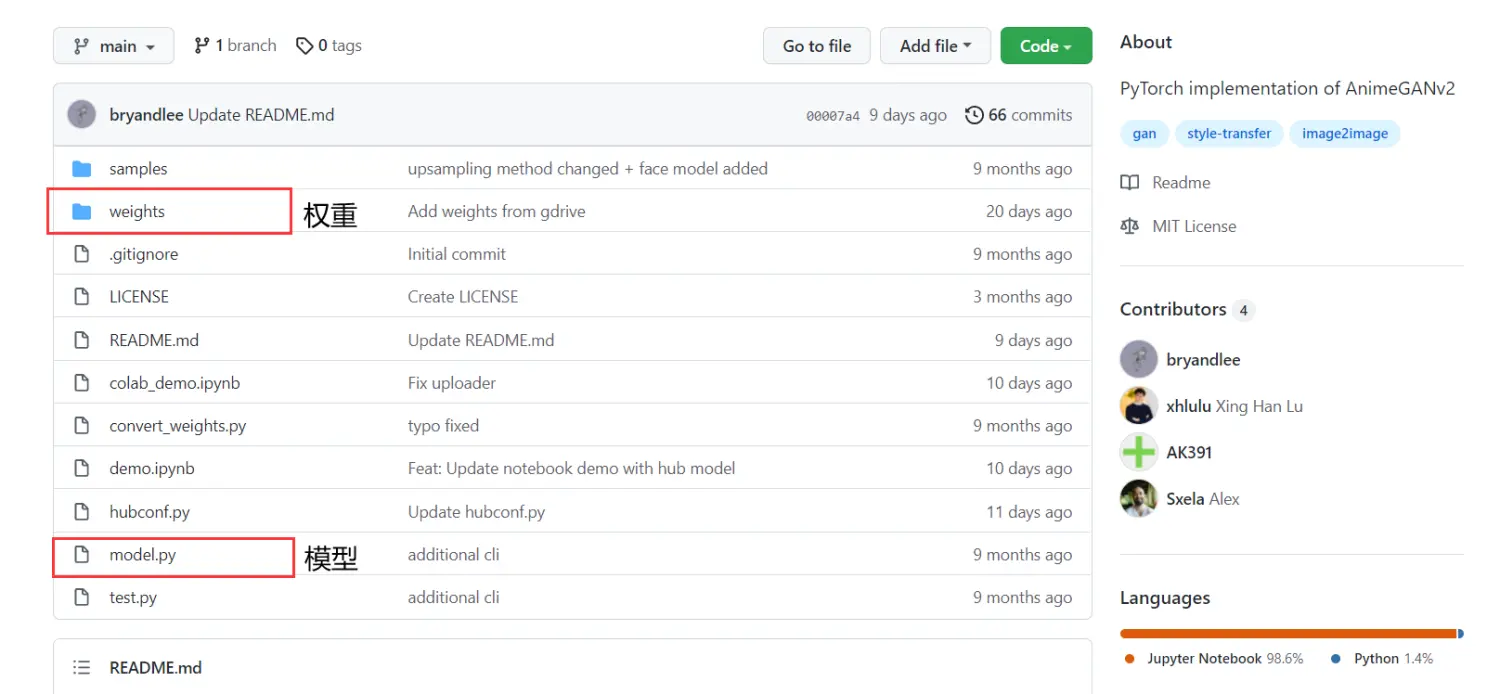
自己动手实践
本篇文章里面的代码是依赖开源项目中的
模型框架: model.py
模型权重: weights文件夹里面的4个权重文件
其他的文件没有涉及,下载开源项目后,用以下的脚本在开源项目里面运行后,生成的结果图片会放在当前目录的 animegan_outs 里面,运用模型的4个不同权重,最终会生成4张不同风格的动漫图片
需要的环境,第三方库:pytorch、opencv
import torch
import cv2
import numpy as np
import os
import shutil
from model import Generator
from torchvision.transforms.functional import to_pil_image
from PIL import Image
def load_image(image_path):
img = cv2.imread(image_path).astype(np.float32)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = torch.from_numpy(img)
img = img/127.5 - 1.0
return img
image = load_image('yangmi.jpg') #RGB 此处需要加载自己的图片
#image.shape #HWC
models=['face_paint_512_v2','face_paint_512_v1','paprika','celeba_distill']
models_path=[f'./weights/{model}.pt' for model in models]
if os.path.exists('./animegan_outs/'):
shutil.rmtree('./animegan_outs')
os.makedirs('./animegan_outs/')
else:
os.makedirs('./animegan_outs/')
device='cpu'
net = Generator()
images=[]
for model,model_path in zip(models,models_path):
net.load_state_dict(torch.load(model_path, map_location="cpu"))
net.to(device).eval()
with torch.no_grad():
input = image.permute(2, 0, 1).unsqueeze(0).to(device) #BCHW
out = net(input, False).squeeze(0).permute(1, 2, 0).cpu().numpy() #HWC
out = (out + 1)*127.5
out = np.clip(out, 0, 255).astype(np.uint8)
pil_out=to_pil_image(out)
pil_out.save(f'./animegan_outs/{model}.jpg') #保存处理过后的图片
images.append(pil_out)
font=cv2.FONT_HERSHEY_SIMPLEX #使用默认字体
UNIT_WIDTH_SIZE,UNIT_HEIGHT_SIZE=images[0].size[:2]
images_add_font=[] #保存加了文字之后的图片
for model,image in zip(models,images):
image_font=cv2.putText(np.array(image),model,(280,50),font,1.2,(0,0,0),3)
#添加文字,1.2表示字体大小,(280,50)是初始的位置,(0,0,0)表示颜色,3表示粗细
images_add_font.append(Image.fromarray(image_font))
target = Image.new('RGB', (UNIT_WIDTH_SIZE * 2, UNIT_HEIGHT_SIZE * 2)) #创建成品图的画布
#第一个参数RGB表示创建RGB彩色图,第二个参数传入元组指定图片大小,第三个参数可指定颜色,默认为黑色
for row in range(2):
for col in range(2):
#对图片进行逐行拼接
#paste方法第一个参数指定需要拼接的图片,第二个参数为二元元组(指定复制位置的左上角坐标)
#或四元元组(指定复制位置的左上角和右下角坐标)
target.paste(images_add_font[2*row+col], (0 + UNIT_WIDTH_SIZE*col, 0 + UNIT_HEIGHT_SIZE*row))
target.save('./animegan_outs/out_all.jpg', quality=100) #保存合并的图片
生成的动漫图片






历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近项目需要用人脸检测技术把视频里面的人脸检测出来后,进行马赛克处理,人脸检测这一块就是大家熟知的利用深度学习技术来解决
之前有相关文章介绍,这篇文章主要介绍马赛克处理过程
马赛克原理
图片是由一个三维数组,打马赛克就是把特定区域的值替换为其他值,项目在做的过程中经过一次升级,最开始用的是高斯马赛克,后来应客户的要求,升级为和其他软件手工打的马赛克一样的样式正规马赛克
- 高斯马赛克
特定区域值替换为高斯分布数值,可以利用numpy中的np.random.normal(size=(h,w))来生成一些随机的数值,然后进行替换即可
- 正规马赛克
马赛克的实现原理是把图像上某个像素点一定范围邻域内的所有点用邻域内左上像素点的颜色代替,这样可以模糊细节,但是可以保留大体的轮廓。就是用左上角的那个值,来替换右下方一个小方块的值,逐步进行替换即可。
代码
- 高斯马赛克
import cv2
import numpy as np
face_location=[430,500,730,870] #x1,y1,x2,y2 x1,y1为人脸左上角点;x2,y2为人脸右下角点
img=cv2.imread('./tongliya.jpg') #opencv读取的是BGR数组
##高斯马赛克
def normal_mosaic(img, x1, y1, x2, y2):
img[y1:y2, x1:x2, 0] = np.random.normal(size=(y2-y1, x2-x1))
img[y1:y2, x1:x2, 1] = np.random.normal(size=(y2-y1, x2-x1))
img[y1:y2, x1:x2, 2] = np.random.normal(size=(y2-y1, x2-x1))
return img
x1=face_location[0]
y1=face_location[1]
x2=face_location[2]
y2=face_location[3]
img_mosaic=normal_mosaic(img, x1, y1, x2, y2)
cv2.imwrite('img_mosaic_normal.jpg',img_mosaic)
- 正规马赛克
import cv2
import numpy as np
face_location=[430,500,730,870] #x1,y1,x2,y2 x1,y1为人脸左上角点;x2,y2为人脸右下角点
img=cv2.imread('./tongliya.jpg') #opencv读取的是BGR数组
#正规马赛克
def do_mosaic(img, x, y, w, h, neighbor=9):
"""
:param rgb_img
:param int x : 马赛克左顶点
:param int y: 马赛克左顶点
:param int w: 马赛克宽
:param int h: 马赛克高
:param int neighbor: 马赛克每一块的宽
"""
for i in range(0, h , neighbor):
for j in range(0, w , neighbor):
rect = [j + x, i + y]
color = img[i + y][j + x].tolist() # 关键点1 tolist
left_up = (rect[0], rect[1])
x2=rect[0] + neighbor - 1 # 关键点2 减去一个像素
y2=rect[1] + neighbor - 1
if x2>x+w:
x2=x+w
if y2>y+h:
y2=y+h
right_down = (x2,y2)
cv2.rectangle(img, left_up, right_down, color, -1) #替换为为一个颜值值
return img
x=face_location[0]
y=face_location[1]
w=face_location[2]-face_location[0]
h=face_location[3]-face_location[1]
img_mosaic=do_mosaic(img, x, y, w, h, neighbor=15)
cv2.imwrite('img_mosaic.jpg',img_mosaic)
效果



历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号DataShare,不定期分享干货
作者:数据人阿多
背景
大家在制作视频时,是不是见过一种特效:图片从清晰状态慢慢渐变为模糊状态,视频其实也就是每一帧图片拼接组成,今天就来介绍下怎么把图片模糊化,主要运用的原理就是多维高斯滤波器
效果展示

小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.4
完整代码
%matplotlib qt
from scipy import ndimage
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
#中文乱码的处理
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
def blur_image(image_path):
image=np.array(Image.open(image_path))
image = np.rot90(image,-1) #对图片顺时针旋转90度
plt.figure(figsize=(5, 15),dpi=100)
plt.subplot(221)
plt.imshow(image)
plt.title("原始图片")
plt.axis( 'off')
sigma = 5
blurred_image = np.zeros(image.shape, dtype=np.uint8)
for i in range(3): #对图像的每一个通道都应用高斯滤波
blurred_image[:,:,i] = ndimage.gaussian_filter(image[:,:,i], sigma)
plt.subplot(222)
plt.imshow(blurred_image)
plt.title(f'模糊化的图像 (sigma={sigma})')
plt.axis('off')
sigma = 10
blurred_image = np.zeros(image.shape, dtype=np.uint8)
for i in range(3): #对图像的每一个通道都应用高斯滤波
blurred_image[:,:,i] = ndimage.gaussian_filter(image[:,:,i], sigma)
plt.subplot(223)
plt.imshow(blurred_image)
plt.title(f'模糊化的图像 (sigma={sigma})')
plt.axis('off')
sigma = 20
blurred_image = np.zeros(image.shape, dtype=np.uint8)
for i in range(3): #对图像的每一个通道都应用高斯滤波
blurred_image[:,:,i] = ndimage.gaussian_filter(image[:,:,i], sigma)
plt.subplot(224)
plt.imshow(blurred_image)
plt.title(f'模糊化的图像 (sigma={sigma})')
plt.axis('off')
plt.subplots_adjust(top=0.9,
bottom=0.1,
left=0.125,
right=0.9,
hspace=0.05,
wspace=0.07)
plt.show()
image_path ='秋天的银杏树.jpg'
blur_image(image_path)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在对视频进行人脸打码时,需要从磁盘读取视频帧,然后通过训练好的深度神经网络模型进行人脸监测,获取到人脸的位置后,然后进行打码。
opencv读取多张视频帧,提高性能
由于opencv每次只能读取一张视频帧,然后把这一张视频帧送入神经网络模型进行人脸监测,这样逐帧的处理视频,速度相对来说比较慢。
为了提高性能,需要进行优化。如果对训练深度神经网络模型,原理了解的话,那么可以每次传入多个视频帧,这样每次作为一个batch,使计算效率更高一些。深度神经网络模型在训练时,是每次处理一个batch图像,来通过梯度下降,优化模型参数。
这样就需要opencv每次读取多个视频帧,但是opencv里面没有这样的方法,只能自己去实现这样的方法。
实例代码
import cv2
import numpy as np
video_full_path_and_name='./test.mp4'
videoCapture = cv2.VideoCapture() # 创建视频读取对象
videoCapture.open(video_full_path_and_name) # 打开视频
fps = int(round(videoCapture.get(cv2.CAP_PROP_FPS),0))
image_width=int(videoCapture.get(cv2.CAP_PROP_FRAME_WIDTH)) #视频帧宽度
image_height=int(videoCapture.get(cv2.CAP_PROP_FRAME_HEIGHT)) #视频帧高度
image_channel=3 #RGB 3通道
ret=True
while ret:
img_batch_rgb=np.empty(shape=[0,image_height,image_width,image_channel],dtype=np.uint8)
#每次读取1s的视频帧,可以根据自己的内存大小,每次读取多秒
for i in range(fps*1):
ret, img = videoCapture.read()
#读取到图像帧
if ret:
# opencv:BGR 转换为 RGB
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_batch_rgb=np.append(img_batch_rgb,np.expand_dims(rgb_img, 0),axis=0)
else:
break
print(img_batch_rgb.shape,flush=True)
#img_batch_rgb #该变量即为多个视频帧
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号,不定期分享干货
作者:数据人阿多
背景
由于最近项目的要求,需要对视频里面出现的所有人脸进行打马赛克,调研了相关的方法,总结了一下,供大家参考。 大家都知道视频其实是有很多张图片(帧)组成的,那么只要把图片中的人脸检测出来,那么视频就迎刃而解了。
帧数就是在1秒钟时间里传输的图片的量,也可以理解为图形处理器每秒钟能够刷新几次,通常用fps(Frames Per Second)表示。每一帧都是静止的图象,快速连续地显示帧便形成了运动的假象。高的帧率可以得到更流畅、更逼真的动画。帧数 (fps) 越高,所显示的动作就会越流畅。 但是文件大小会变大
人脸检测 vs 人脸识别
人脸检测 与 人脸识别 是两个不同的概念
人脸检测
检测图片里面有没有人脸
人脸识别
首先检测出图片中的人脸,再与已知的人脸做对比,看这个人脸是张三的,还是李四的,常见应用:人脸识别上班打卡
方法总结
- opencv
最简单、速度最快的方法,但效果一般
- face_recongnition(基于dlib)
可选参数 hog 、cnn
pip有发布的库,不用自己训练模型,可以直接拿来使用,比较方便,效果较好 https://github.com/ageitgey/face_recognition face_recognition模块方法集合
- mtcnn(基于tensorflow)
需要训练自己的模型,github有开源的项目,效果较好 https://github.com/ipazc/mtcnn
- RetinaFace(基于pytorch)-----------最终采用
需要训练自己的模型,github有开源的项目,效果最好 https://github.com/supernotman/RetinaFace_Pytorch
以上这些都是自己亲自试验过的人脸检测方法,RetinaFace(基于pytorch) 方法效果最好,最终采用这种方法,进行了一些优化
- 其他一些方法
RetinaFace效果



历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号,不定期分享干货
作者:数据人阿多
背景
前段时间因为要办理一些事情,需要家里人拍 户口本首页 和 个人所在页 的照片用来打印,家里父亲已经年过六旬,能学会玩微信已经实属不易,让父亲用手机拍出很正的图片有点太难,户口本首页 拍了有5张以上,里面有一张比较清晰,能凑合着用,但还是不正,于是想着能不能 旋转 一下,让照片变正。因之前对opencv有所了解,就查找相关文档,然后对图片进行处理,3步即可搞定,最后大功告成!!!

基于opencv图片处理过程
1.安装opencv
由于opencv为第三方库,需要手动安装一下,安装成功后即可导入使用
pip install opencv-python
2.确定照片上4个点
可以想象一下,把照片看成一个空间,要想把照片旋转正,我们可以拽着户口本首页4个角,给拽到图片的4个角,有点立体的感觉,如下图所示:

确定照片上这4个点的方法比较多,比如:我们可以直接用尺子测量一下、根据截图大小计算一下等。
但是作为会编程的人员,我们可以有更好的方法:点击图片上的4个点,可以直接出现相应的位置(x坐标,y坐标)。
经过在网上查找了相关的帖子后,opencv就可以实现这个功能,结果如下:

代码如下:
#加载库
import cv2
import numpy as np
img = cv2.imread('home-1.jpg')
img.shape #图片尺寸大小
#(1080, 1456, 3)
#定义函数,实现在图片上显示坐标位置
def on_EVENT_LBUTTONDOWN(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
xy = "(%d,%d)" % (x, y)
print(xy)
cv2.circle(img, (x, y), 10, (0, 176, 80), thickness = -1)
if (x+50)>img.shape[1] & x>(img.shape[1]/2):
cv2.putText(img, xy, (x-180, y-10), cv2.FONT_HERSHEY_PLAIN,2.0, (0,0,255), thickness = 2)
elif x<50:
cv2.putText(img, xy, (x, y-10), cv2.FONT_HERSHEY_PLAIN,2.0, (0,0,255), thickness = 2)
else:
cv2.putText(img, xy, (x-20, y-10), cv2.FONT_HERSHEY_PLAIN,2.0, (0,0,255), thickness = 2)
cv2.imshow("image", img)
cv2.namedWindow("image",0)
cv2.resizeWindow("image", 640, 480)
cv2.setMouseCallback("image", on_EVENT_LBUTTONDOWN)
cv2.imshow("image", img)
while(True):
try:
cv2.waitKey(10)
except:
cv2.destroyWindow("image")
break
cv2.waitKey(10)
cv2.destroyAllWindow()
代码执行过程中,唯一不足一点为,最后需要手动强制退出程序,结束循环
3.旋转图片
根据上面大概确定好4个点的位置后,下面调用opencv的透视变换函数cv2.warpPerspective,对进行图片旋转,旋转时坐标位置可以根据实际结果进行调节,是否想多显示一点边界,可以调整x,y坐标大小,旋转后效果如下,照片基本算是比较平整,没有出现明显的波纹,打印出来可以用

代码如下:
import cv2
import numpy as np
img = cv2.imread('home-1.jpg')
#确定位置,旋转前后位置要相互对应,坐标位置可以根据实际来调节
pts1 = np.float32([[202,70],[120,1040],[1415,135],[1435,1055]]) #左上 左下 右上 右下
pts2 = np.float32([[0,0],[0,1080],[1456,0],[1456,1080]])
#进行旋转
M = cv2.getPerspectiveTransform(pts1,pts2)
home_P = cv2.warpPerspective(img,M,(cols,rows))
#保存旋转后的图片
cv2.imwrite("home_P.jpg", home_P, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
- 参考文章
- https://blog.csdn.net/huzhenwei/article/details/82900715
- https://segmentfault.com/a/1190000015645951
以上是自己实践中遇到的一些点,分享出来供大家参考学习,欢迎关注本简书号
作者:数据人阿多
背景
不论是在进行深度学习时的图片处理,还是在商业用途出版书刊,基本都会用到对图片进行灰度转换,也就是灰度化,本文章利用简单的4行代码来快速实现图片灰度化,仅供参考
效果
实现代码
from PIL import Image
wechat_image='./微信头像.jpg'
wechat_image_greyscale=Image.open(wechat_image).convert('L') #对图片进行灰度化
wechat_image_greyscale.save('微信头像_灰度化.jpg')
图像灰度转化
图像是由红(Red)、绿(Green)、蓝(Blue)三原色来表示,R、G、B的取值范围均为0~255,正常读取的图片构成的三维矩阵就是图像各像素点的RGB值
图像的灰度化,就是让像素点矩阵中的每一个像素点都满足这样的关系:
R=G=B,此时的这个值叫做 灰度值 :
灰度化后的R = 处理前的R * 0.299+ 处理前的G * 0.587 +处理前的B * 0.114
灰度化后的G = 处理前的R * 0.299+ 处理前的G * 0.587 +处理前的B * 0.114
灰度化后的B = 处理前的R * 0.299+ 处理前的G * 0.587 +处理前的B * 0.114
PIL库里面在灰度转化时,利用的公式
When translating a color image to greyscale (mode "L"), the library uses the ITU-R 601-2 luma transform:
L = R * 299/1000 + G * 587/1000 + B * 114/1000
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近看到其他公众号发的一篇文章《三个印度人改变压缩算法,一意孤行整个暑假,却因“太简单”申不到经费》,DCT是最原始的图像压缩算法
全称为Discrete Cosine Transform,即离散余弦变换
刚好小编之前做过图像、视频处理相关的研发工作,对图像处理比较感兴趣,之前也看过利用聚类进行图片颜色压缩的内容,索性就再回顾一下,分享出来供大家参考学习
聚类算法本文不再赘述,不会的同学记住核心思想即可:人以类聚,物以群分
《三个印度人改变压缩算法,一意孤行整个暑假,却因“太简单”申不到经费》https://mp.weixin.qq.com/s/l3EPCNlE0Ne3wU5YFQ65dg
题外话,三角函数中余弦函数运用的比较多,在计算向量(文本、语音向量化)的相似度,这里的离散余弦变换
原始图片,4.47MB
本文演示的图片数据,均基于该张图片,故宫.jpg

颜色压缩效果
4032*3024 行=12192768 行,也就是1219万个像素点、1219万个颜色点 压缩为10个颜色点、128个颜色点

图片数据介绍
大家都知道一个像素可以表示为R(红色 Red)、G(绿色 Green)、B(蓝色 Blue)三个数值组成,照片是一个颜色矩阵,可以理解为每行由指定的像素点排成一行组成,这样由很多行就组合成了一个图片,千万别被高级名词:三维矩阵吓到
我们可以对该图片颜色矩阵进行变换,转换为我们熟悉的二维矩阵,RGB每个颜色是一个特征列,这个矩阵一共有4032*3024 行=12192768 行,也就是1219万个像素点、1219万个颜色点
先放第一行的点,再放第二行的点,以此类推,然后每个点展开为3列,这个就是numpy里面矩阵变换时数据的变化规则
变换后结果如下图所示:
转换为二维矩阵后,是不是和平时分析的数据样式就一样了,这样就可以用来进行聚类,特征列只有3个,分别为R、G、B
确定运用的颜色个数(聚类中簇的个数)
一共有 4032*3024 行=12192768 行 数据,我们要聚为几类呢?我们可以先大概取一些值,比如聚为2类、3类、5类 等等,然后使用肘部法则,来大概确定一个合适的分类数(簇数)
利用SSE指标,结合肘部法则,可以确定聚为10类时,比较合适
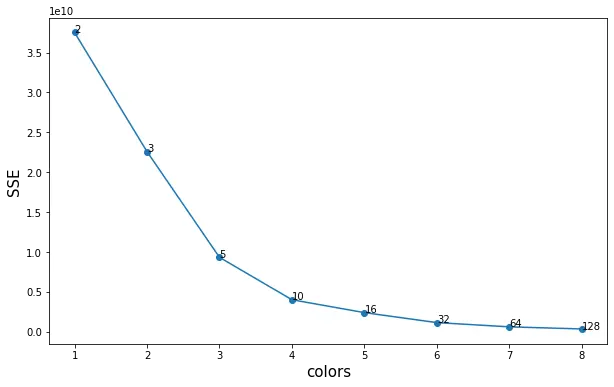
然后用这10类的中心点坐标颜色来还原图片,相当于用10种颜色来对图片进行上色,可以看到图片基本与原图一直,除了天空有锯齿外,图片其他的地方完美显示,这时图片大小为 997KB

极端情况,聚类为2种颜色
由于原图里面蓝色较多,聚为2类时,除了有蓝色,还有暗棕色

脑洞大开,用黑白色表示
由于上面可以用2种颜色来表示,于是脑洞大开,可以用黑色与白色来试试,效果如下图所示,有点类似手绘风格的图片

完整代码
from skimage import io
# from sklearn.cluster import KMeans
from sklearn.cluster import MiniBatchKMeans #提升聚类速度
import numpy as np
import sklearn.metrics as sm
import matplotlib.pyplot as plt
np.set_printoptions(threshold=np.inf)
image = io.imread('故宫.jpg')
io.imshow(image)
data=image/255.0
data=data.reshape(-1,3)
SSE = []
silhouette_score = []
k = []
#簇的数量
colors=[2,3,5,10,16,32,64,128]
for n_clusters in colors:
cls = MiniBatchKMeans(n_clusters,batch_size=2048).fit(data)
score1 = cls.inertia_
SSE.append(score1)
#肘部法则,确定聚类个数
fig, ax1 = plt.subplots(figsize=(10, 6))
ax1.scatter(range(1,9), SSE)
ax1.plot(range(1,9), SSE)
ax1.set_xlabel("colors",fontdict={'fontsize':15})
ax1.set_ylabel("SSE",fontdict={'fontsize':15})
ax1.set_xticks(range(1,9))
for i in range(8):
plt.text(i+1, SSE[i],colors[i])
plt.show()
#运用10个聚类色表示图片
colors_use=10
km = MiniBatchKMeans(colors_use,batch_size=2048)
km.fit(data)
new_data = km.cluster_centers_[km.predict(data)] #利用np.array 的整数索引(高级索引知识),用聚类中心点值 代替原来点的值
image_new = new_data.reshape(image.shape)
image_new_convert = np.array(np.round(image_new * 255),dtype='uint8')
io.imsave('colors_use_10.jpg',image_new_convert)
#黑白色表示
kmeans = MiniBatchKMeans(2)
kmeans.fit(data)
new_data =np.array([[255,255,255],[0,0,0]])[kmeans.predict(data)]
image_new = new_data.reshape(image.shape)
image_new_convert = np.array(np.round(image_new * 255),dtype='uint8')
io.imsave('黑白色.jpg',image_new_convert)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
又到一年一度的国庆节了,把自己的微信头像更换为国庆的头像,喜庆过大节。
这个是去年做的,分享出来供大家参考,已上传github,仓库地址:https://github.com/DataShare-duo/WeChat_ProfilePhoto_GuoQing
代码
"""
===========================
@Time : 2022/9/30 13:24
@File : 国庆头像.py
@Software: PyCharm
@Platform: Win10
@Author : DataShare
===========================
"""
from PIL import Image
guoqi = Image.open('国旗.jpg')
touxiang = Image.open('自己头像.jpg')
# 获取国旗的尺寸
x,y = guoqi.size
# 根据需求,设置左上角坐标和右下角坐标(截取的是正方形)
quyu = guoqi.crop((60,20, x-40-280,y))
# 获取头像的尺寸
w,h = touxiang.size
# 将区域尺寸重置为头像的尺寸
quyu = quyu.resize((w,h))
# 透明渐变设置
for i in range(w):
for j in range(h):
color = quyu.getpixel((i, j))
alpha = 255-i*2//5
if alpha < 0:
alpha=0
color = color[:-1] + (alpha, )
quyu.putpixel((i, j), color)
touxiang.paste(quyu,(0,0),quyu)
touxiang.save('自己头像-国庆.png')
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在日常业务办理过程中,不知大家是否养成了为重要文件添加水印的习惯?特别是通过微信等社交平台传输的证件照片、合同扫描件等敏感资料,建议都应当添加包含个人/企业信息的水印,这样既能保护隐私又能防止资料被滥用
小编这里分享的小工具,是在本地进行操作,不用把照片上传到其他系统中,更好的保护了个人隐私
小编环境
import sys
print('python 版本:',sys.version)
#python 版本: 3.11.11 | packaged by Anaconda, Inc. |
#(main, Dec 11 2024, 16:34:19) [MSC v.1929 64 bit (AMD64)]
import PIL
print('PIL 版本:',PIL.__version__)
#PIL 版本: 10.0.1
效果预览


拉取代码
git clone git@github.com:DataShare-duo/watermarker.git
安装需要的库
这个小工具需要使用第三方库 Pillow,需要进行安装
pip install Pillow
使用方法
这个小工具既可以给单个图片加上水印,也可以给文件夹里面的所有图片加上水印
- 单个图片添加水印
python .\marker.py -f .\input\蓝天白云.jpg -m 天气晴朗,适合出游
- 文件夹批量添加水印
python .\marker.py -f .\input -m 天气晴朗,适合出游
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
手绘效果

利用到的数学知识
手绘效果的几个特征:
- 黑白灰色-----------图像灰度转化
- 边界线条较重-----------梯度
- 相同或相近色彩趋于白色-----------梯度调整、梯度缩放
- 略有光源效果-----------投影、三角函数
-
黑白灰色-----------图像灰度转化 图像是由红(Red)、绿(Green)、蓝(Blue)三原色来表示真彩色,R分量,G分量,B分量的取值范围均为0~255,正常读取的图片构成的三维矩阵就是图像各像素点的RGB值。 图像的灰度化,就是让像素点矩阵中的每一个像素点都满足这样的关系:R=G=B,此时的这个值叫做灰度值:
灰度化后的R = 处理前的R * 0.299+ 处理前的G * 0.587 +处理前的B * 0.114
灰度化后的G = 处理前的R * 0.299+ 处理前的G * 0.587 +处理前的B * 0.114
灰度化后的B = 处理前的R * 0.299+ 处理前的G * 0.587 +处理前的B * 0.114
PIL库里面在灰度转化时,利用的公式
When translating a color image to greyscale (mode "L"), the library uses the ITU-R 601-2 luma transform:
L = R * 299/1000 + G * 587/1000 + B * 114/1000
-
边界线条较重-----------梯度
梯度、导数、偏导数、斜度、斜率、神经网络梯度,均为同一个概念
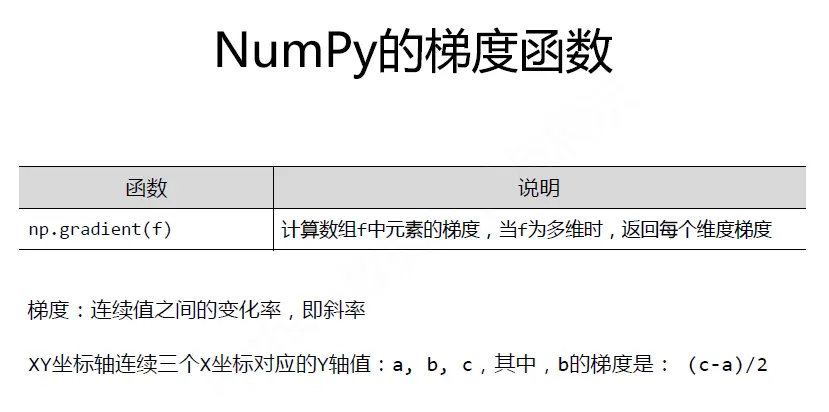


-
相同或相近色彩趋于白色-----------梯度调整、梯度缩放
grad= grad*alpha
alpha取[0,1]之间的值,这样使相近颜色的值,梯度缩放到更小,即可认为颜色是差不多一样的,手绘时是白色
-
略有光源效果-----------投影、三角函数
类似之前分享文章(利用Python计算两个地理位置之间的中点)介绍的经纬度投影
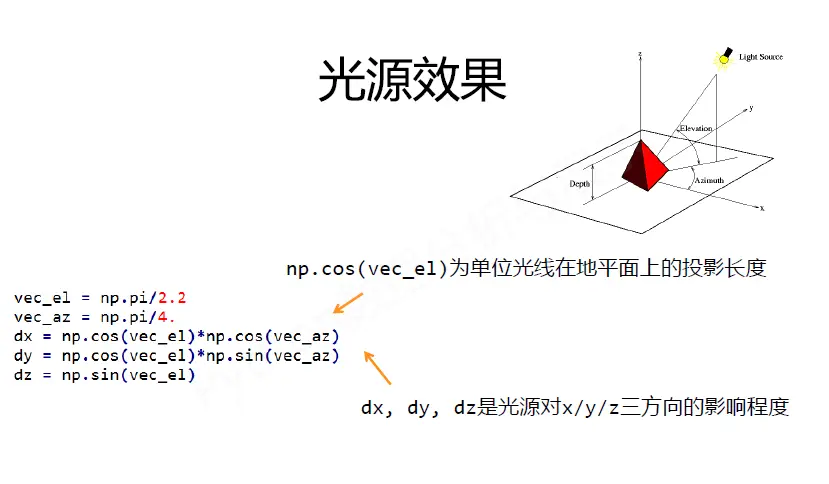
完整代码
可左右滑动查看代码
from PIL import Image
import numpy as np
import os
def img_handpainted(input_img_path):
img = np.array(Image.open(input_img_path).convert('L')).astype('float') #转化为灰度图
img_name=os.path.basename(input_img_path)[:-4] #获取图片名字
depth = 20. # (0-100),可以理解为图像的深淡程度
grad = np.gradient(img) #取图像灰度的梯度值
grad_x, grad_y = grad #分别取横纵图像梯度值
grad_x = grad_x*depth/100.
grad_y = grad_y*depth/100.
A = np.sqrt(grad_x**2 + grad_y**2 + 1.) #构造x和y轴梯度的三维归一化单位坐标系
uni_x = grad_x/A
uni_y = grad_y/A
uni_z = 1./A
vec_el = np.pi/2.2 # 光源的俯视角度,弧度值
vec_az = np.pi/4. # 光源的方位角度,弧度值
dx = np.cos(vec_el)*np.cos(vec_az) #光源对x 轴的影响
dy = np.cos(vec_el)*np.sin(vec_az) #光源对y 轴的影响
dz = np.sin(vec_el) #光源对z 轴的影响
b = 255*(dx*uni_x + dy*uni_y + dz*uni_z) #梯度与光源相互作用,将梯度转化为灰度
b = b.clip(0,255) #为避免数据越界,将生成的灰度值裁剪至0‐255区间
img_handpainted = Image.fromarray(b.astype('uint8')) #重构图像
outname='./'+img_name+'_handpainted.jpg'
img_handpainted.save(outname)
img_handpainted('./love.jpg')
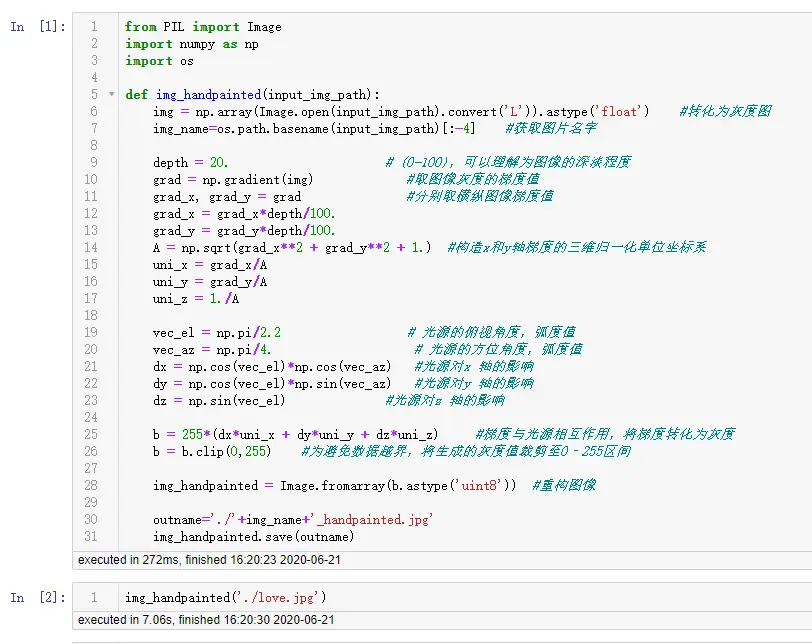
手绘效果
历史相关文章
作者:数据人阿多
背景
二维码,早已融入我们的日常!扫一扫加好友、支付买单、参加活动……处处可见它的身影。
但你是否想过,自己也能轻松生成专属二维码?无论是分享链接、联系方式,还是传递一句悄悄话,一个专属二维码就能搞定!
想知道如何实现?本文为你准备了详细案例教程,手把手教你玩转二维码生成!👇
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
安装qrcode
pip install "qrcode[pil]"
Demo1
生成普通的二维码图片
"""
===========================
@Time : 2025/7/15 18:40
@File : generate_qr
@Software: PyCharm
@Platform: Win10
@Author : 数据人阿多
===========================
"""
import qrcode
data = input("请输入要生成二维码的内容:")
# 创建二维码配置对象
# version=3:二维码尺寸版本 (1-40),版本3对应 29x29 模块(自动适配时可省略)
# box_size=8:每个二维码小方块占8像素
# border=4:二维码边缘留白宽度(4个小方块宽度的白色边框)
qr = qrcode.QRCode(version=3, box_size=8, border=4)
# 添加数据
qr.add_data(data)
# 生成数据矩阵
# fit=True:自动选择最小可用版本尺寸
# 若数据过长会自动升级 version 值(覆盖初始设置的version=3)
qr.make(fit=True)
# 渲染图像
# 支持颜色名称/十六进制值
image1 = qr.make_image(fill='Black', back_color='GreenYellow')
image2 = qr.make_image(fill='Black', back_color='#CE8540')
# 保存输出
# 支持其他格式(如 JPG/BMP 需指定后缀)
image1.save('qr_code1.png')
image2.save('qr_code2.jpg')


Demo2
可以把喜欢的图片设置为二维码背景
"""
===========================
@Time : 2025/7/15 18:40
@File : generate_qr_image
@Software: PyCharm
@Platform: Win10
@Author : 数据人阿多
===========================
"""
import qrcode
from PIL import Image, ImageFilter, ImageOps
def create_custom_bg_qrcode(data, bg_path, output_path="qr_code.png",
qr_color=(0, 0, 0), overlay_opacity=0.05):
"""
创建带自定义背景的二维码
参数:
data: 二维码数据
bg_path: 背景图片路径
output_path: 输出文件路径
qr_color: 二维码颜色 (R,G,B)
overlay_opacity: 二维码层不透明度 (0-1)
"""
# 生成基础二维码
qr = qrcode.QRCode(version=5,
box_size=10,
border=4,
error_correction=qrcode.constants.ERROR_CORRECT_H)
qr.add_data(data)
qr.make(fit=True)
qr_img = qr.make_image(fill_color="black", back_color="white").convert("RGB")
# 创建二维码遮罩
mask = qr_img.convert("L").point(lambda x: 255 if x < 128 else 0)
mask = mask.filter(ImageFilter.GaussianBlur(1))
# 处理背景图片
bg = Image.open(bg_path)
bg = ImageOps.fit(bg, qr_img.size,
method=Image.LANCZOS,
bleed=0.0,
centering=(0.5, 0.5)
)
# 创建纯色层用于增强对比度
overlay = Image.new("RGB", qr_img.size, (250, 250, 250)) # 浅灰色背景
colored_qr = Image.new("RGB", qr_img.size, qr_color)
# 合成图像
bg = Image.blend(bg, overlay, 0.15) # 降低背景复杂度
composite = Image.composite(colored_qr, bg, mask)
# 添加原始二维码层以增强识别点
final = Image.blend(composite, colored_qr, overlay_opacity)
# 保存结果
final.save(output_path)
return output_path
# 使用示例
data = input("请输入要编码的内容:")
bg_path = '背景.jpg'
output = create_custom_bg_qrcode(data, bg_path,output_path='qr_code3.png')
print(f"已生成带背景二维码: {output}")

历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多 日期:2026年4月30日
背景
在现代数字内容创作与分发的流程中,为图片添加水印已成为保护版权、防止盗用的重要工序,然而,市面上许多水印工具依赖于在线服务,存在隐私泄露的风险;而专业图像处理软件则显得过于笨重,不够轻便
因此,开发一款本地化、轻量级、零网络依赖的图片水印工具,不仅能够满足日常使用需求,更是一次探索 Python 桌面应用开发实践的绝佳机会
效果
整体架构与技术选型
Photo Water Marker 的整体技术栈包含三大核心模块:
- GUI 客户端:采用 Python 标准库
tkinter,零依赖,高度可移植 - 图像处理内核:采用 Python 生态中久经考验的
Pillow(PIL 的友好分支)库 - 分发与交付:采用工业级打包工具
PyInstaller,将 Python 脚本与运行时环境一同打包为 Windows 下的独立.exe可执行文件
图像处理逻辑深度解析
本项目的图像处理代码完全基于 Pillow 库实现,历经多次迭代,最终形成了一个高效且灵活的处理管线。整个水印应用的核心处理逻辑位于 apply_watermark 方法中,可高度归纳为以下六个步骤:
- 载入 RGBA 原图:直接调用
self.original_image.copy()获取一份独立的 RGBA 图像副本,为后续的非破坏性编辑奠定基础 - 构建透明文字水印层:利用
Image.new创建一个与原图尺寸完全一致的RGBA透明图层,以避免直接修改原图 - 解析并应用水印样式:根据从 GUI 获取的颜色、透明度、字体大小与旋转角度等参数,动态构建一个仅包含单个水印文字块的临时透明图层
- 执行几何旋转:对该文字块临时图层执行
rotate( )操作,并设置expand=True以保证旋转后文本块的完整可见 - 满屏平铺与合成:使用双层循环将旋转后的文字块平铺到第 2 步创建的透明水印层上,最终通过
Image.alpha_composite( )将其与原图无缝融合 - 输出最终结果:将融合图像返回,供预览和最终保存
在工程实践中,将几何变换(旋转)置于水印块生成阶段,而非合成后的全图处理,是保证图像边缘无黑边、支持透明背景的关键技巧
GUI 界面搭建与优化
Photo Water Marker 的 GUI 界面严格遵循简洁高效的开发标准,整体分为三大板块:原图旋转、控制面板、实时预览
- 原图旋转功能:采用清晰的
Radiobutton组件,直接在界面中实现了0°、90°、180°、270°四个角度的硬件级旋转 - 控制区:使用
grid网格布局管理器,确保透明度、水印旋转、字体大小等控件严格对齐 - 原始预览区:清晰呈现原图状态,便于与水印效果进行直观对比
- 水印预览区:实时展示水印添加后的成品效果
在开发过程中,我们解决了一个 Tkinter 界面布局抖动 的典型痛点:
通过将预览组件从 Label 替换为 Canvas 画布,并采用 propagate(False) 固定外框尺寸,结合 <Configure> 事件绑定实现图片的等比缩放,彻底杜绝了因内容更新导致的界面抖动现象
PyInstaller 高兼容性打包
得益于 Python 脚本语言的特性,本项目开发完成后并未止步于源码形态。为了能让非 Python 用户也能享受到即刻使用的便利,我们通过 PyInstaller 将项目编译为了独立的 Windows 可执行文件 .exe
核心打包指令为:
pyinstaller -F -w photo_water_marker_gui.py
其中 -F 指定单文件模式,-w 指定 Windows GUI 模式(隐藏控制台窗口),确保最终交付的 exe 程序干净、整洁、无任何外部依赖。用户只需下载,双击即可运行
项目总结
Photo Water Marker 作为一个致力于解决日常高频、小型、隐私敏感需求的开源项目,完成了一次标准的 Python 桌面应用开发、优化与交付全流程实践
本项目不仅展示了 Python 作为“胶水语言”在桌面开发领域的深厚潜力,也再次证明了使用 Python 生态的核心组件足以快速搭建出可靠且优美的实用程序。从图像处理逻辑的精细打磨,到 GUI 交互体验的反复优化,整个开发过程充满了探索与创造的乐趣
项目主页:https://github.com/DataShare-duo/photo_water_marker
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
声明:
本篇文章仅用来技术分享,如有侵权请及时联系本小编,微信公众号:DataShare,进行删除
背景
一个用了十年的电影、电视剧网址:飘花电影网,https://www.piaohua.com,关键是一直免费,从大学时代到工作了几年后,仍一直在用的网站,里面的电影、电视剧一直实时更新,各大平台的VIP内容均可免费观看。

最开始是支持迅雷下载,后来迅雷会屏蔽下载链接,现在是网站自己开发一个 荐片播放器 可以直接用来边下载边观看,很是方便
荐片播放器下载地址:https://www.jianpian8.com
分析抓包内容
第一集:ftp://a.gbl.114s.com:20320/1531/人世间第1集.mp4
第二集:ftp://a.gbl.114s.com:20320/0999/人世间第2集.mp4
第三集:ftp://a.gbl.114s.com:20320/8950/人世间第3集.mp4
通过上面每一集的地址,可以发现 a.gbl.114s.com 这个服务器地址很牛逼,存放了这么多免费的电影、电视剧,于是通过国外一个搜索引擎找到了一个开放的API,可以查看播放地址
API地址:https://api2.rinhome.com/api/node/detail?id=556881

可以明确《人世间的》的 id 是 556881,于是脑洞大开,想从id=1开始到100万,采集一个完整的明细,包含电影、电视剧
完整代码
import asyncio
import aiohttp
import random
import json
import time
urls=[(id,f'https://api2.rinhome.com/api/node/detail?id={id}') for id in range(1,1000000)]
# User-Agent
def randomheader():
UA = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1',
'Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6',
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5',
'Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3',
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3',
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3',
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
]
headers = {'user-agent': random.choice(UA)}
headers[
'accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
headers['accept-encoding'] = 'gzip, deflate, br'
headers['accept-language'] = 'zh-CN,zh;q=0.9'
headers['cache-control'] = 'max-age=0'
headers['sec-ch-ua'] = '" Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"'
headers['sec-ch-ua-mobile'] = '?0'
headers['sec-ch-ua-platform'] = '"Windows"'
headers['sec-fetch-dest'] = 'document'
headers['sec-fetch-mode'] = 'navigate'
headers['upgrade-insecure-requests'] = '1'
headers['sec-fetch-site'] = 'none'
headers['sec-fetch-user'] = '?1'
return headers
async def async_get_url(id,url,sem):
async with sem:
async with aiohttp.ClientSession() as session:
#print(randomheader())
async with session.get(url,headers=randomheader()) as r:
print('正在采集:', url)
html = await r.text()
try:
text_json = json.loads(html)
if text_json['msg'] == '请求成功':
with open(f'./success-async/{id}.json', 'w', encoding='utf-8') as fp:
json.dump(text_json, fp, ensure_ascii=False, indent=4)
else:
with open(f'./fail-async/{id}.json', 'w', encoding='utf-8') as fp:
json.dump(text_json, fp, ensure_ascii=False, indent=4)
except:
with open(f'./fail-async/{id}.json', 'w', encoding='utf-8') as fp:
fp.write(html)
if __name__=='__main__':
start=time.time()
sem = asyncio.Semaphore(300) #协程并发任务量
tasks = [async_get_url(id, url, sem) for id, url in urls]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print(f'cost time: {time.time() - start}s')
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
从小编真实接触股票已经有10年之久了,因为大学的专业就是数据与应用数据(金融学方向),大三、大四学期时学习了很多涉及金融相关的课程,特别是在大四时,老师还专门给每位同学开通了模拟炒股的账户,让全班同学一起模拟炒股,但小编用真金白银炒股的时间大概是2018年,居现在也有5年时间,一直是韭菜中
最近大家也看到了曾任《环球时报》总编辑的胡锡进,也开始入市炒股,并且每天都会发博文,分享当天的炒股感受
于是小编就试着获取股票的数据来研究一下,经过查找与对比,小编决定用akshare这个库,因为该库一直有更新,并且文档是中文,而且比较详细,
akshare文档地址:https://www.akshare.xyz/
股票各种数据获取方法
导入akshare库
import akshare as ak
import pandas as pd
1、股票的基本信息数据
ak.stock_individual_info_em(symbol="000651")
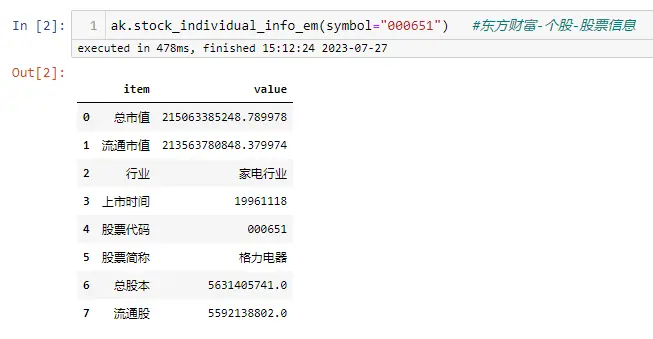
2、实时数据,当日的成交数据
单次返回所有沪深京 A 股上市公司的实时行情数据
ak.stock_zh_a_spot_em()
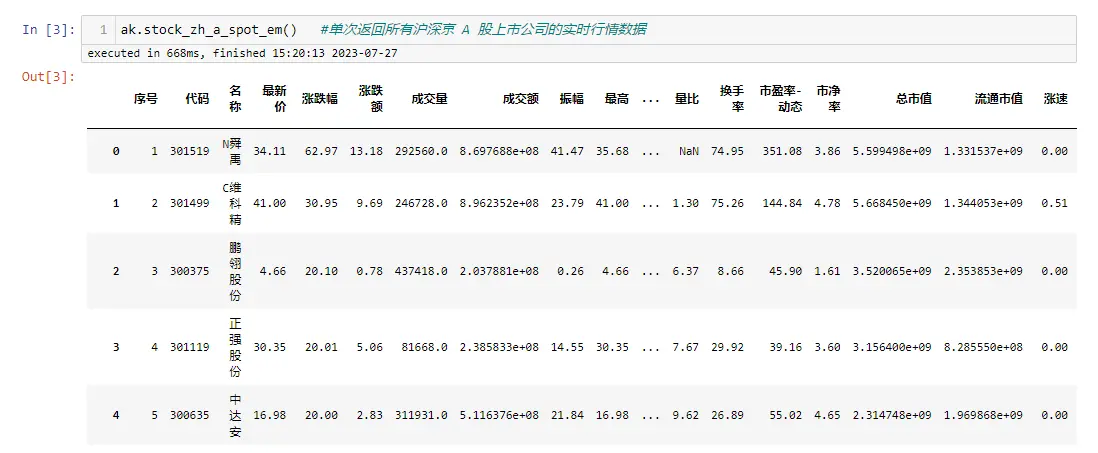
3、历史数据,历史的成交数据
ak.stock_zh_a_hist(symbol="000651",
period="daily",
start_date="20230701",
end_date='20230725',
adjust="" #不复权
)
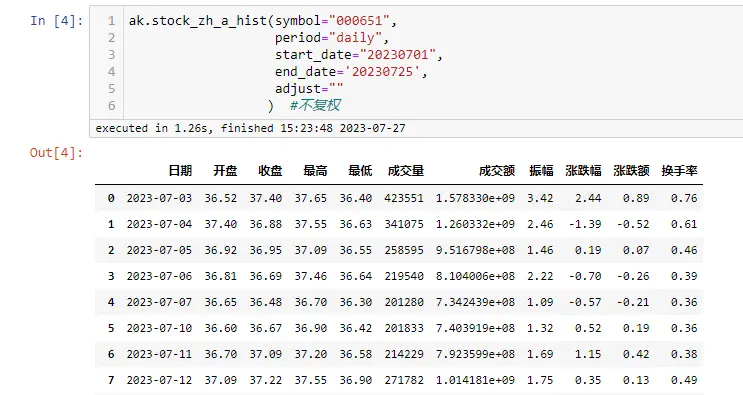
4、资金流向数据 限量: 单次获取指定市场和股票的近 100 个交易日的资金流数据
ak.stock_individual_fund_flow(stock="000651", market="sz")
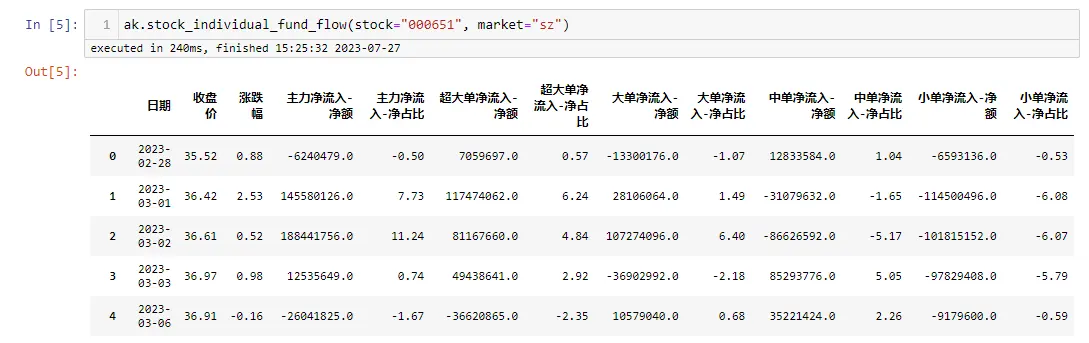
5、行情报价,买卖各5档
ak.stock_bid_ask_em(symbol="000651")
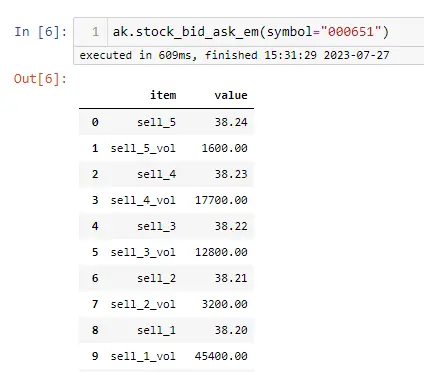
每日特定股票数据汇总案例
下面展示每日获取特定股票数据,可以做成定时任务,在15:00闭市后获取
"""
===========================
@Time : 2023/7/26 20:13
@File : stock_day
@Software: PyCharm
@Platform: Win10
@Author : DataShare
===========================
"""
import akshare as ak
import pandas as pd
import datetime
import sys
def stock_to_excel(stock_code, stock_name):
if stock_code[0] == '6':
market = 'sh'
elif stock_code[0] == '0':
market = 'sz'
df1 = ak.stock_zh_a_spot_em()
df2 = df1[df1['代码'] == stock_code]
dt = str(datetime.date.today()) #当日
df3 = ak.stock_individual_fund_flow(stock=stock_code, market=market) #在15:00之后获取
df4 = df3[df3['日期'] == dt]
result = {
"日期": dt,
"股票代码": stock_code,
"股票名称": stock_name,
"前一日收盘价": df2['昨收'].to_list()[0],
"开盘": df2['今开'].to_list()[0],
"收盘": df2['最新价'].to_list()[0],
"最高": df2['最高'].to_list()[0],
"最低": df2['最低'].to_list()[0],
"成交量": df2['成交量'].to_list()[0],
"成交额": df2['成交额'].to_list()[0],
"振幅": df2['振幅'].to_list()[0],
"涨跌幅": df2['涨跌幅'].to_list()[0],
"涨跌额": df2['涨跌额'].to_list()[0],
"换手率": df2['换手率'].to_list()[0],
"量比": df2['量比'].to_list()[0],
"市盈率-动态": df2['市盈率-动态'].to_list()[0],
"市净率": df2['市净率'].to_list()[0],
"60日涨跌幅": df2['60日涨跌幅'].to_list()[0],
"主力净流入-净额": df4['主力净流入-净额'].to_list()[0],
"主力净流入-净占比": df4['主力净流入-净占比'].to_list()[0],
"超大单净流入-净额": df4['超大单净流入-净额'].to_list()[0],
"超大单净流入-净占比": df4['超大单净流入-净占比'].to_list()[0],
"大单净流入-净额": df4['大单净流入-净额'].to_list()[0],
"大单净流入-净占比": df4['大单净流入-净占比'].to_list()[0],
"中单净流入-净额": df4['中单净流入-净额'].to_list()[0],
"中单净流入-净占比": df4['中单净流入-净占比'].to_list()[0],
"小单净流入-净额": df4['小单净流入-净额'].to_list()[0],
"小单净流入-净占比": df4['小单净流入-净占比'].to_list()[0]
}
return result
if __name__ == '__main__':
stocks_code = {'000651': '格力电器',
'002241': '歌尔股份',
'002739': '万达电影',
'600956': '新天绿能',
'600031': '三一重工',
'600703': '三安光电',
'002027': '分众传媒',
'600030': '中信证券',
'002939': '长城证券',
} #小编买过的股票
dt = str(datetime.date.today())
results=[]
for stock_code, stock_name in stocks_code.items():
print(f'{stock_name}:{stock_code}')
try:
results.append(stock_to_excel(stock_code, stock_name))
except Exception as e:
print("运行中出错",e)
sys.exit(-1)
pd.DataFrame.from_dict(results).to_excel(f'./data/{dt}.xlsx', index=False)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
家里的电视,你还打开过吗? 像小编这样长期在外打拼的“北漂族”,电视似乎早已慢慢淡出了日常生活。但每次过节回家,和家人围坐在一起,看看电视直播,却成了一种难得的仪式感。
说起电视直播,就不得不提到小编偶然发现的一款神器——TVbox 这款软件确实强大,装到电视上就能免费观看海量电影、电视剧和各地直播频道,最关键的是:全程无广告、无广告、无广告!(重要的事情必须说三遍)
不过有一点挺让人头疼:别人分享的直播源,常因为网络运营商不同,在自己家可能根本无法播放…… 于是,就有了今天这篇文章的主题: 如何整合网络上分享的IPTV直播源,把它们变成适合自己家庭网络环境的稳定直播源
小编环境
import sys
print('python 版本:',sys.version.split('|')[0])
#python 版本: 3.11.11
github仓库地址
https://github.com/DataShare-duo/MovieLiveUrl
仓库使用教程
仓库更新迭代时间有点长,里面有各种测试文件比较乱,真实用的文件如下:
- 直播.xlsx 配置文件,收集的不同直播源,以及抽取需要的频道直播源
- live_source.py 主程序,解析不同的直播源,测试是否可用,直播源速度
- parse_live_source.py 解析直播的主要逻辑类
- speed_test_async.py 测试直播源速度的函数,运用异步的逻辑
运行程序:
python live_source.py
生成直播源结果:
- movie_live.m3u
- movie_live.txt
生成的文件直播源一模一样,只是2种不同的文件类型,供不同的app使用
订阅地址:
-
https://raw.githubusercontent.com/DataShare-duo/MovieLiveUrl/refs/heads/main/movie_live.m3u
-
https://raw.githubusercontent.com/DataShare-duo/MovieLiveUrl/refs/heads/main/movie_live.txt
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
引言
之前分享的大部分内容都是一些技术、方法类文章,今天为大家带来一篇业务方面的文章——增长引擎说,希望大家能够喜欢。
自己始终坚信,技术的升级改造,最终还是服务于业务,如果离开了业务谈技术,那么这种技术最终会因没有用武之地,而被抛弃。所以,我们平时也不能一股脑,把时间全部用在技术上,要想成为一个真正的数据分析师、数据科学家,那么我们也要思考思考当今业务的一些难题。
说到业务,一个重大的难题就是增长,中国现在逐渐失去了人口红利,业务增长这个大难题,就显的更加突出。
《精益数据分析》这本书是自己去年买的,一直放到今年才来看,有点汗颜。。。。。,最近几周看了里面的一些章节,认为讲的很有道理,于是就借来分享一下,供大家参考。
驱动创业增长的三大引擎
- 黏着式增长引擎
- 病毒式增长引擎
- 付费式增长引擎
黏着式增长引擎

黏着式增长引擎的重点是让用户成为回头客,并且持续使用你的产品, 它和提高留存率这个概念类似。如果你的用户黏性不大,流失率会很高,用户参与度就不理想。用户参与度是预测产品成功的最佳指标之一,Facebook早期的用户数并不多(仅限哈佛大学),但它可以在上线数月,就让一个学校几乎全部的学生都变成自己的用户,并持续使用。Facebook的黏性是前所未有的。
衡量黏性最重要的 KPI 就是客户留存率。除此之外,流失率和使用频率也是非常重要的指标。
长期黏性往往来自用户在使用产品过程中为自身所创造的价值。人们很难放弃使用Gmail,因为那里存储了他们所有的资料。同样,让一个玩家在一款大型多人网络游戏中删号,也会是一件非常艰难的决定,因为他将失去在游戏中辛苦赢得的一切地位和虚拟物品。
衡量黏性也不能全看留存率,它还和频率有关,这解释了为什么你需要跟踪“距上次登陆的时间”(RFM模型)这样的指标。如果你使用了提高用户回访的方法,诸如邮件提醒和更新,那么邮件的打开率和点击率也同样需要关注。
病毒式增长引擎

所谓病毒式传播归根结底就是一件事情:让名声传播出去。 病毒式传播之所以吸引人,在于它的指数本质:如果每个用户能带来 1.5 个新用户,那么用户数将会无限制地增长直到饱和。(但事情绝不可能这么简单,用户流失、竞争对手和其他因素决定了它不可能真的无限制增长)
此引擎的关键指标是病毒式传播系数,即每个用户所带来的新用户数。 因为这是一个利滚利的模式(老用户所带来的新用户,同样也会带来更多的用户),这个指标所衡量的是每一个病毒传播周期的新用户量。增长在病毒式传播系数大于1时自发地到来,但你同时也需要考虑流失率对整体病毒因子的影响。病毒因子越大,增长也就越迅速。
仅考虑病毒式传播系数还不够,你还需要衡量哪些用户行为形成了一个病毒传播周期(循环)。例如,大部分社交网络都会在你注册时询问是否要同步你的邮箱通讯录,然后诱导你邀请通讯录里的联系人。这些联系人收到你发出的邀请邮件,可能会欣然接受。这些独立的行为连结在一起,决定着社交网络的病毒性。所以说,衡量这些行为能够让你知道如何将病毒式增长引擎开足马力:改变邀请信里的信息,简化注册流程,等等。
还有其他一些因素也与病毒性相关,包括用户完成一次邀请所需的时间(或叫病毒传播周期)以及病毒性的类别。
付费式增长引擎

第三种驱动增长的引擎是付费。通常,在确知产品具有黏着性和病毒性前就开动这一引擎,是过于仓促的行为。由 Meteor Entertainment 公司开发的《机甲世界》是一款免费多人游戏,但它靠游戏内的增值服务赚钱。这家公司首先专注于提高 beta 测试小组的使用量(黏着性),然后致力于游戏的病毒性(邀请朋友来玩),最后才是付费(玩家购买增值服务的目的是游戏中处于更有利的地位或提升游戏体验)。
从某种程度上讲,赚钱是识别一个商业模式是否可持续的终极指标。如果你从客户身上所赚的钱超过获取客户的花费,并且可以一直这样做下去,你就是可持续的。你不需要外部投资者的钱,并且每天都在增加股东的权益。
但是,就其本身而言,赚钱并不是一种驱动增长的引擎。它只是让银行里的钱越来越多。只有当你反过头来把一部分营收再用于获取客户时,营收才有助于你的增长,然后你就有了一个可调节的业务增长机器。
机器上的两个调节旋钮是客户终生价值(CLV)和客户获取成本(CAC)。 从客户身上赚到的钱比获取他们花掉的钱多自然是一件好事,但这并不简单地等同于成功。你仍需为现金流和增长速度发愁,这取决于多久才能让一个客户付清你获取他所花的成本。一种衡量方法是看客户盈亏平衡时间,也就是你收回获取一位客户的成本所需的时间。
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近在做业务分析,用到的方法大家可能都比较熟悉:漏斗分析,这个分析方法在很多业务场景都有应用到,是业务侧的常用的分析方法,除了此之外还有一些业务侧常用的分析方法,比如:5W2H、AAARR 等
但是,熟悉本公众号的读者,可能比较了解公众号分享的都是一些偏技术侧的知识,之前分享过一些算法模型,包括统计学、特征工程、决策树、人脸监测、NLP 等一些机器学习文章,既有传统的机器学习内容,也有深度学习的内容,这些都是偏向技术侧的分析方法
有的同学可能一直在自学机器学习,不知道怎么拿来用到真实的业务中,于是就是产生怎么把业务侧分析方法与技术侧的分析方法结合起来呢?
个人粗浅的理解
业务侧分析方法是一个大框架,技术侧分析方法属于细节分析
要想运用技术侧的分析方法,则需要把业务侧的需求进行拆分,逐步转化为数学问题,然后运用技术侧的方法,但是,业务侧的分析大框架是不能忽略的,必须要有的。就好比盖房子,业务侧分析方法是房子的大框架,技术侧分析方法是在大框架中填充砖头。
比如最近在做的分析,业务侧需要一些高意向客户,进行营销,运用的是漏斗分析的方法, 投放数量--->点击数量--->意向数量--->成交数量,是一个层层递进的漏斗,每两层之间有一个转化率,只有把每层的转化率都提高了,才能达到最终的目的,成交的客户数才能提升。
投放数量--->点击数量,会生成点击率指标,那怎么提升点击率呢?那就需要用ABtest这种统计学方法进行测试,看哪种宣传文案比较好,或者 运用各种机器学习模型,预测哪些用户有可能会点击,对这部分用户进行不同渠道的触达,来提升点击率
但是也有同学会问,不能直接使用机器学习模型筛选一批高意向用户,不用漏斗分析吗? 最开始也是这么实践的,但是效果一直不好,原因就是虽然投放了,但是用户根本没有收到,大概率是被屏蔽了。假如你用模型选了100个能成交的用户,但是最终成交只有60个,那么40个在中间的哪一步给卡掉了,你都不知道,所以漏斗分析这种大框架还是必须的,不能忽略。
数学模型比较直接,行就是行,不行就是不行,但是业务或商业实践中有很多环节,需要一步一步去达成,这也一直有的调侃,理科直男的说法。也有点像在神经网络模型中,有很多隐藏层,每层之间必须要有激活函数,否则即使有多层,合并后其实也就是一层。这个激活函数,在不同层之间起到连接作用,连接不同的层。
业务侧分析与技术侧分析相辅相成,一个是大框架,一个是细节分析
这里只是小编的一些思考,有可能是错误的,毕竟小编还资历尚浅,需要不断学习,如果有错误理解的地方,欢迎大佬不吝赐教,公众号后台消息,小编会及时关注。
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
大家都知道现在大数据非常火爆,在大数据还没有出现时,用的都是“小数据”,这些“小数据”在分析时大部分用的都是Excel、SPSS等工具,直到现在把Excel运用的很熟练的人,仍然很受青睐。但是Python的到来,使处理大数据比较方便。那么之前在Excel、SPSS中的描述统计、假设检验在Python中怎么使用呢?下面将进行详细介绍,前提是已经掌握numpy、pandas这两个库,并且对统计知识有所了解
加载数据
这里引用的是GitHub上的一个CSV数据文件,insurance.csv 保险数据 ,可以下载下来参考练习 网址:https://github.com/stedy/Machine-Learning-with-R-datasets
>>> import numpy as np
>>> import pandas as pd
>>> data=pd.read_csv('F:/Machine-Learning datasets/insurance.csv')
>>> data
age sex bmi children smoker region charges
0 19 female 27.900 0 yes southwest 16884.92400
1 18 male 33.770 1 no southeast 1725.55230
2 28 male 33.000 3 no southeast 4449.46200
3 33 male 22.705 0 no northwest 21984.47061
4 32 male 28.880 0 no northwest 3866.85520
... ... ... ... ... ... ... ...
1333 50 male 30.970 3 no northwest 10600.54830
1334 18 female 31.920 0 no northeast 2205.98080
1335 18 female 36.850 0 no southeast 1629.83350
1336 21 female 25.800 0 no southwest 2007.94500
1337 61 female 29.070 0 yes northwest 29141.36030
[1338 rows x 7 columns]
>>> data.isnull().sum()
age 0
sex 0
bmi 0
children 0
smoker 0
region 0
charges 0
dtype: int64
>>> data.dtypes
age int64
sex object
bmi float64
children int64
smoker object
region object
charges float64
dtype: object
描述统计各指标
>>> data['age'].max()
64
>>> data['age'].min()
18
>>> data['age'].mean()
39.20702541106129
>>> data['age'].std()
14.049960379216172
>>> data['age'].median()
39.0
众数有时会有多个,这里是全部返回
>>> data['age'].mode()
0 18
dtype: int64
>>> d=pd.DataFrame([1,1,1,2,2,2,3,4,4,4,5,5,6],columns=['a'])
>>> d['a'].mode()
0 1
1 2
2 4
dtype: int64
>>> data['age'].quantile([0,0.25,0.5,0.75,1])
0.00 18.0
0.25 27.0
0.50 39.0
0.75 51.0
1.00 64.0
Name: age, dtype: float64
>>> data['region'].value_counts()
southeast 364
northwest 325
southwest 325
northeast 324
Name: region, dtype: int64
>>> data['age'].max()-data['age'].min()
46
>>> data['age'].quantile(0.75)-data['age'].quantile(0.25)
24.0
>>> data['age'].std()/data['age'].mean()
0.3583531326824994
假设检验
>>> data
age sex bmi children smoker region charges
0 19 female 27.900 0 yes southwest 16884.92400
1 18 male 33.770 1 no southeast 1725.55230
2 28 male 33.000 3 no southeast 4449.46200
3 33 male 22.705 0 no northwest 21984.47061
4 32 male 28.880 0 no northwest 3866.85520
... ... ... ... ... ... ... ...
1333 50 male 30.970 3 no northwest 10600.54830
1334 18 female 31.920 0 no northeast 2205.98080
1335 18 female 36.850 0 no southeast 1629.83350
1336 21 female 25.800 0 no southwest 2007.94500
1337 61 female 29.070 0 yes northwest 29141.36030
[1338 rows x 7 columns]
>>> data['age'].mean()
39.20702541106129
>>>
>>> import statsmodels.api as sm #加载分析库
>>> t=sm.stats.DescrStatsW(data['age']) #构造统计量对象
>>> t.ttest_mean(38) #t检验,假设总体均值为38,返回t值、P值、自由度
(3.142457193279878, 0.0017121567548687802, 1337.0)
>>> t.ttest_mean(39) #假设总体均值为39,p>0.05,接受原假设
(0.5389849179805168, 0.5899869939488361, 1337.0)
>>> t.ttest_mean(18) #假设总体均值为18,p<0.05,小于0.05拒绝原假设
(55.21190269926711, 0.0, 1337.0)
>>> data.groupby('sex').mean()['charges']
sex
female 12569.578844
male 13956.751178
Name: charges, dtype: float64
>>> sex0=data[data['sex']=='female']['charges']
>>> sex1=data[data['sex']=='male']['charges']
>>> from scipy import stats
>>> leveneTestRes=stats.levene(sex0,sex1) #方差齐性检验
>>> leveneTestRes #p值<0.05,说明方差非齐性
LeveneResult(statistic=9.90925122305512, pvalue=0.0016808765833903443)
>>> stats.stats.ttest_ind(sex0,sex1,equal_var=False) #双样本T检验
Ttest_indResult(statistic=-2.1008878232359565, pvalue=0.035841014956016645)
相关系数
>>> data[['age','charges']].corr(method='pearson') #皮尔逊相关系数
age charges
age 1.000000 0.299008
charges 0.299008 1.000000
>>> data[['age','charges']].corr(method='spearman') #斯皮尔曼等级相关系数
age charges
age 1.000000 0.534392
charges 0.534392 1.000000
>>> data[['age','charges']].corr(method='kendall') #肯德尔相关系数
age charges
age 1.000000 0.475302
charges 0.475302 1.000000
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
由于最近项目的需要,学习了分类算法--决策树,从逐步了解决策树,然后到手动在Excel里面模拟计算相关算法,最后到对scikit-learn库的运用,算是从理论到实践走了一遍,也发现scikit-learn库并不是完全对理论的实现,只是将部分算法实现出来,现总结分享出来供大家参考。
决策树大概的样子
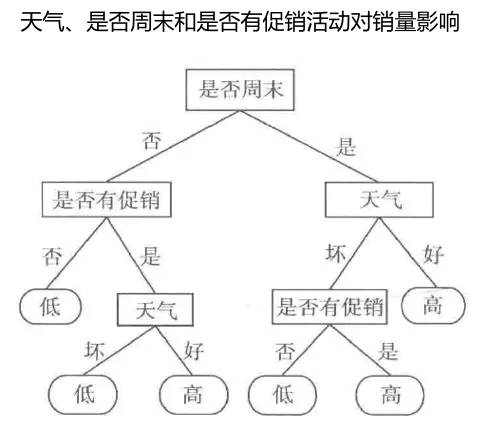
决策树三个算法介绍
如果说对决策树比较熟悉的话,发展到现在主要有三个决策树算法,ID3、C4.5、CART这三个算法,其中ID3是利用信息增益,C4.5利用信息增益率,CATR利用基尼系数,C4.5是对ID3缺点的一个改进,但改进后还是有缺点,现在目前运用较多的是基尼系数,也就是CART这个算法,scikit-learn库里面的决策树默认的就是运用基尼系数来进行分枝。

ID3--信息增益
信息增益也就是信息熵的差值,也就是通过一个节点分枝使信息熵减少了多少,信息熵是由香农提出的,相信大家都听说过这个大人物,那什么是信息熵呢,看了很多参考书,感觉解释的最通俗易懂的是吴军的《数学之美》里面对这个概念的阐述。

信息熵的主要公式:
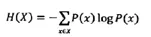 信息增益是在条件熵下计算而来,类似于条件概率的意思
信息增益是在条件熵下计算而来,类似于条件概率的意思
 ID3算法过程:
ID3算法过程:

C4.5--信息增益率
说白了就是相对于信息增益多了一个比值,由于信息增益更倾向于分类比较多的属性,这个大家可能比较懵,详细解释一下,比如说一个变量(一个特征)A,是个分类变量,它下面包含A1,A2,A3三个不同的属性(水平),而另外一个变量B下面包含B1,B2,B3,......,B10共10个不同的属性,那么计算出来的信息增益,根据历史经验来说,变量B信息增益比较大,一般首先选取B来作为节点进行分枝。 而C4.5就是克服这个缺点应运而生,就是再用计算出来的这个信息增益除以这个变量本来的信息熵
信息增益率主要公式:
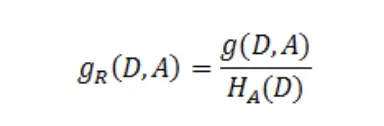
ID3与C4.5结合使用效果相对比较好

scikit-learn库对信息增益的实现大概框架
scikit-learn库里面的决策树,没有具体说是信息增益,还是信息增益率,这个有兴趣可以仔细研究一下https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
from sklearn import tree # 导入决策树库
# 训练分类模型
model_tree = tree.DecisionTreeClassifier(criterion='entropy',random_state=0)
# 建立决策树模型对象,需要指定criterion为entropy
model_tree.fit(X, y) #对数据进行训练
feature_importance = model_tree.feature_importances_ # 指标重要性
模型效果可视化需要用到其他的库及软件,这里不再详述,可参考其他内容,主要点就是中文的显示问题,中文是可以显示的,相关文档也有介绍,大家也可以仔细研究
CART (Classification And Regression Tree) 分类回归树

解释一下“纯”:在我的印象里这个字是形容女生的,怎么跑到这里来呢,呵呵,这里的纯是说,经过一个节点的分枝后,目标变量y里面都是一个类别的,就说是纯的,不纯,就是经过一个节点的分枝后,目标变量y里面还是比较乱,任然不能确定目标属于哪个类别
scikit-learn库对基尼系数的实现大概框架
from sklearn import tree # 导入决策树库
# 训练分类模型
model_tree = tree.DecisionTreeClassifier(criterion='gini',random_state=0)
# 建立决策树模型对象,需要指定criterion为gini,也可以不指定,默认的就是gini
model_tree.fit(X, y) #对数据进行训练
feature_importance = model_tree.feature_importances_ # 指标重要性
模型可视化中文显示问题
需要把里面的字体替换为微软雅黑即可
names_list=['中文1','中文2','中文3',...]
tree.export_graphviz(model_tree,out_file=dot_data,feature_names=names_list, filled=True,rounded=True,special_characters=True)
graph4 = graphviz.Source(dot_data.getvalue().replace('helvetica','"Microsoft YaHei"'))
graph4.render('决策树-5组均分-2变量') #生成PDF文件
参考
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
根据自己看的一些书籍及技术博客等内容,对机器学习算法进行一些总结,供大家参考
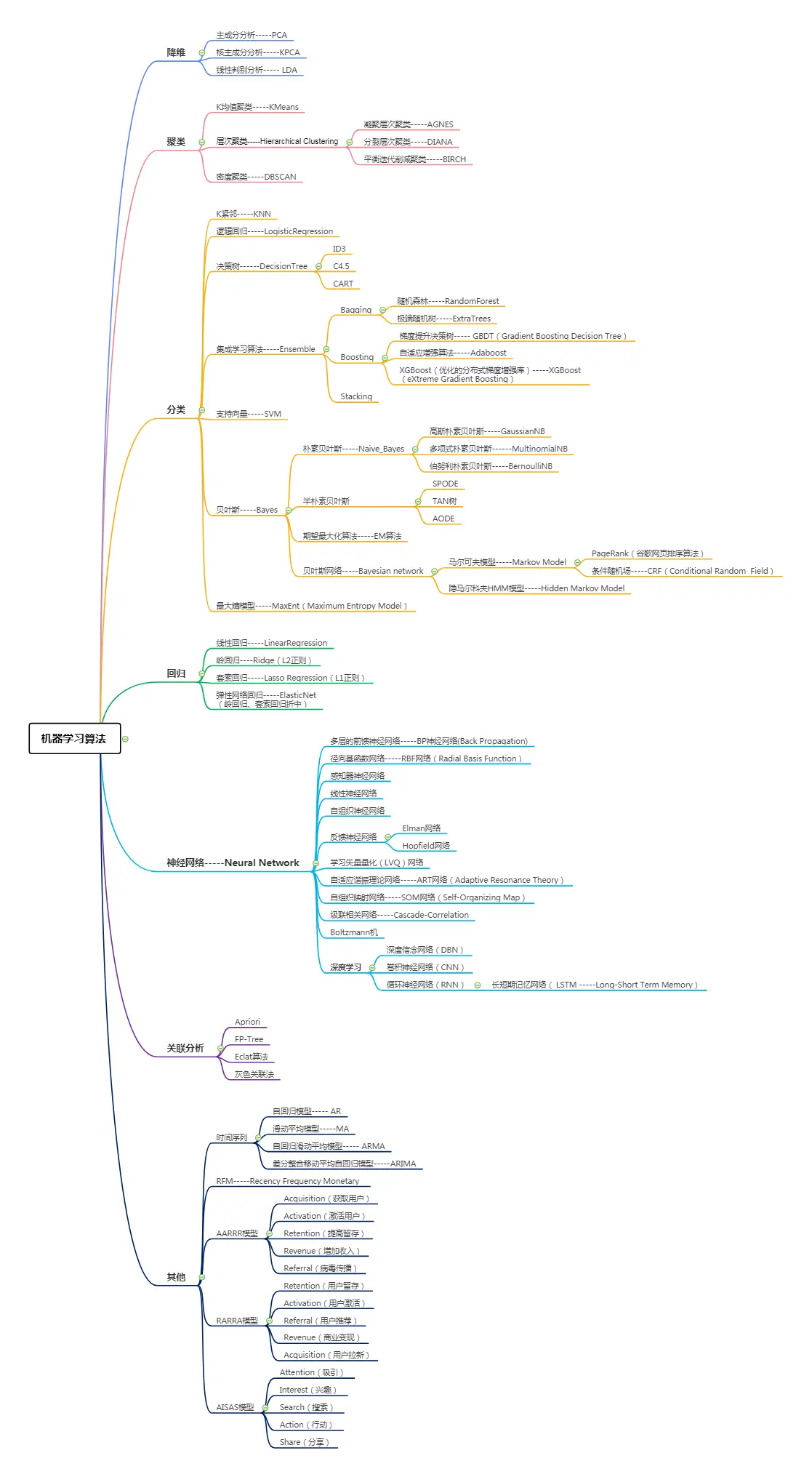
作者:数据人阿多
统计里面的卡方检验
卡方检验主要是用来进行 分类变量(离散变量) 的关联性、相关性分析,其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。
在统计学里面最经典就是四方格检验,下面列举一个例子,让大家对卡方检验有一个真实的认识: 现在我们有一些样本,每个人是否喝牛奶,以及是否感冒,形式如下(只截图了一部分),现在我们想知道,是否喝牛奶 对 是否感冒有影响,根据我们的常识判断,喝牛奶可以增强体质,有助于抵抗感冒,但一切结论都要有依据,才能使大家信服,于是这就用到统计学里面的卡方检验。
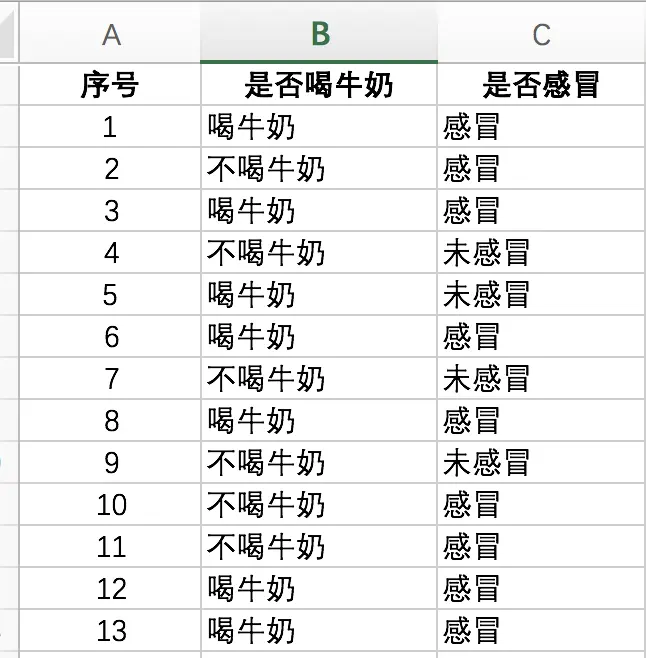
根据上面的数据,我们可以在Excel里面创建透视表,形成一个交叉表(列联表),统计交叉后的频数及占比情况,喝牛奶这一行的感冒率是用感冒的人数43除以喝牛奶总人数139,其他同理,如下所示:
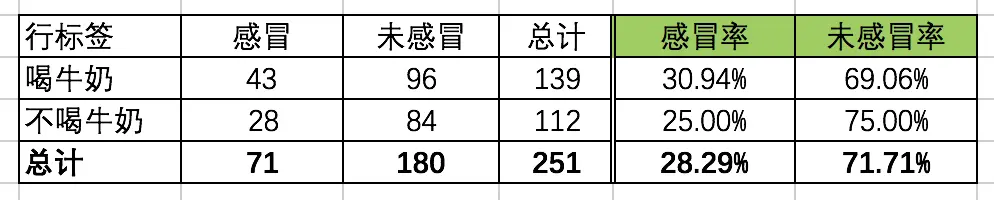
通过简单的统计我们得出喝牛奶和不喝牛奶的感冒率为30.94%和25.00%,两者的差别可能是抽样误差导致,也有可能是牛奶对感冒真的有影响。
先建立假设: H0(原假设):是否喝牛奶与是否感冒独立无关 H1(备择假设):是否喝牛奶与是否感冒是相关的,也就是喝牛奶会影响到感冒
为了确定真实原因,我们先假设喝牛奶对感冒是没有影响的,即喝牛奶和感冒是独立无关的,所以我们可以得出感冒的发病率实际是(43+28)/(43+28+96+84)= 28.29%
所以,理论上的数值如下表所示:
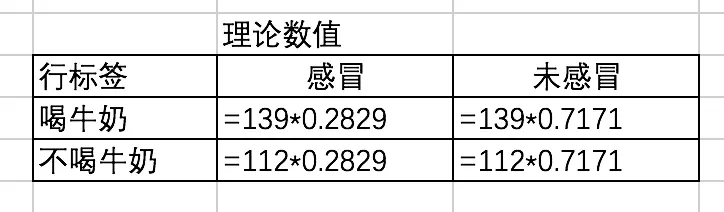
即下表数据:
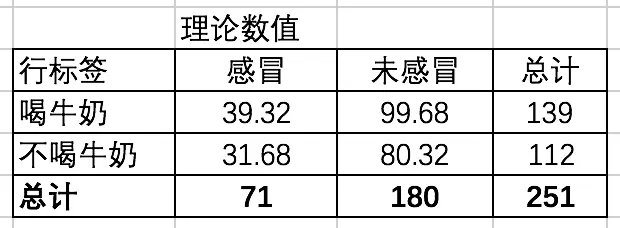 卡方检验的公式为:
卡方检验的公式为:

根据卡方检验公式我们可以得的卡方值为: 卡方 = (43 - 39.32)^2 / 39.32 + (28 - 31.68)^2 / 31.68 + (96 - 99.68)^2 / 99.68 + (84 - 80.32)^2 / 80.32 = 1.077
根据自由度和检验显著性水平0.05,通过查卡方表,可以得到对应的卡方值为3.84,即如果卡方大于3.84,则认为喝牛奶和感冒有95%的概率相关。显然1.077<3.84,没有达到卡方分布的临界值,原假设成立,即是否喝牛奶和是否感冒独立无关,其实通过公式也可以理解。
自由度等于= (行数 - 1) * (列数 - 1),对四格表,自由度= 1
通过上面的例子,大家应该对卡方检验有了深入理解,但是这个在机器学习sklearn库里面是怎么用的呢,以及用时我们应该怎么输入数据,上面例子我们是通过交叉表进行计算的,那么sklearn库又是怎么计算的呢?下面通过读官方的原始代码一步一步进行分析
官方原始代码
- github地址:https://github.com/scikit-learn/scikit-learn/blob/1495f6924/sklearn/feature_selection/univariate_selection.py#L172
- 官方chi2函数主要截图,def chi2(X, y),红框里面是主要的代码,其他基本都是很好理解,红框上面的是对输入的x进行类型检查:
下面一句一句对官方原始代码进行解析
Y = LabelBinarizer().fit_transform(y)
if Y.shape[1] == 1:
Y = np.append(1 - Y, Y, axis=1)
- 对输入的y进行二值化处理,也就是对y里面的类别进行数值处理,形成一列数值,用1和0进行表示不同的两个类别,LabelBinarizer()对超过两个类别也能处理,类似和one-hot编码
- 下面的if 是为了添加另一个类别,假如y里面只有两个类别的话,那么进行二值化处理后Y就只有1列,也就是只能表示y里面的一个类别,另外一个类别需要再添加上,新加的一列其实也就是对刚才二值化的数据取反
- 通过上面的理解,在输入y时可以是字符型,也可以是数值型,在机器学习里面大家印象一般都是用数值型数据,但是在这一块可以用字符型,像咱们的汉字等
observed = safe_sparse_dot(Y.T, X) # n_classes * n_features
- observed意思是观察值,也就是对应卡方里面的真实值,那么这行意思就是求真实值,只不过是用矩阵的乘法来处理
- 输入的X只能是数值型,这一块是用来进行矩阵乘法,那么也就是输入的分类变量必须处理成数值,需要用到one-hot,对每一个分类变量(离散变量)进行转换,这一块千万不能用 1 代表类别1, 2 代表类别2, 3 代表类别3 等,否则卡方检验就是错的,所选的特征同样也是错的,如果分类变量里面只有两个类别的话,可以直接用1,0
- Y.T 与 X两个矩阵的乘法,结果为y里面每个类别的计数
feature_count = X.sum(axis=0).reshape(1, -1)
class_prob = Y.mean(axis=0).reshape(1, -1)
expected = np.dot(class_prob.T, feature_count)
- 这三句代码是用来求理论数值,首先求出X矩阵每列求和,然后求出Y矩阵里面每个类别的占比(1的个数/总样本,其实也就是直接求平均,为理论占比),最后进行矩阵乘法,求出理论数值
return _chisquare(observed, expected)
- 用计算卡方的函数传入真实值、理论值,计算出卡方值
下面利用上面的原始代码演示一遍
 可以看出这个数值和上面Excel模拟的数值完全一样,最后通过卡方计算函数传入真实值、理论值即可求出 “卡方值”
可以看出这个数值和上面Excel模拟的数值完全一样,最后通过卡方计算函数传入真实值、理论值即可求出 “卡方值”
但是,但是,但是 求出来的卡方值,并不是统计上的卡方值、P值
在sklearn.feature_selection中,用到chi2时,在fit时需要传入X、y,计算出来的卡方值是 单个特征变量对目标变量y的卡方值,下面从大家经常使用api的角度去展示上面是否喝牛奶与是否感冒的特征筛选过程
sk.scores_
# array([0.59647887, 0.48061607])
sk.pvalues_
# array([0.43992466, 0.48814339])
可以看出计算出来两列值为0.59647887、0.48061607,这是X单个特征变量对目标变量y的卡方值,并不是上面Excel模拟计算的卡方值为1.077
而0.59647887+0.48061607=1.077,这个才是真正意义上的卡方检验的卡方值,那么对应的P值同样也不是统计意义上的P值
所以在sklearn.feature_selection.SelectKBest中基于卡方chi2,提取出来的比较好的特征变量,可以理解为在所有特征变量里面相对更好的特征,并不是统计里面分类变量与目标变量通过卡方检验得出的是否相关的结果,因此大家在进行特征筛选用到这个api时,要有真实的理解,感觉这点比较重要,分享出来供大家参考
以上是自己实践中遇到的一些点,分享出来供大家参考学习,欢迎关注本简书号
作者:数据人阿多
背景
在进行一些综合评估类项目时,需要给一些指标确定一个合理的权重,用来计算综合得分,这种综合评估类项目在实际的业务中有很多应用,比如:学生奖学金评定方法、广告效果综合评估、电视节目满意度综合评估、用户满意度综合评估等。计算权重的方法比较多,下面主要介绍利用熵值法来确定权重。
一些名词解释
- 个案 一个个案,一条记录,也就是一个样本,在矩阵里面就是一行数据,不同地方叫法不一样
- 属性 属性就是样本所拥有的特性,也就是特征,在矩阵里面就是一列数据
熵值法概念
熵值法原理: 熵的概念源于热力学,是对系统状态不确定性的一种度量。在信息论中,信息是系统有序程度的一种度量。而熵是系统无序程度的一种度量,两者绝对值相等,但符号相反。根据此性质,可以利用评价中各方案的固有信息,通过熵值法得到各个指标的信息熵,信息熵越小,信息的无序度越低,其信息的效用值越大,指标的权重越大。
熵是不确定性的度量,如果用 $P_{i}$ 表示第 $i$ 个信息的不确定度(也就是出现的概率),则整个信息(设有 $n$ 个)的不确定度量如下所示: $$S=-K\sum_{i=1}^{n}P_{i}lnP_{i}$$ 这就是熵,其中 $K$ 为正常数,当各个信息发生的概率相等时,即 $$P_{i}=\frac{1}{n}$$, $S$取值最大,此时熵最大,也就是信息无序度最大,各个信息都发生可能性一样
熵值法步骤
-
- 可利用信息熵的概念确定权重,假设多属性决策矩阵如下: $$M=\begin{matrix} A_{1} \ A_{2} \ \vdots \ A_{n} \end{matrix} \left[\begin{matrix} x_{11} & x_{12} & \cdots & x_{1m}\ x_{21} & x_{22} & \cdots & x_{2m}\ \vdots & \vdots & \ddots & \vdots \ x_{n1} & x_{n2} & \cdots & x_{nm} \end{matrix}\right] $$
则用 $$P_{ij}=\frac{x_{ij}}{\sum_{i=1}^{ n}x_{ij}}$$ 表示第$j$个属性下第$i$个方案$A_{i}$的贡献度
-
- 可以用$E_j$来表示所有方案对属性$X_j$的总贡献度:
$$E_j=-K\sum_{i=1}^{n}P_{ij}lnP_{ij}$$ 其中,常数$K=\frac{1}{ln(n)}$,这样,就能保证$0=<E_j<=1$,即$E_j$最大1。
由式中可以看出,当某个属性各个方案(样本)的贡献度趋于一致时,$E_j$趋于1。
- 可以用$E_j$来表示所有方案对属性$X_j$的总贡献度:
$$E_j=-K\sum_{i=1}^{n}P_{ij}lnP_{ij}$$ 其中,常数$K=\frac{1}{ln(n)}$,这样,就能保证$0=<E_j<=1$,即$E_j$最大1。
由式中可以看出,当某个属性各个方案(样本)的贡献度趋于一致时,$E_j$趋于1。
那么各个方案(样本)的贡献度全相等时,就应该不考虑该属性在决策中的作用,也就是该属性的权重应该为0
-
- 这样可以看出属性的权重系数大小由各方案差异大小来决定,为此可定义$d_j$为第$j$属性的各方案贡献度的一致性程度 $$d_j=1-E_j$$
-
- 进行归一化后,各属性权重如下: $$W_j=\frac{d_j}{\sum_{j=1}^{m}d_j}$$当$d_j=0$时,第$j$属性可以剔除,其权重等于0
-
- 如果决策者事先已有一些经验的主观估计权重$\lambda_j$,则可借助上述的$W_j$来对$\lambda_j$进行修正 $$W_{j}^{*}=\frac{\lambda_j W_j}{\sum_{j=1}^{m}\lambda_j W_j}$$
熵值法最大的特点是直接利用决策矩阵所给出的信息计算权重,而没有引入决策者的主观判断,完全是依靠数据来决定
案例
购买汽车的一个决策矩阵,给出了四个方案供我们进行选择,每个方案中均有相同的六个属性,我们需要利用熵值法求出各属性的权重
| 车型 | 油耗 | 功率 | 费用 | 安全性 | 维护性 | 操作性 |
|---|---|---|---|---|---|---|
| 本田 | 5 | 1.4 | 6 | 3 | 5 | 7 |
| 奥迪 | 9 | 2 | 30 | 7 | 5 | 9 |
| 桑塔纳 | 8 | 1.8 | 11 | 5 | 7 | 5 |
| 别克 | 12 | 2.5 | 18 | 7 | 5 | 5 |
计算步骤
-
- 求第$j$个属性下第$i$个方案$A_i$的贡献度,公式为: $$P_{ij}=\frac{x_{ij}}{\sum_{i=1}^{ n}x_{ij}}$$在excel中的话,先求出各列的和,然后用每行的数值比上列和,形成新的矩阵
| 车型 | 油耗 | 功率 | 费用 | 安全性 | 维护性 | 操作性 |
|---|---|---|---|---|---|---|
| 本田 | 5 | 1.4 | 6 | 3 | 5 | 7 |
| 奥迪 | 9 | 2 | 30 | 7 | 5 | 9 |
| 桑塔纳 | 8 | 1.8 | 11 | 5 | 7 | 5 |
| 别克 | 12 | 2.5 | 18 | 7 | 5 | 5 |
| 总计 | 34 | 7.7 | 65 | 22 | 22 | 26 |
$P$矩阵:
| 车型 | 油耗 | 功率 | 费用 | 安全性 | 维护性 | 操作性 |
|---|---|---|---|---|---|---|
| 本田 | 5/34 | 1.4/7.7 | 6/65 | 3/22 | 5/22 | 7/26 |
| 奥迪 | 9/34 | 2/7.7 | 30/65 | 7/22 | 5/22 | 9/26 |
| 桑塔纳 | 8/34 | 1.8/7.7 | 11/65 | 5/22 | 7/22 | 5/26 |
| 别克 | 12/34 | 2.5/7.7 | 18/65 | 7/22 | 5/22 | 5/26 |
-
- 求出所有方案对属性$X_j$的贡献总量,公式为:
$$E_j=-K\sum_{i=1}^{n}P_{ij}lnP_{ij}$$
在excel操作中,将刚才生成的矩阵每个元素变成每个元素与该元素自然对数的乘积
- 求出所有方案对属性$X_j$的贡献总量,公式为:
$$E_j=-K\sum_{i=1}^{n}P_{ij}lnP_{ij}$$
在excel操作中,将刚才生成的矩阵每个元素变成每个元素与该元素自然对数的乘积
只列出油耗计算过程,其他属性同理
| 车型 | 油耗 |
|---|---|
| 本田 | 5/34 * ln(5/34) |
| 奥迪 | 9/34 * ln(9/34) |
| 桑塔纳 | 8/34 * ln(8/34) |
| 别克 | 12/34 * ln(12/34) |
| 总计 | 5/34* ln(5/34) + 9/34* ln(9/34) + 8/34* ln(8/34) + 12/34* ln(12/34) |
求出常数$k$,$k$为$1/ln(方案数)$,本例中有4个方案,所以求得$k$为$1/ln(4)$,再求$k$与新矩阵每一列和的乘积,这样获得的 6 个积为所有方案对属性$x_j$的贡献度
| 车型 | 油耗 |
|---|---|
| 本田 | 5/34 * ln(5/34) |
| 奥迪 | 9/34 * ln(9/34) |
| 桑塔纳 | 8/34 * ln(8/34) |
| 别克 | 12/34 * ln(12/34) |
| 总计 | 5/34* ln(5/34) + 9/34* ln(9/34) + 8/34* ln(8/34) + 12/34* ln(12/34) |
| $E_j$ | 1/ln(4) * [ 5/34* ln(5/34) + 9/34* ln(9/34) + 8/34* ln(8/34) + 12/34* ln(12/34) ] |
至此所有的$E_j$就求出来了
-
- $d_j$为第$j$属性下各方案贡献度的一致性程度,公式为:
$$d_j=1-E_j$$利用上面求得的$E_j$,可以得到$d_j$
| 车型 | 油耗 |
|---|---|
| 本田 | 5/34 * ln(5/34) |
| 奥迪 | 9/34 * ln(9/34) |
| 桑塔纳 | 8/34 * ln(8/34) |
| 别克 | 12/34 * ln(12/34) |
| 总计 | 5/34* ln(5/34) + 9/34* ln(9/34) + 8/34* ln(8/34) + 12/34* ln(12/34) |
| $E_j$ | 1/ln(4) * [ 5/34* ln(5/34) + 9/34* ln(9/34) + 8/34* ln(8/34) + 12/34* ln(12/34) ] |
| $d_j$ | 1 - 1/ln(4) * [5/34* ln(5/34) + 9/34* ln(9/34) + 8/34* ln(8/34) + 12/34* ln(12/34) ] |
-
- 利用下面公式进行归一化后,即可求得各属性的权重: $$W_j=\frac{d_j}{\sum_{j=1}^{m}d_j}$$
经过计算后各属性的权重为:
| 车型 | 油耗 | 功率 | 费用 | 安全性 | 维护性 | 操作性 |
|---|---|---|---|---|---|---|
| 权重 | 0.14 | 0.07 | 0.49 | 0.16 | 0.04 | 0.10 |
所以在购买汽车时,据所提供信息,利用熵值法计算得出的权重为油耗占 14%,功率占 7%,费用占 49%,安全性占 16%,维护性占 4%,操作性占 10%。故我们在进行购买决策时,更多是考虑车型的价格和安全性等重要因素,这是从权重角度考虑的。
利用Python实现熵值法:
代码如下:
import pandas as pd
import numpy as np
import math
from numpy import array
# 定义熵值法函数 熵值法计算变量的权重
def cal_weight(df):
#求k
rows = df.index.size # 行
cols = df.columns.size # 列
k = 1.0 / math.log(rows)
# 矩阵计算、信息熵
x = array(df)
lnf = [[None] * cols for i in range(rows)]
lnf = array(lnf)
for i in range(0, rows):
for j in range(0, cols):
if x[i][j] == 0:
lnfij = 0.0
else:
p = x[i][j] / np.sum(x, axis=0)[j]
lnfij = math.log(p) * p * (-k)
lnf[i][j] = lnfij
lnf = pd.DataFrame(lnf)
E = lnf
# 计算一致性程度
d = 1 - E.sum(axis=0)
# 计算各指标的权重
w = [[None] * 1 for i in range(cols)]
for j in range(0, cols):
wj = d[j] / sum(d)
w[j] = wj
w = pd.DataFrame(w)
w.index = df.columns
w.columns = ['权重']
return w
以上是自己实践中遇到的一些点,分享出来供大家参考学习,欢迎关注本简书号
作者:数据人阿多
背景
在数据分析中总会碰见 阈(yu)值 这个问题,有人可能就是拍脑袋,根据自己的经验随便确定一个值,而且效果还不错。但既然是在分析数据,那就要确定一个合适的值来作为阈值,这样比较有说服力,更 make sense。
工作中要确定阈值的场景有很多:
案例1: 声纹相似度
人的声纹信息可以说是自己的另一个身份ID,可以根据声纹信息确定是否是同一个人,比如:微信app登陆时让用户读一个6位数,验证是否是该用户的声音,那微信是怎么来确定这个声音就是你呢?这里简化一下问题,假如微信服务器存的是根据你的声音提取出来的一个特征向量,那就是从你这次读的语音提取的特征向量与微信服务器存的特征向量的相似度问题,由于每次说话的音调不同,两个向量可能不完全相同,所以两个向量达到80%相似,还是90%相似,还是99%相似,微信让你登录呢,这里的相似度就是一个阈值。
案例2: NLP训练语句长度
在进行NLP模型训练时,提供的语料里面的每句话长度均不一样,那么在训练时应该怎么选取这个长度呢?如果用最大的长度,那么内存可能会暴增,如果用的语句长度太短,那么可能会遗漏一部分有用的信息,所以这里的句子长度就是一个阈值。
数据分布直方图
可以先利用数据分布直方图来确定数据的一个大概分布情况,
-
如果数据是服从标准正态分布,那么阈值可以定义为 x ± 3sigma 或者 x ± 6sigma;
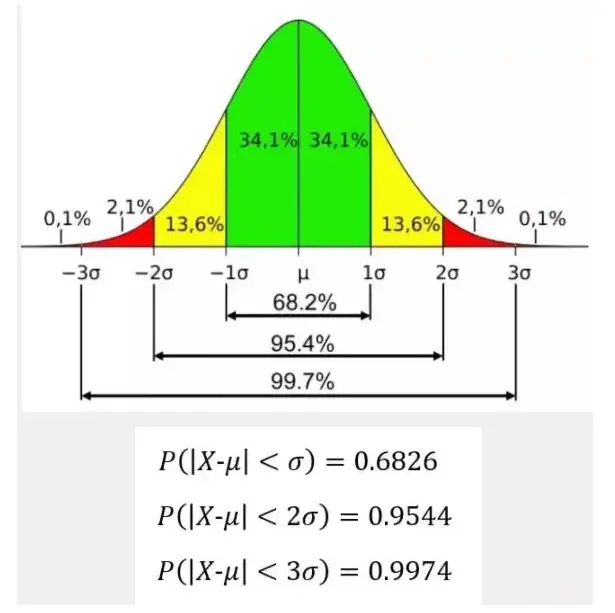
-
如果数据是一个偏分布,那么可以取一个分位数值90%或者95%,这个要视具体情况而定
下面列举一个偏分布的情况:
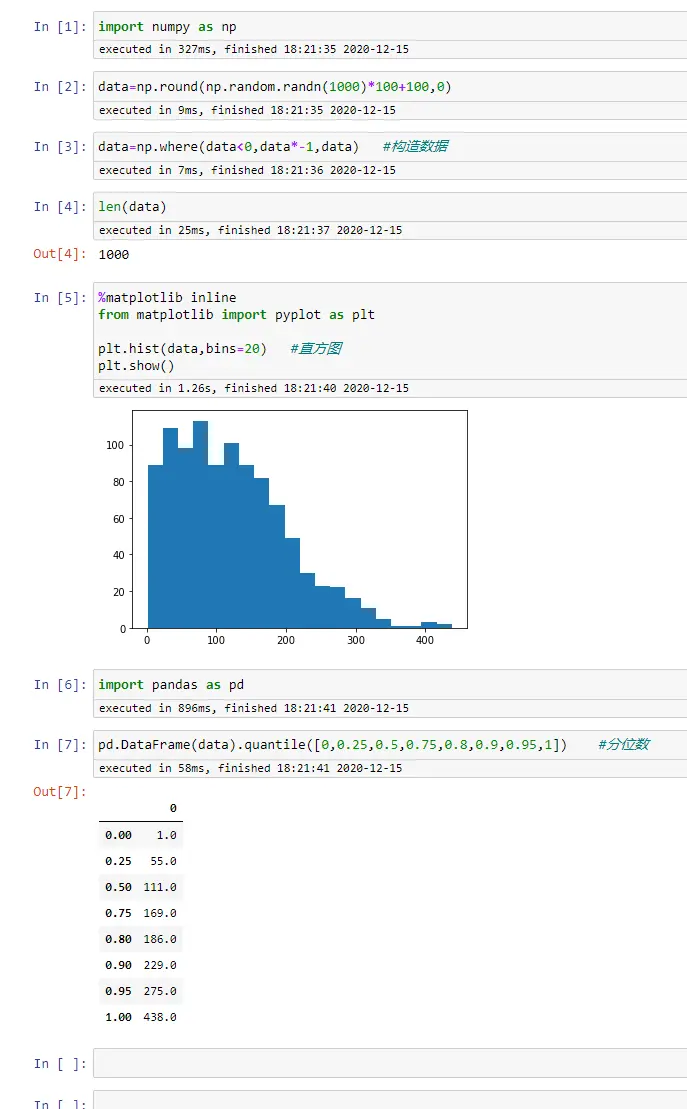
import numpy as np
data=np.round(np.random.randn(1000)*100+100,0)
data=np.where(data<0,data*-1,data) #构造数据
len(data)
%matplotlib inline
from matplotlib import pyplot as plt
plt.hist(data,bins=20) #直方图
plt.show()
import pandas as pd
pd.DataFrame(data).quantile([0,0.25,0.5,0.75,0.8,0.9,0.95,1]) #分位数
上面的模拟数据是一个偏分布情况,那么可以用一个分位数来确定,如果阈值取300,那么就可以包括最少95%的情况,如果想要更精确一些,那么阈值可以取400等更大的一个值
以上是在项目中的一个小分析
往期相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
“人以类聚,物以群分”,在大千世界中总有那么一些人,性格爱好、行为习惯比较相近,我们就会把他们归为一类人,这就是我们人脑自动进行的一个聚类(归类)。 在数据分析中,我们也经常拿数据来进行K-Means聚类,用来进行一些分析,K-Means聚类可能大家都会,但是如何科学的决策聚类簇数,这一直是聚类的一大难题。今天就来分享一下,自己工作中在确定聚类簇数时要到的方法。
方法
可以确定聚类簇数的方法
- Adjusted Rand index 调整兰德系数
- Mutual Information based scores 互信息
- Homogeneity, completeness and V-measure 同质性、完整性、两者的调和平均
- Silhouette Coefficient 轮廓系数
- Calinski-Harabaz Index
- SSE 簇里误差平方和
自己使用的方法,手肘法则SSE 和 轮廓系数 相结合
- SSE 簇里误差平方和
SSE利用计算误方差和,来实现对不同K值的选取后,每个K值对应簇内的点到中心点的距离误差平方和,理论上SSE的值越小,代表聚类效果越好,通过数据测试,SSE的值会逐渐趋向一个最小值。
- Silhouette Coefficient 轮廓系数
好的聚类:内密外疏,同一个聚类内部的样本要足够密集,不同聚类之间样本要足够疏远。
轮廓系数计算规则:
针对样本空间中的一个特定样本,计算它与所在簇中其它样本的平均距离a,以及该样本与距离最近的另一个聚类中所有样本的平均距离b,该样本的轮廓系数为
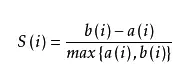
详细分解
对于其中的一个点 i 来说:
计算 a(i) = average(i向量到所有它属于的簇中其它点的距离)
计算 b(i) = min (i向量到各个非本身所在簇的所有点的平均距离)
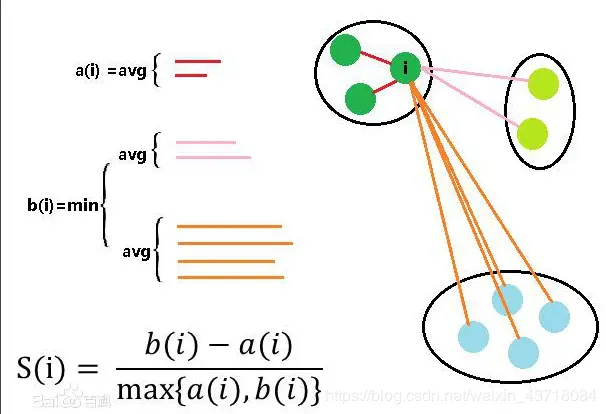
然后将整个样本空间中所有样本的轮廓系数取算数平均值,作为聚类划分的性能指标轮廓系数
轮廓系数的区间为:[-1, 1]。 -1代表分类效果差,1代表分类效果好。0代表聚类重叠,没有很好的划分聚类
应用、代码
以鸢尾花数据集为案例
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import sklearn.metrics as sm
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
#中文乱码的处理 显示负号
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False
# 载入鸢尾花数据集
iris = datasets.load_iris()
data=pd.DataFrame(iris['data'],columns=iris['feature_names'])
std = StandardScaler()
data_std=std.fit_transform(data)
SSE = []
k_SSE = []
#簇的数量
for n_clusters in range(1,11):
cls = KMeans(n_clusters).fit(data_std)
score = cls.inertia_
SSE.append(score)
k_SSE.append(n_clusters)
silhouette_score = []
k_sil = []
#簇的数量
for n_clusters in range(2,11):
cls = KMeans(n_clusters).fit(data_std)
pred_y=cls.labels_
#轮廓系数
score =sm.silhouette_score(data_std, pred_y)
silhouette_score.append(score)
k_sil.append(n_clusters)
fig, ax1 = plt.subplots(figsize=(10, 6))
ax1.scatter(k_SSE, SSE)
ax1.plot(k_SSE, SSE)
ax1.set_xlabel("k",fontdict={'fontsize':15})
ax1.set_ylabel("SSE",fontdict={'fontsize':15})
ax1.set_xticks(range(11))
for x,y in zip(k_SSE,SSE):
plt.text(x, y,x)
ax2 = ax1.twinx()
ax2.scatter(k, silhouette_score,marker='^',c='red')
ax2.plot(k, silhouette_score,c='red')
ax2.set_ylabel("silhouette_score",fontdict={'fontsize':15},)
for x,y in zip(k_sil,silhouette_score):
plt.text(x, y,x)
plt.show()
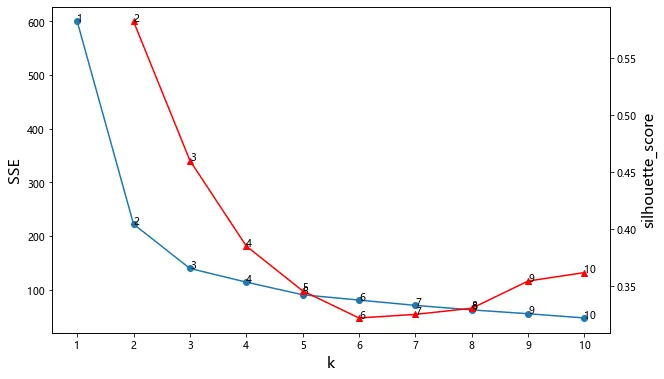 结合SSE与轮廓系数,当k=3时比较适合,可以确定聚类的簇数为3
结合SSE与轮廓系数,当k=3时比较适合,可以确定聚类的簇数为3
而鸢尾花数据集里面真实的分类就是3类
iris['target_names']
#array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号,不定期分享干货
作者:数据人阿多
背景
在对文本进行处理分析时,大家第一印象就是对句子进行分词,统计词频,看哪些词语出现的词频较高,重点关注这些高频词即可,文章可能就是围绕着这些词展开的。中文的分词工具,大家耳熟能详的可能就是结巴分词,但是结巴分词最近也没有怎么更新,随着技术的不断迭代有一些更优秀的分词工具诞生,比如:LAC(百度)、THULAC(清华大学)、LTP(哈工大)、FoolNLTK等
这里主要介绍一下百度的LAC,现在已更新到v2.1,GitHub地址:https://github.com/baidu/lac,使用起来速度与效果还可以,足以应对简单的分词任务
LAC介绍
LAC全称 Lexical Analysis of Chinese,是百度自然语言处理部研发的一款联合的词法分析工具,实现中文分词、词性标注、专名识别等功能。该工具具有以下特点与优势:
- 效果好:通过深度学习模型联合学习分词、词性标注、专名识别任务,词语重要性,整体效果F1值超过0.91,词性标注F1值超过0.94,专名识别F1值超过0.85,效果业内领先。
- 效率高:精简模型参数,结合Paddle预测库的性能优化,CPU单线程性能达800QPS,效率业内领先。
- 可定制:实现简单可控的干预机制,精准匹配用户词典对模型进行干预。词典支持长片段形式,使得干预更为精准。
- 调用便捷:支持一键安装,同时提供了Python、Java和C++调用接口与调用示例,实现快速调用和集成。
- 支持移动端: 定制超轻量级模型,体积仅为2M,主流千元手机单线程性能达200QPS,满足大多数移动端应用的需求,同等体积量级效果业内领先。
功能看着很强大,但是这里只用到中文分词功能,下面介绍一下使用的demo,
通过 pip install lac 进行安装即可
使用教程
直接使用lac分词
加载LAC 后,通过其自带的模型进行分词,结果为一个列表
from LAC import LAC
# 装载分词模型
lac = LAC(mode='seg')
text='我是一名北漂的打工人、干饭人'
lac.run(text)
text_list=['我是一名北漂的打工人、干饭人','5月15日,航天科研人员在北京航天飞行控制中心指挥大厅庆祝我国首次火星探测任务着陆火星成功']
lac.run(text_list)
加载自定义字典
从上面可以看出“打工人”可以正确分词,但是“干饭人”不能正确的切分,可以通过加载自定义字典来进行处理这种情况
from LAC import LAC
#装载分词模型
lac = LAC(mode='seg')
#加载自定义字典
lac.load_customization('自定义字典.txt', sep=None)
text='我是一名北漂的打工人、干饭人'
lac.run(text)
text_list=['我是一名北漂的打工人、干饭人',
'5月15日,航天科研人员在北京航天飞行控制中心指挥大厅庆祝我国首次火星探测任务着陆火星成功']
lac.run(text_list)
从上面的输出结果可以看出,已经正确分词
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
小编是在2019年开始学习机器学习,在查找资料时知道的OpenAI公司,当时该公司才成立没多久(创建于2018年),他的一些技术让小编感觉很厉害,便对他有了深刻印象。这短短过去4年时间,该公司便使人工智能又上了一个台阶,让大家都称赞不绝
GPT发展历程
官方的模型介绍文档:
从文档可以看出,开放的api是GPT-3,所以在调动api时,使用的模型是GPT-3,但是OpenAI官网的聊天,使用的是GPT-3.5,所以同样的问题,回答可能会不一样,
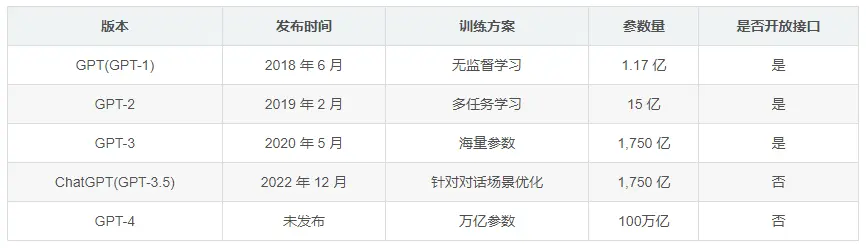
GPT-3(Generative Pre-trained Transformer 3,简称GPT-3)指的是生成型预训练变换模型第3版,是一个自回归语言模型,目的是为了使用深度学习生成人类可以理解的自然语言
GPT-3.5 与GPT-3 最大的差别在于GPT-3 主要扮演一个搜集资料的角色,较单纯的使用网路上的资料进行训练。而GPT-3.5 则是由GPT-3 微调出来的版本,而其中GPT-3.5 使用与GPT-3 不同的训练方式,所产生出来不同的模型,比起GPT-3 来的更强大
最近特别火的ChatGPT就是是建立GPT-3.5 之上,且更加上使用更完整的 人类反馈强化学习(RLHF)去训练。(大致上可以想成GPT-3 → GPT-3.5 → ChatGPT这样)
也因此ChatGPT 除了能够准确理解问题,更能够将对话一路记住和按此调整内容,其中包括承认错误、纠正错处和拒绝不当要求等等较为复杂的互动内容,更符合道德要求的训练方式,达到更接近真人的效果,这也是GPT-3 所没有的。
注册要点
因为官方限制了在中国地区使用,并且必须得用国外手机号验证,难点就是得有一个国外的手机号,可以使用接码平台,懂的话可以试试注册一个玩一下,如果对翻墙、机场、接码平台不了解的话,小编不建议大家折腾半天来注册一个官方账号
现在国内有一些网站、微信群基于api接口,开发出来供大家尝鲜使用,但基于的是不是OpenAI的api接口,这个有待验证(国内的开发大家都知道,喜欢骗人,要么是广告,要么调用就不是真正的OpenAI接口),所以大家在试玩的时候,得注意安全
基于官方网页版试玩
基于apikey试玩
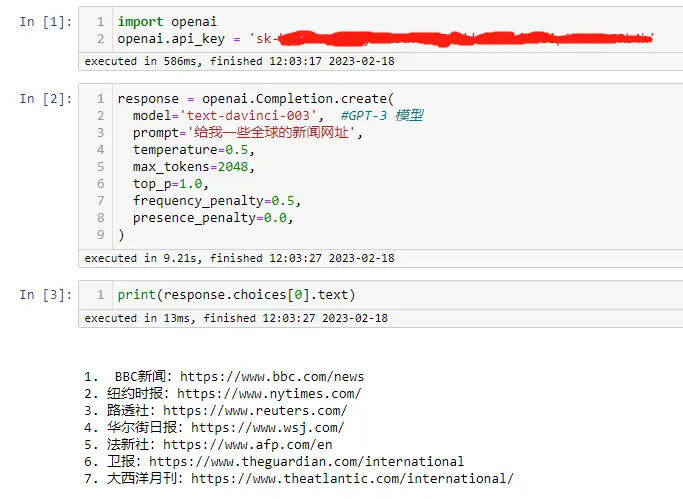
import openai
openai.api_key = 'sk-xxxx' #注册的api key
response = openai.Completion.create(
model='text-davinci-003', #GPT-3 模型
prompt='给我一些全球的新闻网址',
temperature=0.5,
max_tokens=2048,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.0,
)
print(response.choices[0].text)
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景介绍
自然语言处理(NLP)在深度学习领域是一大分支(其他:CV、语音),经过这些年的发展NLP发展已经很成熟,同时在工业界也慢慢开始普及,谷歌开放的Bert是NLP前进的又一里程碑。本篇文章结合Bert与Lstm,对文本数据进行二分类的研究。
需要的第三方库
- pandas
- numpy
- torch
- transformers
- sklearn
以上这些库需要读者对机器学习、深度学习有一定了解
数据及预训练Bert
- 预训练好的Bert(BERT-wwm, Chinese 中文维基)
https://github.com/ymcui/Chinese-BERT-wwm - 语料
https://github.com/duo66/Data_for_ML-Deeplearning/blob/master/dianping.csv
完整过程
- 数据预处理
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import TensorDataset, DataLoader
np.random.seed(2020)
torch.manual_seed(2020)
USE_CUDA = torch.cuda.is_available()
if USE_CUDA:
torch.cuda.manual_seed(2020)
data=pd.read_csv('./dianping.csv',encoding='utf-8')
#剔除标点符号,\xa0 空格
def pretreatment(comments):
result_comments=[]
punctuation='。,?!:%&~()、;“”&|,.?!:%&~();""'
for comment in comments:
comment= ''.join([c for c in comment if c not in punctuation])
comment= ''.join(comment.split()) #\xa0
result_comments.append(comment)
return result_comments
result_comments=pretreatment(list(data['comment'].values))
len(result_comments)
2000
result_comments[:1]
['口味不知道是我口高了还是这家真不怎么样我感觉口味确实很一般很一般上菜相当快我敢说菜都是提前做好的几乎都不热菜品酸汤肥牛干辣干辣的还有一股泡椒味着实受不了环境室内整体装修确实不错但是大厅人多太乱服务一般吧说不上好但是也不差价格一般大众价格都能接受人太多了排队很厉害以后不排队也许还会来比如早去路过排队就不值了票据六日没票告我周一到周五可能有票相当不正规在这一点同等价位远不如外婆家']
- 利用transformers 先进行分字编码
from transformers import BertTokenizer,BertModel
tokenizer = BertTokenizer.from_pretrained("./chinese-bert_chinese_wwm_pytorch/data")
result_comments_id=tokenizer(result_comments,padding=True,truncation=True,max_length=200,return_tensors='pt')
result_comments_id
{'input_ids': tensor([[ 101, 1366, 1456, ..., 0, 0, 0], [ 101, 5831, 1501, ..., 0, 0, 0], [ 101, 6432, 4696, ..., 0, 0, 0], ..., [ 101, 7566, 4408, ..., 0, 0, 0], [ 101, 2207, 6444, ..., 0, 0, 0], [ 101, 2523, 679, ..., 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0], [1, 1, 1, ..., 0, 0, 0], [1, 1, 1, ..., 0, 0, 0], ..., [1, 1, 1, ..., 0, 0, 0], [1, 1, 1, ..., 0, 0, 0], [1, 1, 1, ..., 0, 0, 0]])}
result_comments_id['input_ids'].shape
torch.Size([2000, 200])
- 分割数据集
from sklearn.model_selection import train_test_split
X=result_comments_id['input_ids']
y=torch.from_numpy(data['sentiment'].values).float()
X_train,X_test, y_train, y_test =train_test_split(X,y,test_size=0.3,shuffle=True,stratify=y,random_state=2020)
len(X_train),len(X_test)
(1400, 600)
X_valid,X_test,y_valid,y_test=train_test_split(X_test,y_test,test_size=0.5,shuffle=True,stratify=y_test,random_state=2020)
len(X_valid),len(X_test)
(300, 300)
X_train.shape
torch.Size([1400, 200])
y_train.shape
torch.Size([1400])
y_train[:1]
tensor([1.])
- 数据生成器
# create Tensor datasets
train_data = TensorDataset(X_train, y_train)
valid_data = TensorDataset(X_valid, y_valid)
test_data = TensorDataset(X_test,y_test)
# dataloaders
batch_size = 32
# make sure the SHUFFLE your training data
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size,drop_last=True)
valid_loader = DataLoader(valid_data, shuffle=True, batch_size=batch_size,drop_last=True)
test_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size,drop_last=True)
- 建立模型
if(USE_CUDA):
print('Training on GPU.')
else:
print('No GPU available, training on CPU.')
Training on GPU.
class bert_lstm(nn.Module):
def __init__(self, hidden_dim,output_size,n_layers,bidirectional=True, drop_prob=0.5):
super(bert_lstm, self).__init__()
self.output_size = output_size
self.n_layers = n_layers
self.hidden_dim = hidden_dim
self.bidirectional = bidirectional
#Bert ----------------重点,bert模型需要嵌入到自定义模型里面
self.bert=BertModel.from_pretrained("../chinese-bert_chinese_wwm_pytorch/data")
for param in self.bert.parameters():
param.requires_grad = True
# LSTM layers
self.lstm = nn.LSTM(768, hidden_dim, n_layers, batch_first=True,bidirectional=bidirectional)
# dropout layer
self.dropout = nn.Dropout(drop_prob)
# linear and sigmoid layers
if bidirectional:
self.fc = nn.Linear(hidden_dim*2, output_size)
else:
self.fc = nn.Linear(hidden_dim, output_size)
#self.sig = nn.Sigmoid()
def forward(self, x, hidden):
batch_size = x.size(0)
#生成bert字向量
x=self.bert(x)[0] #bert 字向量
# lstm_out
#x = x.float()
lstm_out, (hidden_last,cn_last) = self.lstm(x, hidden)
#print(lstm_out.shape) #[32,100,768]
#print(hidden_last.shape) #[4, 32, 384]
#print(cn_last.shape) #[4, 32, 384]
#修改 双向的需要单独处理
if self.bidirectional:
#正向最后一层,最后一个时刻
hidden_last_L=hidden_last[-2]
#print(hidden_last_L.shape) #[32, 384]
#反向最后一层,最后一个时刻
hidden_last_R=hidden_last[-1]
#print(hidden_last_R.shape) #[32, 384]
#进行拼接
hidden_last_out=torch.cat([hidden_last_L,hidden_last_R],dim=-1)
#print(hidden_last_out.shape,'hidden_last_out') #[32, 768]
else:
hidden_last_out=hidden_last[-1] #[32, 384]
# dropout and fully-connected layer
out = self.dropout(hidden_last_out)
#print(out.shape) #[32,768]
out = self.fc(out)
return out
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
number = 1
if self.bidirectional:
number = 2
if (USE_CUDA):
hidden = (weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float().cuda(),
weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float().cuda()
)
else:
hidden = (weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float(),
weight.new(self.n_layers*number, batch_size, self.hidden_dim).zero_().float()
)
return hidden
output_size = 1
hidden_dim = 384 #768/2
n_layers = 2
bidirectional = True #这里为True,为双向LSTM
net = bert_lstm(hidden_dim, output_size,n_layers, bidirectional)
#print(net)
- 训练模型
# loss and optimization functions
lr=2e-5
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# training params
epochs = 10
# batch_size=50
print_every = 7
clip=5 # gradient clipping
# move model to GPU, if available
if(USE_CUDA):
net.cuda()
net.train()
# train for some number of epochs
for e in range(epochs):
# initialize hidden state
h = net.init_hidden(batch_size)
counter = 0
# batch loop
for inputs, labels in train_loader:
counter += 1
if(USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
h = tuple([each.data for each in h])
net.zero_grad()
output= net(inputs, h)
loss = criterion(output.squeeze(), labels.float())
loss.backward()
optimizer.step()
# loss stats
if counter % print_every == 0:
net.eval()
with torch.no_grad():
val_h = net.init_hidden(batch_size)
val_losses = []
for inputs, labels in valid_loader:
val_h = tuple([each.data for each in val_h])
if(USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
output = net(inputs, val_h)
val_loss = criterion(output.squeeze(), labels.float())
val_losses.append(val_loss.item())
net.train()
print("Epoch: {}/{}...".format(e+1, epochs),
"Step: {}...".format(counter),
"Loss: {:.6f}...".format(loss.item()),
"Val Loss: {:.6f}".format(np.mean(val_losses)))
Epoch: 1/10... Step: 7... Loss: 0.679703... Val Loss: 0.685275
Epoch: 1/10... Step: 14... Loss: 0.713852... Val Loss: 0.674887
.............
Epoch: 10/10... Step: 35... Loss: 0.078265... Val Loss: 0.370415
Epoch: 10/10... Step: 42... Loss: 0.171208... Val Loss: 0.323075
- 测试
test_losses = [] # track loss
num_correct = 0
# init hidden state
h = net.init_hidden(batch_size)
net.eval()
# iterate over test data
for inputs, labels in test_loader:
h = tuple([each.data for each in h])
if(USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
output = net(inputs, h)
test_loss = criterion(output.squeeze(), labels.float())
test_losses.append(test_loss.item())
output=torch.nn.Softmax(dim=1)(output)
pred=torch.max(output, 1)[1]
# compare predictions to true label
correct_tensor = pred.eq(labels.float().view_as(pred))
correct = np.squeeze(correct_tensor.numpy()) if not USE_CUDA else np.squeeze(correct_tensor.cpu().numpy())
num_correct += np.sum(correct)
print("Test loss: {:.3f}".format(np.mean(test_losses)))
# accuracy over all test data
test_acc = num_correct/len(test_loader.dataset)
print("Test accuracy: {:.3f}".format(test_acc))
Test loss: 0.442 Test accuracy: 0.827
- 直接用训练的模型推断
def predict(net, test_comments):
result_comments=pretreatment(test_comments) #预处理去掉标点符号
#转换为字id
tokenizer = BertTokenizer.from_pretrained("./chinese-bert_chinese_wwm_pytorch/data")
result_comments_id=tokenizer(result_comments,padding=True,truncation=True,max_length=120,return_tensors='pt')
tokenizer_id=result_comments_id['input_ids']
inputs=tokenizer_id
batch_size = inputs.size(0)
# initialize hidden state
h = net.init_hidden(batch_size)
if(USE_CUDA):
inputs = inputs.cuda()
net.eval()
with torch.no_grad():
# get the output from the model
output = net(inputs, h)
output=torch.nn.Softmax(dim=1)(output)
pred=torch.max(output, 1)[1]
# printing output value, before rounding
print('预测概率为: {:.6f}'.format(output.item()))
if(pred.item()==1):
print("预测结果为:正向")
else:
print("预测结果为:负向")
comment1 = ['菜品一般,不好吃!!']
predict(net, comment1)
预测概率为: 0.015379 预测结果为:负向
comment2 = ['环境不错']
predict(net, comment2)
预测概率为: 0.972344 预测结果为:正向
comment3 = ['服务员还可以,就是菜有点不好吃']
predict(net, comment3)
预测概率为: 0.581665 预测结果为:正向
comment4 = ['服务员还可以,就是菜不好吃']
predict(net, comment4)
预测概率为: 0.353724 预测结果为:负向
- 保存模型
# 保存
torch.save(net.state_dict(), './大众点评二分类_parameters.pth')
- 加载保存的模型,进行推断
output_size = 1
hidden_dim = 384 #768/2
n_layers = 2
bidirectional = True #这里为True,为双向LSTM
net = bert_lstm(hidden_dim, output_size,n_layers, bidirectional)
net.load_state_dict(torch.load('./大众点评二分类_parameters.pth'))
<All keys matched successfully>
# move model to GPU, if available
if(USE_CUDA):
net.cuda()
comment1 = ['菜品一般,不好吃!!']
predict(net, comment1)
预测概率为: 0.015379 预测结果为:负向
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
利用神经网络进行分类任务时,在最后需要经过激活函数,对神经网络的原始输出值进行处理,输出每个类别的概率。本文将讨论用Sigmoid函数或Softmax函数处理原始输出值,进行分类问题。
Sigmoid函数
公式如下所示:
$$s(x_i)=\frac{1}{1+ e^{-x_i}}$$
函数曲线,单调递增,并且值域(0,1):
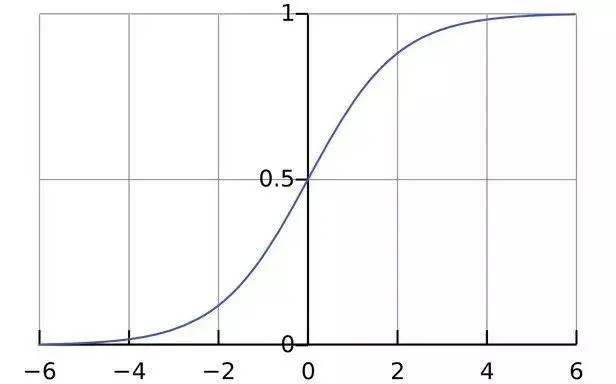
可以看出对于每个值 $[x_1,x_2,x_3,...,x_n]$,都能计算出其对应的Sigmoid函数值,他们之间互不影响,只和 $x_i$ 大小有关
以上为纯数学理论,回到神经网络分类问题,神经网络的原始输出值,经过Sigmoid函数后,可以计算出各个类别的概率,那么这些概率之间互不影响,他们之和有可能大于1,有可能小于1。
由于各个类别概率相互独立,Sigmoid函数可以用于多分类任务问题,比如一张图片里面,既有狗也有猫也有人,那么神经网络训练后,输出的原始值,经过Sigmoid函数,狗、猫、人的概率应该都比较高且接近于1
Softmax函数
公式如下所示: $$s(x_i)=\frac{e^{x_i}}{e^{x_1}+e^{x_2}+...+e^{x_n}}$$ 通过公式可以看出每个值 $[x_1,x_2,x_3,...,x_n]$,经过Softmax函数后,所有输出概率的总和为1,类似与标准化概念,由于分母是所有值经过计算后的和,所以求出的概率不是相互独立,而是有关的,也就是有概率大的,那么就有概率小的,总之他们的和为1
回到神经网络,神经网络输出的原始值,经过Softmax函数,可以计算出各个类别的概率,且各类别的概率之和为1
由于各个类别概率不是相互独立,概率之和为1,Softmax函数常用于二分类任务问题,比如NLP的情感判别问题,那么神经网络训练后,输出的原始值,经过Softmax函数,正向与负向的概率和为1,那么肯定有一个概率大于0.5,一个概率小于0.5,可以用来判断一个句子的正负向
区别
- Sigmoid函数
Sigmoid =多类别分类问题=可以有多个正确答案=独立输出
例如:图像里面包含多个物体
- Softmax函数
Softmax =多类别分类问题=只有一个正确答案=非相互独立
例如:手写数字
常用于二分类问题
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号DataShare,不定期分享干货
作者:数据人阿多
概念
排列组合是组合学最基本的概念。 排列(Permutation),就是指从给定个数的元素中取出指定个数的元素进行排序。 组合(Combination)则是指从给定个数的元素中仅仅取出指定个数的元素,不考虑排序。
比如有1、2、3这三个数字,要进行排列,则一共有以下6种情况:
- 1,2,3
- 1,3,2
- 2,1,3
- 2,3,1
- 3,1,2
- 3,2,1
数字比较少的时候,咱们可以直接手动一一列举出来,如果有n个数字,怎么快速计算排列数呢?咱们可以靠已有的认知,自己写出公式。
-
第1个数字有多少种情况 从n个数字里面,随机选一个数字,那么肯定有n种情况,比如:箱子里面有n个球,然后随机从箱子里面抓一个球,那么有n种情况
-
第2个数字有多少种情况 前面已经取出一个数字,现在剩下n-1个数字,那么就有n-1种情况
-
第3个数字有多少种情况 同理,前面已经取出二个数字,剩下n-2个数字,那么就有n-2种情况
-
…………………………
-
第n个数字有多少种情况 前面已经取出n-1个数字,剩下1个数字,就只能取剩下的1个数字,别无选择,那么就只能有这1种情况
综合以上情况,那就是 $$n \times (n-1) \times (n-2) \times \cdots \times 1$$ (数学其实就是这样,并没有什么高深的公式,就是靠一点一点简单的公式累积起来,只要逻辑严谨,推导过程详细,小白也能看得懂)
以上是对给的所有数字进行排列的情况,而更一般的情况是,给n个球,从中选择m个,计算有多少种排列情况,道理和上面一样,下面直接给出计算公式,不再赘述。
通用公式如下所示:
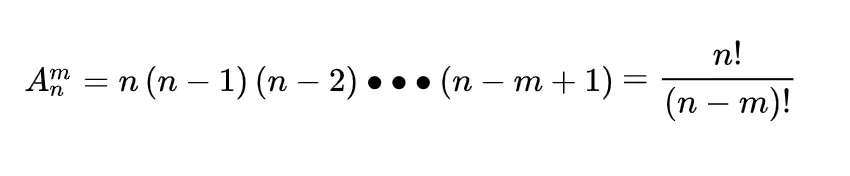
Python实现
from itertools import permutations
a=list(range(3))
list(permutations(a))
list(permutations(a,2))
list(permutations(range(3)))
list(permutations(range(3),2))
作者:数据人阿多
背景
闰年计算在平时很常见,不管是面试还是业务数据处理,基本都会涉及到闰年的计算逻辑,那么就来问一下ChatGPT(基于 4o 模型回答),让他来帮我们详细解释一下闰年的计算逻辑
问题1:判断闰年的计算逻辑
基本规则:
- 一个年份如果能被4整除并且不能被100整除,则是闰年
- 一个年份如果能被400整除,也是闰年
这些规则总结起来就是:
- 如果年份能被4整除,但不能被100整除,是闰年
- 如果年份能被400整除,是闰年
- 其他情况下,年份不是闰年
具体逻辑解释
1. 能被4整除的年份:
- 这是最基本的规则,因为地球绕太阳转一圈大约365.25天,所以每四年增加一天(即闰年)
2. 不能被100整除的年份:
- 除了每四年增加一天之外,还需要排除能被100整除的年份,因为这些年份会多算一天。例如,1700年、1800年和1900年都不是闰年
3. 能被400整除的年份:
- 能被400整除的年份是闰年。这是为了纠正前两个规则的偏差。例如,1600年和2000年是闰年
问题2:为什么要排除能被100整除的年份?
排除能被100整除的年份是为了更精确地调整地球绕太阳运行的时间与历法之间的差异。具体原因可以从天文学和历法的历史背景中找到
历史和天文学背景
1. 基本历法需求:
- 地球绕太阳一周的实际时间大约是365.2425天
- 最早的儒略历(由儒略·凯撒于公元前46年引入)规定每四年一个闰年,即平均一年365.25天。这比实际时间多了大约0.0075天
2. 累积误差:
- 这个0.0075天的误差在短时间内不明显,但在长时间内会累积。例如,经过400年,误差约为3天(0.0075天 × 400年)
- 因此,需要对历法进行调整,以避免季节与日期的逐渐错位
3. 格里高利历的引入:
- 为了纠正儒略历的累积误差,教皇格里高利十三世在1582年引入了格里高利历(即现在广泛使用的公历)
- 格里高利历规定:
- 平年为365天。
- 能被4整除的年份是闰年(增加一天,即366天)。
- 能被100整除但不能被400整除的年份为平年(不增加一天)。
- 能被400整除的年份为闰年(增加一天)。
为什么排除能被100整除的年份?
- 调整闰年频率:
- 每四年增加一天,平均每年增加0.25天。为了更精确,必须减少一些多余的闰年
- 能被100整除的年份不设为闰年,等效于每100年减少1天
- 进一步校正:
- 这种调整依然会有小误差,故进一步设定能被400整除的年份仍为闰年,相当于每400年再增加1天,从而使得历法更精确
数学证明
- 基本调整:每4年一个闰年,每年多0.25天
- 每100年减少1天,相当于每年多0.25天 - 0.01天 = 0.24天
- 每400年再加1天,相当于每年多0.24天 + 0.0025天 = 0.2425天
这与实际地球绕太阳一周的时间365.2425天非常接近,从而极大地减少了历法与天文年的误差
通过这么两问,是不是解释得非常清楚,相当于一个资深老师给你解释了一遍,后续再遇到问题时,大家可以试着问下 ChatGPT ,也许会有更详细解释
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在计算相似度时,常常用到余弦夹角来判断相似度,Cosine(余弦相似度)取值范围[-1,1],当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1,两个方向正交时夹角余弦取值为0。 $$cos(x_1,x_2)=\frac{x_1·x_2}{|x_1||x_2|}$$ 在实际业务中运用的地方还是挺多的,比如:可以根据历史异常行为的用户,找出现在有异常行为的其他用户;在文本分析领域,可以根据一些文章,找出一些相似文章(把文章转换为向量)。
计算相似度的方法除了余弦夹角,还可以利用距离来判断相似,距离越近越相似,这里不做详细展开。
自定义函数法
import numpy as np
def cosine_similarity(x,y):
num = x.dot(y.T)
denom = np.linalg.norm(x) * np.linalg.norm(y)
return num / denom
输入两个np.array向量,计算余弦函数的值
cosine_similarity(np.array([0,1,2,3,4]),np.array([5,6,7,8,9]))
#0.9146591207600472
cosine_similarity(np.array([1,1]),np.array([2,2]))
#0.9999999999999998
cosine_similarity(np.array([0,1]),np.array([1,0]))
#0.0
基于sklearn
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
a1=np.arange(15).reshape(3,5)
a2=np.arange(20).reshape(4,5)
cosine_similarity(a1,a2) #第一行的值是a1中的第一个行向量与a2中所有的行向量之间的余弦相似度
cosine_similarity(a1) #a1中的行向量之间的两两余弦相似度
cosine_similarity(X, Y=None, dense_output=True)
- X :
ndarrayorsparse array, shape:(n_samples_X, n_features)输入数据。X 是一个二维矩阵。 - Y :
ndarrayorsparse array, shape:(n_samples_Y, n_features)输入数据。如果为None,输出将是X中所有样本之间的两两相似度。Y 也是一个二维矩阵
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号DataShare,不定期分享干货
作者:数据人阿多
背景
略微懂点编程的人都知道,计算机其实很死板,是靠简单的逻辑运算、算术运算实现复杂的问题,也就是if-else、加、减等。只不过现在有了升级,更高级、更智能的办法-----人工智能,但是道理还都是一样的,计算机在计算时靠的是它的速度,而人类靠的是大脑、智慧;计算机只不过是把很多情况都列举出来,找到最合适的,而人类靠的是解决问题的方法、智慧。
例如:现在的神经网络在训练参数时,用到的梯度下降,计算机靠它的计算速度一步一步的迭代,可以求出最佳的结果,而人类可以靠已有的智慧,可以直接计算出结果(简单的神经网络)。
所以枚举就是计算机解决问题的根本方法,上一篇文章《利用Python枚举所有的排列情况》,详细介绍了怎么用Python来获取各种排列情况,这一篇文章就利用一道面试算法题,来实际应用一下。
题目如下所示:

解决方法
前面背景已经介绍利用枚举来解决,那么
- 第一步:枚举出所有的排列情况
- 第二步:在每种排列情况里面进行查找
重点是第二步,需要查找前面值比后面值连续大的次数,如果次数满足要求,那就是一种结果
下面就直接展示详细代码:
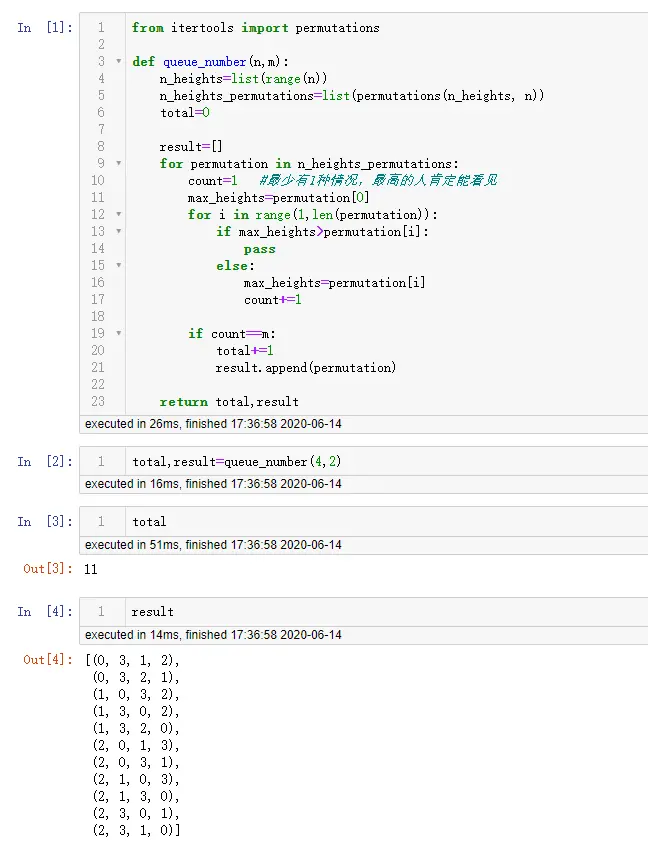
代码:
from itertools import permutations
def queue_number(n,m):
n_heights=list(range(n))
n_heights_permutations=list(permutations(n_heights, n))
total=0
result=[]
for permutation in n_heights_permutations:
count=1 #最少有1种情况,最高的人肯定能看见
max_heights=permutation[0]
for i in range(1,len(permutation)):
if max_heights>permutation[i]:
pass
else:
max_heights=permutation[i]
count+=1
if count==m:
total+=1
result.append(permutation)
return total,result
total,result=queue_number(4,2)
历史相关文章
作者:数据人阿多
背景
在上一篇文章《基于DeepSeek,构建个人本地RAG知识库》中用到了 streamlit 库,于是小编初步深入了解了一下,感觉很好用,是数据人的一个好帮手,避免学习前端知识,利用该库直接在 Python 中编码代码,然后启动服务后,在浏览器中可以直接查看 web 页面,省略了后端、前端构建 web 的繁琐过程,数据人可以直接把自己的数据以 web 形式展示出来
小编环境
import sys
print('python 版本:',sys.version)
#python 版本: 3.11.11 | packaged by Anaconda, Inc. |
#(main, Dec 11 2024, 16:34:19) [MSC v.1929 64 bit (AMD64)]
import streamlit
print(streamlit.__version__)
#1.42.2
import pandas as pd
print(pd.__version__)
#2.2.2
import numpy as np
print(np.__version__)
#2.2.2
import matplotlib
print(matplotlib.__version__)
#3.10.0
streamlit 库使用
1. 安装
和安装其他三方包一样,进行安装 streamlit
pip install streamlit
2. 使用
- 导入需要的库
import streamlit as st
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
- 各种文本
header:一级标题 subheader:二级标题 text:纯文本 markdown:支持markdown语法 code:代码
# 展示一级标题
st.header('2. 使用')
# 展示二级标题
st.subheader('2.1 生成 Markdown 文档')
# 纯文本
st.text("""导入 streamlit 后,就可以直接使用 st.markdown() 初始化,
该方法支持 markdown 语法""")
# markdown
st.markdown('markdown用法:**加粗**,*倾斜* \n - 1 \n- 2 ')
# 展示代码,有高亮效果
code2 = '''import streamlit as st
st.markdown('Streamlit 初步学习')'''
st.code(code2, language='python')
web页面效果:

- 表格
table:普通表格 dataframe:高级表格,可以进行数据的操作,比如排序
# 展示一级标题
st.header('3. 图表')
# markdown
st.markdown('关于数据的展示,streamlit 由两个组件进行支持')
st.markdown('- table:普通的表格,用于静态数据的展示')
st.markdown('- dataframe:高级的表格,可以进行数据的操作,比如排序')
# 展示二级标题
st.subheader('3.1 Table 的示例')
df = pd.DataFrame(
np.random.randn(10, 5),
columns=('第%d列' % (i+1) for i in range(5))
)
st.table(df)
# 展示二级标题
st.subheader('3.2 DataFrame 的示例')
st.dataframe(df.style.highlight_max(axis=0))
web页面效果:
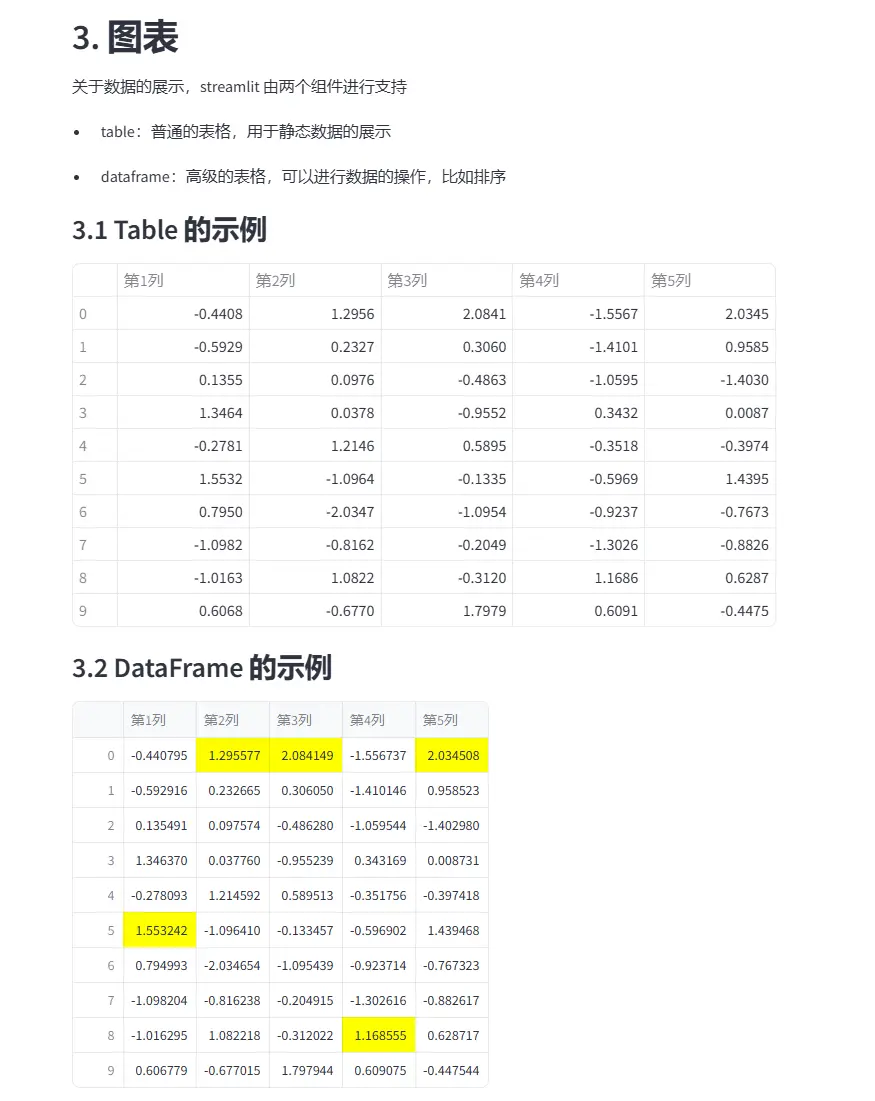
- 监控组件
可以使用 st.columns 先生成3列,然后针对每列调用 metric 方法,生成监控组件
# 展示一级标题
st.header('4. 监控组件')
# markdown
st.markdown('streamlit 也为你提供的 metric 组件')
col1, col2, col3 = st.columns(3)
col1.metric("温度", "70 °F", "1.2 °F")
col2.metric("风速", "9 mph", "-8%")
col3.metric("湿度", "86%", "4%")
web页面效果:

- 内部原生图表
Streamlit 原生支持多种图表:
- st.line_chart:折线图
- st.area_chart:面积图
- st.bar_chart:柱状图
- st.map:地图
# 展示一级标题
st.header('5. 原生图表组件')
# markdown
st.markdown('Streamlit 原生支持多种图表:')
st.markdown('- st.line_chart:折线图')
st.markdown('- st.area_chart:面积图')
st.markdown('- st.bar_chart:柱状图')
st.markdown('- st.map:地图')
# 展示二级标题
st.subheader('5.1 折线图')
chart_data = pd.DataFrame(
np.random.randn(20, 3),
columns=['a', 'b', 'c'])
st.line_chart(chart_data)
# 展示二级标题
st.subheader('5.2 面积图')
chart_data = pd.DataFrame(
np.random.randn(20, 3),
columns = ['a', 'b', 'c'])
st.area_chart(chart_data)
st.area_chart(chart_data,x_label='x',y_label='y',stack='center')
st.area_chart(chart_data,x_label='x',y_label='y',stack=True)
st.area_chart(chart_data,x_label='x',y_label='y',stack=False)
# 展示二级标题
st.subheader('5.3 柱状图')
chart_data = pd.DataFrame(
np.random.randn(5, 3),
columns = ["a", "b", "c"])
st.bar_chart(chart_data)
st.bar_chart(chart_data,stack=False)
st.bar_chart(chart_data,stack=False,horizontal=True)
# 展示二级标题
st.subheader('5.3 地图')
df = pd.DataFrame(
np.random.randn(1000, 2) / [50, 50] + [39.91, 116.41],
columns=['lat', 'lon']
)
st.map(df)
web页面效果:
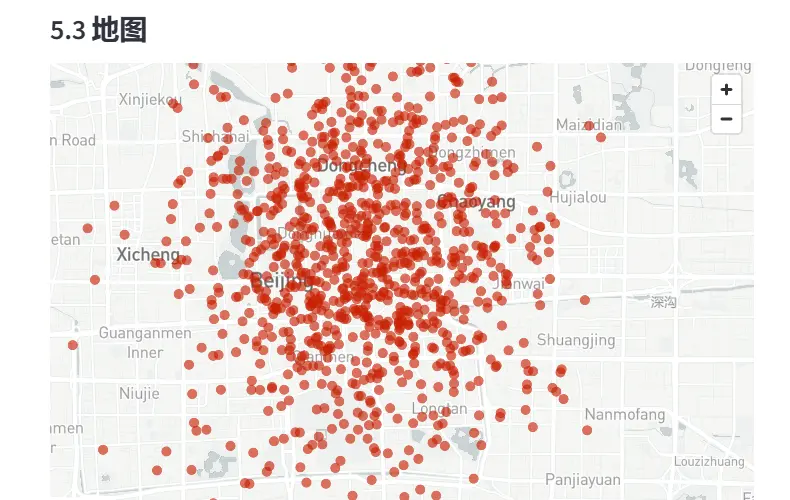
- 集成三方库图表
Streamlit 除了一些原生图表组件,同时还支持像 matplotlib.pyplot、Altair、vega-lite、Plotly、Bokeh、PyDeck、Graphviz 等的外部图表,这里演示一下 matplotlib.pyplot 的用法
# 展示一级标题
st.header('6. 外部图表组件')
st.markdown("""
Streamlit 的一些原生图表组件,虽然做到了傻瓜式,但仅能输入数据、高度和宽度,
如果你想更漂亮的图表,就像
matplotlib.pyplot、Altair、vega-lite、Plotly、Bokeh、PyDeck、Graphviz
那样,streamlit 也提供了支持:
- st.pyplot
- st.bokeh_chart
- st.altair_chart
- st.altair_chart
- st.vega_lite_chart
- st.plotly_chart
- st.pydeck_chart
- st.graphviz_chart
"""
)
# 展示二级标题
st.subheader('6.1 matplotlib.pyplot')
arr = np.random.normal(1, 1, size=100)
print(arr)
fig, ax = plt.subplots()
ax.hist(arr, bins=20)
st.pyplot(fig)
web页面效果:
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多 日期:2026年4月24日
背景
你有没有想过,CPU在等待数据时,竟然有一套完全不同于人类的“时间观”
在计算机体系结构里,有一张很经典的延迟对比表,把CPU从不同设备读取数据所需的时钟周期,用一种脑洞大开的方式换算成了人类能直接感受的时间
换算前提:假设 CPU 主频为 1 GHz,即每秒运行 10 亿个周期,所需时间1 纳秒
如果1秒运行1次,那么就是1Hz,如果1秒运行1000次,那么就是1KHz
1秒(s) = 1000 毫秒(ms) = 1000_000 微秒(µs) = 1000_000_000 纳秒(ns)
| 设备类型 | CPU周期(计算机时间) | 换算为人类时间 |
|---|---|---|
| L1 缓存 | 3 | 3 秒 |
| L2 缓存 | 14 | 14 秒 |
| RAM | 250 | 4 分 10 秒 |
| 磁盘 | 41,000,000 | 1.3 年 |
| 网络 | 240,000,000 | 7.6 年 |
如果只看左边两列的数字,3 个周期和 2.4 亿个周期之间已经差了近 1 亿倍。但老实说,3 纳秒也好,240 毫秒也罢,对我们人类来说都只是一瞬间,很难真正感受到这种数量级的恐怖差距
上述表格的作者想出的这个类比缩放简直绝了——把 1 个 CPU 周期当成 1 秒
将 1 个周期主观放大为 1 秒,相当于把计算机里的时间放慢了 10 亿倍 (1000_000_000 倍,10^9 倍)
这样一来,事情就完全不同了:
- 读 L1 缓存只需 3 秒,就像伸手拿起桌上的杯子,不痛不痒
- 读 L2 缓存是 14 秒,相当于等红绿灯时看一眼手机,完全能接受
- 读内存变成 4 分多钟,已经接近用微波炉热一杯牛奶的时间——你开始觉得“有点慢”了,但还能忍
- 读磁盘一下子跳到 1.3 年,相当于你委托别人办一件事,等他一年后才回来
- 读网络,整整 7.6 年,一个刚上小学的孩子,等一次网络数据到达,都快小学毕业了
现在你应该能感同身受了:对 CPU 来说,访问内存、磁盘和网络,在“体感”上就是从几秒钟的举手之劳,变成了以“年”为单位的漫长等待
这张表格不仅是计算机专业的经典梗,更悄悄划定了 Python 后端性能优化的两条根本路径:
- 磁盘和网络这种“年级”等待,靠异步编程来应对
- CPU 本身的密集型计算,靠任务队列或底层语言重写来解决
今天我们就从这张“人类时间表”出发,聊聊 Python 异步编程的核心知识,以及当 CPU 成为瓶颈时,最务实的优化策略
异步编程:如何优雅地等待“7.6 年”?
网络请求在现实中可能只需要几百毫秒,但用表里的比喻,那就是 7.6 年的漫长岁月,如果代码是同步的,整个线程就会傻傻地站在原地,等这 7.6 年过去,期间什么也做不了,而异步编程的核心思想就一句话:遇到 I/O 等待时,把控制权交出去,先去干别的事,等数据就绪了再回来
Python 从 3.4 开始逐步引入了原生的异步支持,核心武器是 asyncio 库和 async/await 语法:
async def定义一个异步函数,调用它并不会立刻执行,而是返回一个协程对象await可以挂起当前协程,等待一个耗时操作(比如网络请求)完成,在等待的这段时间里,事件循环会去执行其他协程asyncio提供的事件循环负责调度所有协程,就像一个极其高效的管家:“A 在等外卖,B 去炒菜;B 需要腌肉十分钟,C 去切葱……”
正是这种“非阻塞等待”的机制,让一个线程(所有事件循环运行在一个线程中),同时扛住成千上万个连接,这也是 FastAPI、aiohttp 等异步框架能轻松实现高并发的原因,它们把网络、磁盘这些“7.6 年”的等待,变成了事件循环里轻巧的上下文切换,让 CPU 一直在做真正有意义的计算
🌟 一句话总结:异步擅长处理 I/O 密集型任务,比如大量 API 调用、数据库查询、文件读写
但它不擅长 CPU 密集型任务——因为计算需要长时间连续占用 CPU,根本没机会让出控制权,反而会阻塞整个事件循环,让所有其他协程饿死
当 CPU 成为瓶颈:异步的软肋与解法
如果服务中有大量数学运算、图像处理、视频转码、数据压缩这类重 CPU 操作,单纯靠 async/await 非但帮不上忙,还会因为单个任务长时间霸占事件循环,导致其他请求超时,我们就需要专门针对 CPU 瓶颈制定策略
常见的三种策略各有侧重:
| 策略 | 核心做法 | 适用场景 |
|---|---|---|
| 策略1:多进程池 | 用 ProcessPoolExecutor 提交给独立进程执行 | 简单并行计算,任务间无依赖 |
| 策略2:外部任务队列 | 将任务交给独立 worker 集群(如 Celery + Redis) | 通用 CPU 密集型异步化,水平扩展 |
| 策略3:用编译语言重写 | 用 C、Rust、Cython 重写热点代码,并释放 GIL | 追求极限性能,单任务延迟要求极高 |
在现代 Python 后端服务中,策略 2 是基础标配,策略 3 是进阶大招,两者经常组合使用
策略2:外部任务队列(消息中间件) —— “默认操作”
几乎所有生产级的 Python Web 服务都会用任务队列来剥离 CPU 任务,典型的架构如下:
- Web 服务收到请求后,把耗时的计算任务序列化(比如转成 JSON),丢进消息队列(Redis、RabbitMQ 等)
- 另一批独立运行的 Celery Worker 进程从队列里取出任务,慢慢执行
- 前端可以通过轮询、WebSocket 或回调来获取最终结果
这么做的好处非常明显:
- Web 进程瞬间释放,可以立刻去处理下一个请求,保持低延迟、高并发;
- Worker 可以线性扩展,单机不够就加机器,完全绕过 Python 的 GIL 限制;
- 任务还天然拥有了重试、监控、延迟执行等能力,非常适合微服务架构
引入任务队列也带来了新的复杂度:消息中间件的维护、结果后端的选型、全局监控等等,不过对于中大型项目来说,这些投入非常值得,而任务队列没有真正减少单个任务的原始 CPU 时间,只是把活儿分给了更多的工人
策略3:用编译语言重写 —— 最后的性能大招
如果某个计算本身真的慢到无法接受,即使加再多 Worker 也无济于事,这时候就需要祭出最终武器:用 C、Rust 或 Cython 重写性能热点,并且在计算密集阶段手动释放 GIL
Python 的全局解释器锁(GIL)导致一个进程内的多个线程,同一时刻只能有一个线程执行 Python 字节码,但如果用 Rust 写了一个计算密集的函数库,并且在进入计算时调用这个库,就可以暂时把 GIL 交出去,允许同一进程内的其他线程同时执行,在多核 CPU 上,这能实现真正的并行计算
当有一个函数被频繁调用且优化到极致仍不满足要求时,可以用编译型语言重写并作为Python扩展导入,近年来 Rust + PyO3 组合凭借内存安全和极致性能,已成为新一代标准
真实世界的组合拳
在实际项目中,策略 2 和策略 3 往往同时出现:
- 用户上传一张图片 → FastAPI 异步接口接收请求
- → 任务被快速扔进 Redis 队列
- → Celery Worker 取出任务
- → Worker 内部调用一个用 Rust 编写且释放了 GIL 的图片处理库
- → 多核并行压缩、加水印,生成缩略图
- → 结果写回数据库,前端通过 WebSocket 获得通知
外部任务队列解决了架构层面的并发与调度问题,底层语言重写解决了单任务的绝对性能问题
从 CPU 等待时长表看优化哲学
上面把 1 个周期膨胀为 1 秒的表格,不只是博人一笑,它其实藏着一条非常朴素但极其有效的优化原则:让数据尽可能待在离 CPU 最近的地方,避免掉进遥远的“年”等待
Python 后端的日常实践就是:
- 对网络和磁盘 I/O,拥抱
asyncio,用异步把漫长的等待变成非阻塞的切换; - 对CPU 密集计算,用任务队列将它们移出 Web 进程,必要时用 C/Rust 重写热点;
- 在代码细节上,保持内存访问的局部性,避免在循环里大量创建零散的小对象,让 CPU 尽量命中缓存
当我们用 await 处理掉一个个“7.6 年”,又用任务队列和 Rust 重写把“几年的等待”压缩成“几秒”,每个请求的体验才能真正顺滑起来——就像伸手拿杯子一样,3 秒钟,毫不费力
总结
- Python 异步(
asyncio) 是 I/O 密集型服务的高并发基石,通过事件循环避免等待浪费 - CPU 密集型任务必须剥离出异步主循环,首选外部任务队列实现异步化和水平扩展
- 当单任务延迟仍不满足要求时,用 C/Rust/Cython 重写热点并释放 GIL,达成真正的多核并行加速
- 记住那张“人类时间表”,它会时刻提醒你:优化应该最先瞄准那些最慢的等待,异步和 CPU 外移,正是这一思想在现代 Python 后端中最经典的实践
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在平时业务运营分析中经常会提取数据,也就是大家俗称的Sql Boy,表哥表姐,各大公司数据中台现在大部分用的都是基于Hadoop的分布式系统基础架构,用的比较多的有Hive数据仓库工具,数据分析师在数据查询时用的就是HQL,语法与Mysql有所不同,基本每天都会写大量的HQL语句,但你有试过哪些风格的写法呢?哪种风格的查询语句更容易理解呢?可能不同的人有不同的看法,下面展示具体的风格代码样式,看看你喜欢哪种
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
风格一
这种风格大家都比较常用,从结果向源头倒着推,直接多层嵌套,一层一层往里面写,业务逻辑复杂的话有可能写很多层,达到几百行之多,目前很多公司在有数仓的支持下,基本嵌套的层数会比较少
select *
from
(
(select *
from a_temp
where xxxx
group by xxxx) as a
left join
(select *
from b_temp
where xxxx) as b
on a.id=b.id
) temp
where xxxx
group by xxxx
order by xxxx
风格二
这种风格是利用 with 语句,从源头向结果正向推,可以把 with 语句理解为建立了一个临时视图/表一样,后面的表引用前面的表,逻辑是正向推进
with a as(select *
from a_temp
where xxxx
group by xxxx),
b as(select *
from b_temp
where xxxx)
select *
from a left join b on a.id=b.id
where xxxx
group by xxxx
order by xxxx
两种风格的区别
- 风格一:用的最多,从结果向源头倒着推
- 风格二:容易理解,从源头向结果正向推
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
最近对用户的行为数据进行统计分析时,需要列出不同用户的具体详情,方便进行观察,在hive中虽然有排序函数,但是处理键值对数据时,不能根据值进行排序,需要巧妙借助中间过程来处理,总结出来与大家进行分享,也方便后面自己查找使用
预想效果
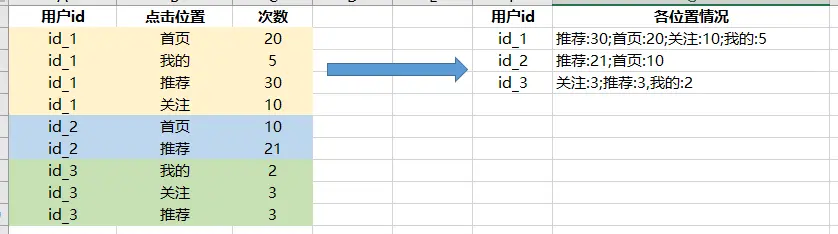
创建测试数据
--创建临时表
use test;
create table tmp_datashare
(id string comment '用户id',
click string comment '点击位置',
cnt int comment '点击次数')
COMMENT '用户点击行为统计'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
--加载数据
load data local inpath '/tmp/datashare.txt' overwrite into table tmp_datashare;
测试数据:
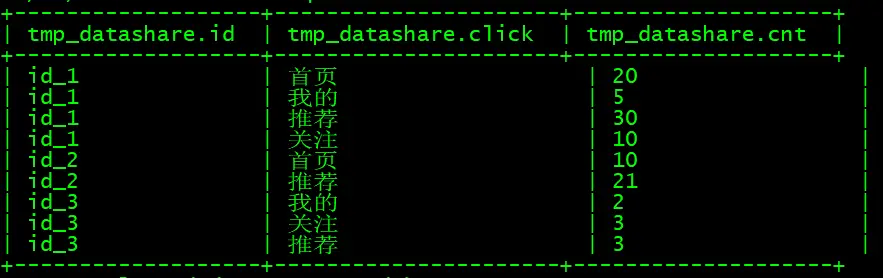
数据处理过程
数据处理具体步骤:
- 运用窗口函数进行降序排列增加一个添加辅助列
- 对数据进行拼接并补全数字,比如:id_1中
首页:20,降序序号:2,需要转换为00002:首页:20- 然后再进行分组聚合运用
sort_array进行排序,并进行拼接- 最后再进行替换
具体代码如下:
with a as (select id,click,cnt,
row_number() over(partition by id order by cnt desc) as rn
from tmp_datashare
),
b as (select id,click,cnt,
concat(lpad(rn, 5, '0'), '#', click, ':',cnt) as click_cnt_temp_1
from a
),
c as (select id,
concat_ws(';',
sort_array(collect_list(click_cnt_temp_1))
) as click_cnt_temp_2
from b
group by id
)
select id,regexp_replace(click_cnt_temp_2,'\\d+#','') as click_cnt
from c
结果数据:
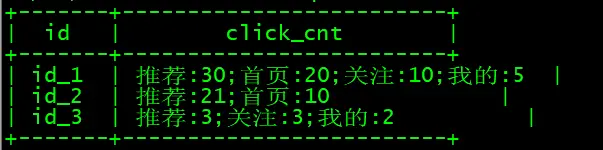
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
业务场景:统计每个小时视频同时在线观看人数,因后台的业务数据是汇总之后的,只有开始时间、结束时间,没有每小时的详细日志数据,无法直接进行统计,所以需要对每条业务数据进行拆分,来统计每个小时的同时数
当然,如果有详细的日志数据也是直接可以统计的,但是正常情况下,日志数据会非常大,如果每个用户每30秒会产生一条数据,那么每天会产生大量的数据,如此大量的数据,很难长期保存
模拟数据与需求效果展示
对每行数据,按每小时进行拆分,结果如下所示:
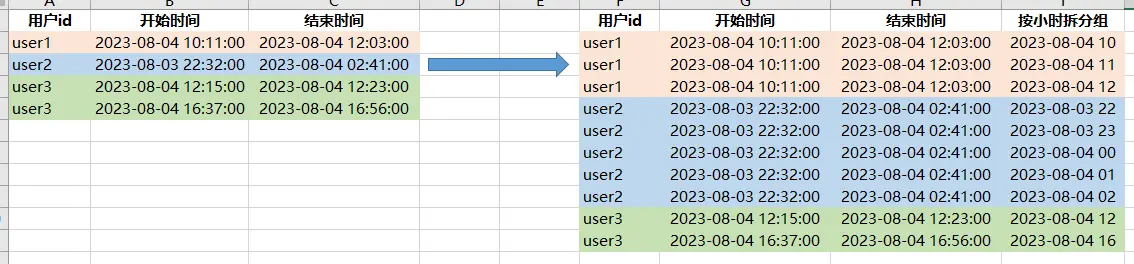
创建测试数据
--创建临时表
create table test.tmp_datashare
(user_id string comment '用户id',
start_time string comment '开始时间',
end_time string comment '结束时间')
comment '业务数据'
row format delimited fields terminated by '\t'
lines terminated by '\n';
--加载数据
load data local inpath '/tmp/datashare.txt'
overwrite into table test.tmp_datashare;
测试数据:

数据处理过程
- 数据处理的要点:
需要借助以下两个函数生成连续序列,然后用开始时间与该序列进行加和,生成相应的结果
space:空格字符串函数,语法: space(int n),返回长度为n的空字符串
posexplode:炸裂函数,会同时返回两个值,数据的下标索引、数据的值
- 具体代码如下:
左右滑动查看代码
set hive.cli.print.header=true;
with a as(select user_id,start_time,end_time
from test.tmp_datashare
),
b as(select user_id,start_time,end_time,pos
from a
lateral view posexplode(
split(
space(
cast((unix_timestamp(substr(end_time,1,13),'yyyy-MM-dd HH')-
unix_timestamp(substr(start_time,1,13),'yyyy-MM-dd HH'))/3600 as int)),
' ')
) tmp as pos,val
)
select user_id,start_time,end_time,
from_unixtime(unix_timestamp(start_time,'yyyy-MM-dd HH:mm:ss')+3600*pos,
'yyyy-MM-dd HH') as start_time_every_hh
from b
order by user_id,start_time_every_hh
- 结果数据:
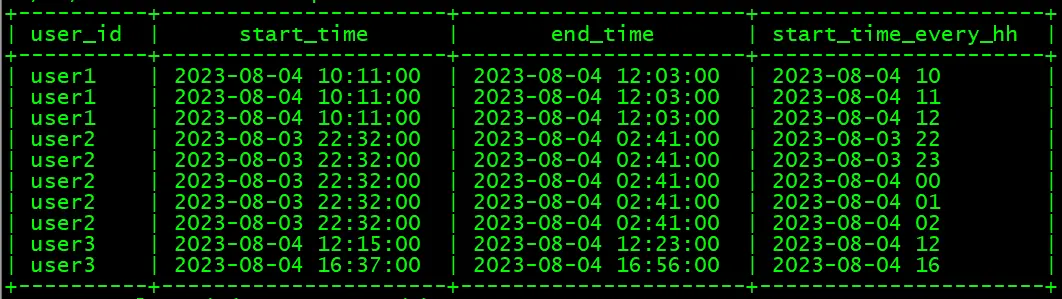
历史相关文章
- Hive中对相邻访问时间进行归并分组
- Hive 数据聚合成键值对时,根据值大小进行排序
- Hive中的常用函数
- Hive中各种日期格式转换方法总结
- Hive HQL支持的2种查询语句风格,你喜欢哪一种?
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
现阶段各个公司的数据慢慢的增多,很多数据都是存放在基于Hadoop的集群上,数据的查询一般使用的是hive,很多公司的数据中台也是使用hive来进行数据处理,本篇文章就来分享下在hive中常用的函数
常用函数
set类设置
- 查询结果显示表头
set hive.cli.print.header=true;
- 设置Fetch抓取,不走job
set hive.fetch.task.conversion=more;
- 展示数据库
set hive.cli.print.current.db=true;
- 修改是否使用静默
set hive.compute.query.using.stats=false;
日期类函数
- 当天
select current_date()
运行结果:'2022-08-11'
- 当月第一天
select trunc(current_date(),'MM')
运行结果:'2022-08-01'
select date_format(to_date(trunc(current_date(),'MM')),"yyyyMMdd")
运行结果:'20220801'
- 当月最后一天
select last_day(current_date)
运行结果:'2022-08-31'
- 上个月
select date_format(add_months(CURRENT_DATE,-1),'yyyyMM')
运行结果:'202207'
- 周几
select pmod(datediff(current_date(),'1900-01-08'),7)+1
运行结果:'4'
- 获取当前时间戳
select unix_timestamp()
运行结果:'1660212154'
字符串类函数
- 字符拼接
--concat(参数1,参数2,...参数n)
select concat('a','b','c')
运行结果:'abc'
select concat('a','b',null,'c') --包含一个null的话,结果为null
运行结果:NULL
- 字符以分割符进行拼接
--concat_ws(分隔符,参数1,参数2,...参数n)
select concat_ws(',','a','b','c')
运行结果:'a,b,c'
select concat_ws(',','a',null,'c') --会忽略null
运行结果:'a,c'
select concat_ws(',',null,null,null) --返回空字符,而不是null
运行结果:''
窗口类函数
-
ROW_NUMBER() –从1开始,按照顺序,生成分组内记录的序列
-
RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
-
DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
-
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值 第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
-
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值 第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
更多窗口函数可参考
《Hive分析函数系列文章》:
http://lxw1234.com/archives/2015/07/367.htm
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
平时在跑数据时,需要在查询语句前设置一些set语句,这些set语句中其中有一些是配置hive的各功能,另一些是可以达到优化的目的,本篇文章对一些常用的set语句进行总结
常用set设置
- 查询结果显示表头
执行完查询语句,输出结果时,会一起把字段的名字也打印出来
set hive.cli.print.header=true; --默认为false,不打印表头
- 展示当前使用的数据库
主要是在命令行模式中使用,方便核查是否切换到相应的数据库下
set hive.cli.print.current.db=true; --默认为false,不显示当前数据库名字
- 设置是否使用元数据中的统计信息
比如想要看数据一共有多少行的话,一般是从元数据中的统计信息直接获取,但有时这个统计信息没有更新,得到的是历史的统计信息,则需要修改为 false,然后再进行查询,才能统计出准确的数据
set hive.compute.query.using.stats=false; --默认为true,使用元数据中的统计信息,提升查询效率
- 设置Fetch抓取,不走job,不用执行MapReduce
一般用于快速获取样例数据,select * from talbe_xxx limit 100
set hive.fetch.task.conversion=more;
- 设置查询任取走哪个队列
一般公司的服务器集群中会配置好几个队列,不同的队列优先级不一样,并且资源配置有可能不一样,生产环境的任务肯定优先级高、计算资源多,数据分析的任务一般是单独的队列,计算资源少
set mapreduce.job.queuename=root.db; --运维人员设置的队列名字
- 是否开启严格模式
一般运维人员会设置为严格模式 strict,防止大量数据计算占用资源,多出现在笛卡尔积join时;或者查询的是分区表,但没有指定分区,明明sql语句没有逻辑错误,但是一直报错无法运行,可以尝试修改为非严格模式,看是否能运行
set hive.mapred.mode=nonstrict; --nonstrict,strict
- with as 语句存储在本地,从而做到with…as语句只执行一次,来提高效率
对应喜欢用 with as 形式查询的话,可以设置一下这个,来提升效率
set hive.optimize.cte.materialize.threshold=1;
- 配置计算引擎
Hive底层的计算由分布式计算框架实现,目前支持三种计算引擎,分别是MapReduce、Tez、 Spark,默认为MapReduce
MapReduce引擎:多job串联,基于磁盘,落盘的地方比较多。虽然慢,但一定能跑出结果。一般处理,周、月、年指标。
Spark引擎:虽然在Shuffle过程中也落盘,但是并不是所有算子都需要Shuffle,尤其是多算子过程,中间过程不落盘 DAG有向无环图。 兼顾了可靠性和效率。一般处理天指标。
Tez引擎:完全基于内存。 注意:如果数据量特别大,慎重使用。容易OOM。一般用于快速出结果,数据量比较小的场景。
set hive.execution.engine=mr; --mr、tez、spark
其他set设置
set hive.exec.parallel=true; --开启任务并行执行
set hive.exec.parallel.thread.number=8; -- 同一个sql允许并行任务的最大线程数
set hive.exec.max.dynamic.partitions=1000 -- 在所有执行MR的节点上,最大一共可以创建多少个动态分区。
set hive.exec.max.dynamic.partitions.pernode=100 -- 在每个执行MR的节点上,最大可以创建多少个动态分区
set hive.auto.convert.join = false; --取消小表加载至内存中
set hive.mapjoin.smalltable.filesize=25000000; --设置小表大小
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
对用户每天的访问次数进行统计时,需要对用户访问页面相邻的时间间隔小于30分钟归并为一组(算是一次),这样可以统计出用户每天的访问次数(忽略隔天问题)。这个问题如果用python来处理可能比较方便,可以循环遍历每行,进行两两之间的比较。利用Hive来处理数据,劣势就是不能循环遍历不够灵活,但是也能处理,只是过程相对比较复杂
模拟数据与预想的效果

创建测试数据
--创建临时表
create table test.tmp_datashare
(user_id string comment '用户id',
url string comment '网页',
create_time string comment '访问时间')
comment '用户访问日志'
row format delimited fields terminated by '\t' lines terminated by '\n';
--加载数据
load data local inpath '/tmp/datashare.txt' overwrite into table test.tmp_datashare;
测试数据:
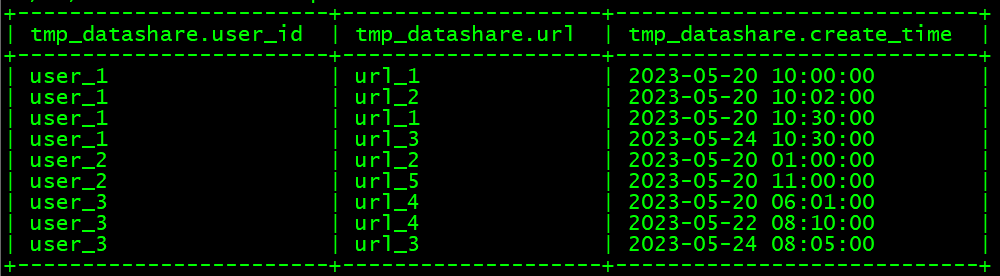
数据处理过程
- 数据处理的难点:
1、时间处理需要用到 UNIX_TIMESTAMP 转换为时间戳
2、运用窗口函数 LAG 提取前一行的访问时间
3、再次运用窗口函数 SUM 进行归并分组
- 具体代码如下:
with a as (select user_id,url,create_time,
lag(create_time,1) over(partition by user_id order by create_time) as last_1_time
from clwtest.tmp_datashare
),
b as (select user_id,url,create_time,
case
when last_1_time is null then 1
when (unix_timestamp(create_time,'yyyy-MM-dd HH:mm:ss')-
unix_timestamp(last_1_time,'yyyy-MM-dd HH:mm:ss'))/60<30 then 0
else 1
end as group_tmp
from a
),
c as (select user_id,url,create_time,
sum(group_tmp) over(partition by user_id order by create_time) as group_id
from b
)
select user_id,url,create_time,group_id
from c
order by user_id,create_time
- 结果数据:
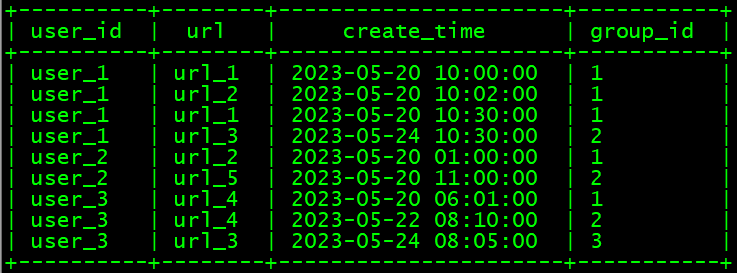
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
日期计算平时在业务取数时经常涉及到,但是数据库中经常存放着不同的日期格式,有的存放是时间戳、有的是字符串等,这时需要对其进行转换才能提取到准确的数据,这里介绍的均是hive里面的函数功能,以下内容均是业务的数据需求经常使用的部分
时间戳
unix时间戳是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒,一般为10位的整数
一个在线工具:https://tool.lu/timestamp/
字符串日期
如:'2021-10-21 19:25:50','2021-10-21 20:25:50.0','2021-10-21 20:25'
日期格式转换
时间戳--->正常的日期格式
- 获取当前时间戳
select unix_timestamp()
- 把时间戳转为正常的日期
select from_unixtime(unix_timestamp(),'yyyy-MM-dd hh:mm:ss') as dt
- 业务中有时存放的是包含毫秒的整数,需要先转换为秒
select from_unixtime(cast(create_time/1000 as bigint),'yyyyMMdd') as dt
字符串日期
假如数据库存放的是格式为:"yyyy-MM-dd hh:mm:ss"
- 截取日期部分
select substr('2021-10-22 17:34:56',1,10)
2021-10-22
- 字符串强制转换,获取日期
select to_date('2021-10-22 17:34:56')
2021-10-22
- 也可以通过date_format实现
select date_format('2021-10-22 17:34:56','yyyy-MM-dd')
2021-10-22
系统当前日期
- 当前日期
select current_date();
2021-10-22
- 字符串日期与系统当前日期比较,这个在业务中经常有用到
select substr('2021-10-22 17:34:56',1,10)>current_date()
false
前一日/昨日
select date_sub(current_date(),1);
2021-10-21
前一日12点/昨日12点
在业务中与截取的字符串日期进行比较时用
select concat(date_format(date_sub(current_date(),1),'yyyy-MM-dd'),' ','12');
2021-10-21 12
最近一个月/30天
select date_sub(current_date(),30);
2021-09-22
当月第一天
业务中经常用在滚动计算当月每日的业绩数据
select date_format(to_date(trunc(current_date(),'MM')),"yyyy-MM-dd");
2021-10-01
日期格式转换 yyyyMMdd--->yyyy-MM-dd
select from_unixtime(unix_timestamp('20211022','yyyyMMdd'),"yyyy-MM-dd");
2021-10-22
两个日期相隔天数
select datediff('2021-10-22', '2021-10-01');
21
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
在本地记事本记得太多了,有的命令使用频次很低,时间长了容易忘记,分享出来后续使用时查找
常用命令
- 列出数据库下的所有表
hadoop fs -ls /user/hive/warehouse/test.db
- 统计数据库占用磁盘的总大小
hadoop fs -du -s -h /user/hive/warehouse/test.db
- 查看数据表中的数据
hadoop fs -cat /user/hive/warehouse/test.db/test/00000_0 | head
- 设置副本数 Hadoop默认是3个副本,replication factor 副本因子
hadoop fs -setrep -R 1 /user/hive/warehouse/test.db/test
- 创建文件夹
hadoop fs -mkdir /user/datashare
- 修改文件权限
hadoop fs -chmod 700 /user/datashare
hadoop fs -chmod -R 700 /user/datashare #递归进行,针对子文件夹
- 检查HDFS中的文件是否存在
hadoop fs -test -e /user/hive/warehouse/test.db/test/0*
- 统计文件个数
hadoop fs -ls -h /user/hive/warehouse/test.db/test/dt=202310 | wc -l
hadoop fs -count /user/hive/warehouse/test.db/test/dt=202310
- 统计多个文件夹的总占用大小
hadoop fs -du -s /user/hive/warehouse/test.db/test/dt=202310* | awk '{print $1}' | awk '{sum+=$1}END{print sum/1024**3 " G"}'
- 统计每个文件夹的单独大小
hadoop fs -du -s /user/hive/warehouse/test.db/test/dt=202310* | awk '{print $1/1024**3 " G"}'
- 跨集群访问
hadoop fs -ls hdfs://10.20.1.100:8100/
- 查看hadoop 版本
hadoop version
- 查看数据缺失的块
hadoop fsck /user/hive/warehouse/test.db/test
- 复制分区至新表
1. CREATE TABLE new_table LIKE old_table;
2. 使用hadoop fs -cp 命令,把old_table对应的HDFS目录的文件夹全部拷贝到new_table对应的HDFS目录下;
3. 使用MSCK REPAIR TABLE new_table;修复新表的分区元数据;
- 查看数据库里面各数据表的大小,并进行排序
hadoop fs -du -s /user/hive/warehouse/test.db/* | sort -n | numfmt --to=iec --field=1
numfmt --to=iec --field=1 的作用是仅将第一列(大小)转换为人类可读的格式,而不改变第二列(路径)的内容。
--field=1 让 numfmt 只处理第一列,从而避免误修改文件路径
- 删除文件、空目录
hadoop fs -rm /user/hive/warehouse/emptydir
- 删除文件夹
hadoop fs -rmr /user/hadoop/dir
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
硬件信息及操作系统信息
服务器:戴尔R740
显卡:英伟达 Tesla V100
操作系统:CentOS Linux release 7.8.2003 (Core)
Anaconda安装
从官网下载 Anaconda3-2020.02-Linux-x86_64.sh,运行后一步一步安装

参考:
https://blog.csdn.net/Gary1_Liu/article/details/81297927
Anaconda环境管理
- 克隆环境
conda create --name newname --clone oldname
例如:conda create --name pytorch1.5 --clone base
- 创建环境
conda create -n 环境名 python=3.7
例如:conda create -n pytorch1.5 python=3.7
- 激活环境
conda activate 环境名
例如:conda activate pytorch1.5

- 退出环境
conda deactivate
- 对虚拟环境中安装额外的包
conda install -n your_env_name [package]
例如:conda install -n pytorch1.5 pytorch==1.5.0 torchvision==0.6.0 cudatoolkit=10.2 -c pytorch
经测试后发现,只要激活了虚拟环境后,用pip直接安装也可以,安装的包是直接在虚拟环境里面
例如:pip install torch==1.5.0 torchvision==0.6.0
- 删除环境内某个包
conda remove --name 环境名 包名
例如:conda remove --name pytorch1.5 pytorch
- 查看当前存在哪些虚拟环境
conda env list
- 查看安装了哪些包
conda list
- 检查更新当前conda
conda update conda
- 删除虚拟环境
conda remove --name oldname --all
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号,不定期分享干货
作者:数据人阿多
背景
由于业务需要频繁处理大量视频(几十GB),通过公司内网传输太慢,于是就每次处理视频时需要在服务器挂载硬盘或U盘。业务人员给的硬盘或U盘格式有时不一样,目前遇到的格式:NTFS、FAT32、exFAT,这几种格式大家在Windows上基本很常见,于是总结了这些格式的硬盘如何有效挂载到Linux服务器,分享出来供大家参考
- NTFS挂载
- FAT32挂载
- exFAT挂载
NTFS挂载
第一步:安装驱动ntfs-3g
yum install ntfs-3g
第二步:查看硬盘信息(硬盘已通过USB插入服务器)
fdisk -l
会在最后列出该硬盘的信息,一般是sdb,默认只有1个分区,下面挂载时用的是sdb1
但有的硬盘里面也有2个分区的,如下所示:
Disk identifier: 9B602E4F-E563-4A27-9510-46DEBC0BAA20
# Start End Size Type Name
1 40 409639 200M EFI System EFI System Partition
2 409640 3906961407 1.8T Microsoft basic My Passport
如果是这种情况,下面挂载时就需要用到sdb2
第三步:挂载硬盘
cd /mnt
mkdir Windows #挂载时一定要提前创建好该文件夹
mount -t ntfs-3g /dev/sdb1 /mnt/Windows
第四步:解除挂载
umount /dev/sdb1
硬盘挂载基本就以上这四步,下面主要列出其他格式硬盘挂载的重点步骤
FAT32挂载
不需要驱动,可以直接挂载
下面的挂载命令 支持 中文、挂载后不同用户可读写权限,具体参数含义可自行百度查询
第三步:挂载硬盘
mount -t vfat -o iocharset=utf8,umask=000,rw,exec /dev/sdb1 /mnt/Windows
exFAT挂载
第一步:安装驱动fuse-exfat、exfat-utils
yum install fuse-exfat
yum install exfat-utils
第三步:挂载硬盘
mount /dev/sdb2 /mnt/Windows
总结
- 有的格式需要安装驱动,有的不需要
- 硬盘里面具体要看有几个分区,挂载时指定分区号
sdb1orsdb2
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注DataShare,不定期分享干货
作者:数据人阿多
背景
本地连接远端的服务器,SecureCRT可以说是一大利器,可以保存密码、设置自动登陆等,每次都可以一键直连服务器
最近因公司加强了服务器登陆验证,增加了二次认证,必须用Google Authenticator输入6位动态验证码,才能成功登陆,这样的话每次都得打开手机,手动输入验证码比较麻烦
在 Python 中有这样的库 pyotp 可以直接生成Google Authenticator输入6位动态验证码,前提是你知道谷歌验证码对应的密钥,一般是在最开始让扫描二维的下方会提示出来
SecureCRT支持利用一些语言脚本来实现自动登陆,比如:python、vbs,本篇文章来介绍如何利用 python 脚本自动登陆
SecureCRT版本
电脑为Win10操作系统
SecureCRT版本:Version 6.7.0 (build 153)
SecureCRT中的python版本:python2.6 (可以在安装文件里面查看到)

由于没有更新SecureCRT版本,一直用的老版本,支持的python也算是比较老了!!!
最新的SecureCRT版本是支持python3,但是需要进行一些设置,相对比较麻烦,感兴趣的话可以看看这篇文章:
《How-To: Use Python 3.8 with SecureCRT v9.0 for Windows》
https://forums.vandyke.com/showthread.php?t=14295
遇到问题
参考网上分享的一些例子,在 import pyotp 时总是会报错
《python 实现 jumpserver 自动登录》
https://mp.weixin.qq.com/s/aLazW8WUVfvsICnHXes3CA
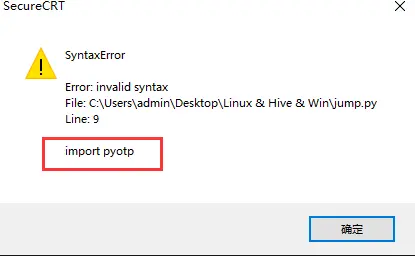
即使添加了python包路径也不行,一直报错,pyotp 是兼容python2、python3所有版本
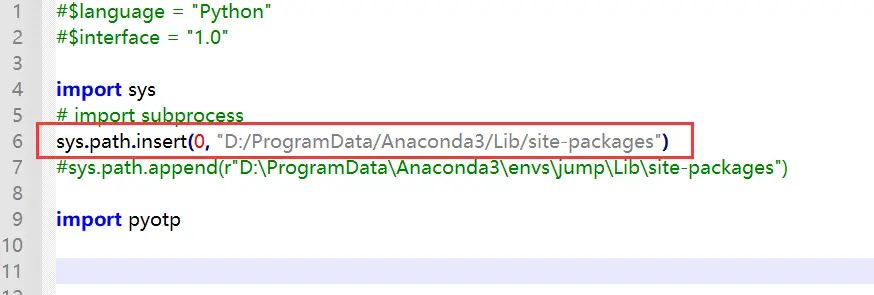
解决方法
通过提示可以看出,import sys 时并没有报错,说明python内置的包,是可以直接导入使用的,经过测试把 pyotp 源码中涉及到生成动态码的库import时,没有报错,说明已经走通了
这时就需要剖析 pyotp 源码,有哪些是生成生成动态码必须的,把冗余的代码全部剔除即可,经过分析也就是两个类有用,如下所示:
class OTP(object):
def __init__(self, s, digits=6, digest= hashlib.sha1, name= None,issuer= None):
self.digits = digits
self.digest = digest
self.secret = s
self.name = name or 'Secret'
self.issuer = issuer
def generate_otp(self, input):
if input < 0:
raise ValueError('input must be positive integer')
hasher = hmac.new(self.byte_secret(), self.int_to_bytestring(input), self.digest)
hmac_hash = bytearray(hasher.digest())
offset = hmac_hash[-1] & 0xf
code = ((hmac_hash[offset] & 0x7f) << 24 |
(hmac_hash[offset + 1] & 0xff) << 16 |
(hmac_hash[offset + 2] & 0xff) << 8 |
(hmac_hash[offset + 3] & 0xff))
str_code = str(code % 10 ** self.digits)
while len(str_code) < self.digits:
str_code = '0' + str_code
return str_code
def byte_secret(self):
secret = self.secret
missing_padding = len(secret) % 8
if missing_padding != 0:
secret += '=' * (8 - missing_padding)
return base64.b32decode(secret, casefold=True)
@staticmethod
def int_to_bytestring(i, padding= 8):
result = bytearray()
while i != 0:
result.append(i & 0xFF)
i >>= 8
# It's necessary to convert the final result from bytearray to bytes
# because the hmac functions in python 2.6 and 3.3 don't work with
# bytearray
return bytes(bytearray(reversed(result)).rjust(padding, b'\0'))
class TOTP(OTP):
def __init__(self, s, digits= 6, digest=hashlib.sha1, name=None,issuer=None, interval= 30):
self.interval = interval
super(TOTP,self).__init__(s=s, digits=digits, digest=digest, name=name, issuer=issuer)
def now(self):
return self.generate_otp(self.timecode(datetime.datetime.now()))
def timecode(self, for_time):
if for_time.tzinfo:
return int(calendar.timegm(for_time.utctimetuple()) / self.interval)
else:
return int(time.mktime(for_time.timetuple()) / self.interval)
完整代码
以下为SecureCRT利用Python脚本自动登陆服务器的完整代码:
# $language = "Python"
# $interface = "1.0"
import calendar
import datetime
import hashlib
import time
import base64
import hmac
class OTP(object):
def __init__(self, s, digits=6, digest= hashlib.sha1, name= None,issuer= None):
self.digits = digits
self.digest = digest
self.secret = s
self.name = name or 'Secret'
self.issuer = issuer
def generate_otp(self, input):
if input < 0:
raise ValueError('input must be positive integer')
hasher = hmac.new(self.byte_secret(), self.int_to_bytestring(input), self.digest)
hmac_hash = bytearray(hasher.digest())
offset = hmac_hash[-1] & 0xf
code = ((hmac_hash[offset] & 0x7f) << 24 |
(hmac_hash[offset + 1] & 0xff) << 16 |
(hmac_hash[offset + 2] & 0xff) << 8 |
(hmac_hash[offset + 3] & 0xff))
str_code = str(code % 10 ** self.digits)
while len(str_code) < self.digits:
str_code = '0' + str_code
return str_code
def byte_secret(self):
secret = self.secret
missing_padding = len(secret) % 8
if missing_padding != 0:
secret += '=' * (8 - missing_padding)
return base64.b32decode(secret, casefold=True)
@staticmethod
def int_to_bytestring(i, padding= 8):
result = bytearray()
while i != 0:
result.append(i & 0xFF)
i >>= 8
# It's necessary to convert the final result from bytearray to bytes
# because the hmac functions in python 2.6 and 3.3 don't work with
# bytearray
return bytes(bytearray(reversed(result)).rjust(padding, b'\0'))
class TOTP(OTP):
def __init__(self, s, digits= 6, digest=hashlib.sha1, name=None,issuer=None, interval= 30):
self.interval = interval
super(TOTP,self).__init__(s=s, digits=digits, digest=digest, name=name, issuer=issuer)
def now(self):
return self.generate_otp(self.timecode(datetime.datetime.now()))
def timecode(self, for_time):
if for_time.tzinfo:
return int(calendar.timegm(for_time.utctimetuple()) / self.interval)
else:
return int(time.mktime(for_time.timetuple()) / self.interval)
username='aaa'
password='aaa'
google_author_secret_key='自己的密钥'
def Main():
tab = crt.GetScriptTab()
if tab.Session.Connected != True:
crt.Dialog.MessageBox("Session Not Connected")
return
tab.Screen.Synchronous = True
tab.Screen.WaitForStrings(['Password: '])
tab.Screen.Send(password+'\r\n')
tab.Screen.WaitForStrings(['Please enter 6 digits.[MFA auth]: '])
vc = TOTP(google_author_secret_key).now()
tab.Screen.Send("{vc}\r\n".format(vc=vc))
return
Main()
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
也许你有这样的疑问,数据分析师为什么要了解Linux?这不是开发人员应该了解的吗?把Windows+SQL+Excel+Python玩的精通,不香吗?
以上的疑问也许处有人会提出,但随着个人的职业成长,企业数字化的发展,终究会与Linux系统打交道,比如:在数据挖掘时,大量的数据需要做分析、特征提取,然后跑模型,这些任务在个人的Windows系统基本完全做不了,只能在Linux服务器上来完成
备注:在大厂就职的同学 and 公司基建做的非常好的,可以忽略本文,说明你们公司比本小编曾经就职的某手好点,当然多学习一些知识,对自己百利而无一害,活到老学到老
以下介绍的命令是基于: Centos系统,Linux的一个发行版
常用命令
pwd
当前所处的文件夹位置
ls
列出当前文件夹里面的文件及子文件夹
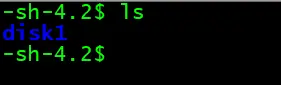
ll
该命令相当于 ls -l
展示文件夹里面的文件及子文件夹详细信息,有点类似在Windows里面查看文件夹时以详细信息方式展示一样
cd
切换目录,换到别的文件夹
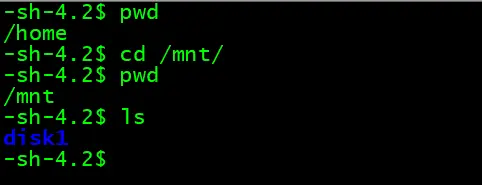
mkdir
创建一个新建文件夹
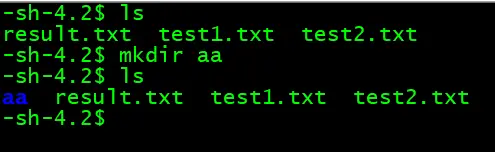
cp
cp 文件 新文件夹
复制文件到新的文件夹里面,copy的简写
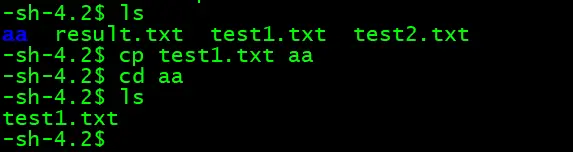
cp -r 文件夹 新文件夹
复制整个文件夹到新的文件夹里面,需要添加 -r 参数,进行递归式复制
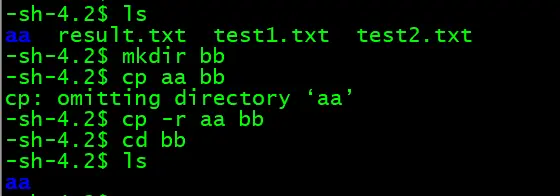
mv
mv 文件 新文件夹
移动文件到新文件夹,move 的简写
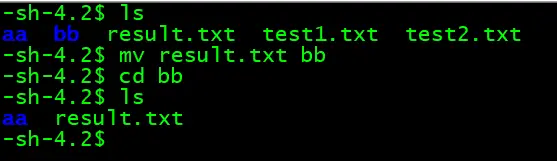
mv 文件夹 新文件夹
移动文件夹到新文件夹
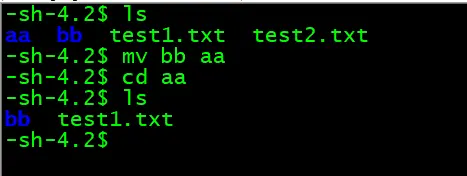
cat
cat 文件名
展示文件里面的内容
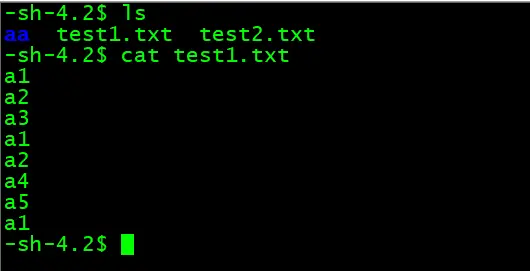
sort
sort 文件名
对文件里面的行进行排序
sort -u 文件名
对文件里面的行进行去重并且排序,-u 是 unique 的简写
head
显示文件的前几行内容,在默认情况下,head命令显示文件的头10行内容,-n 参数可以指定要显示的行数
tail
显示文件的后几行内容,在默认情况下,tail显示最后 10 行,-n 参数可以指定要显示的行数
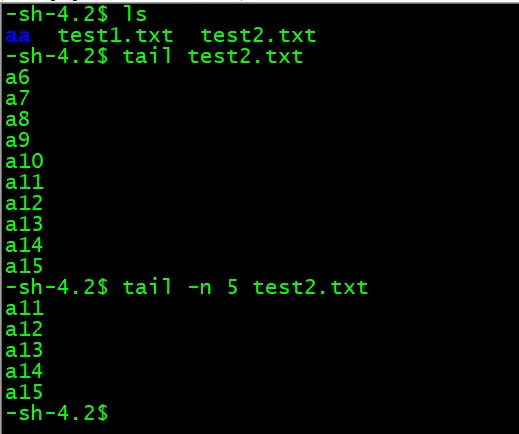
top
实时动态显示各进程的情况,可以按 M与T 进行可视化变化,可以显示为进度条样式
df -h
显示目前在 Linux 系统上的文件系统使用情况统计磁盘,-h 参数代表使用人类可读的格式 human-readable,是human的简写
ps -ef
查看服务器上所有运行的进程,类似Windows的查看任务管理器,PID 代表进程号
kill -9 进程号
强制杀死进程,类似Windows的在任务管理器中结束某个进程任务,用上面的 ps 命令查出进程号后,可以直接强制退出该进程
rm
删除文件或者文件夹,谨慎使用,删除掉就不容易恢复,不像Windows在回收站可以找回
rm 文件名
删除文件
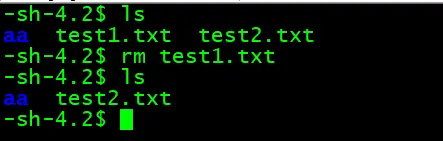
rm -r 文件夹
删除文夹,-r 参数为递归删除文件夹及子文件夹里面的文件
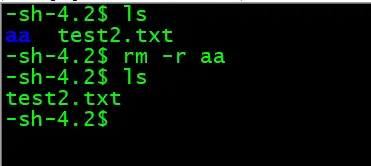
好用的学习网站
以上介绍的只是几个常用的命令,下面列出几个网站,个人感觉这几个比较好用,供大家可参考学习
- https://man.linuxde.net/
- http://c.biancheng.net/linux_tutorial/
- https://www.runoob.com/linux/linux-tutorial.html
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
小编在刚开始学习Python时,是在Python官网下载的原生版本,用的是自带的编码环境,后来了解到在数据分析、数据科学领域用Jupyter notebook比较好,于是直到现在也是一直在用Jupyter notebook,也偶尔用PyCharm做开发。在数据分析与处理中Jupyter notebook还是很方便,可以直接查看数据,可以写文档,可以画图 等很多优点,感觉Jupyter notebook 就是是为了数据分析、数据挖掘、机器学习而生的
如果用过Jupyter notebook,大家都知道,它是一个网页界面,服务端和客户端分离,每次启动都会在后台运行一个cmd/terminal窗口,可以理解为服务端,而使用的浏览器界面,可以理解为客户端。既然是服务端与客户端分开的,那么服务端就可以部署到服务器上,可以充分利用服务器的计算资源、存储资源,更甚者可以用GPU资源。其实在服务器部署Jupyter notebook,做机器学习的同学,应该对这个很熟悉,但是不一定亲手部署过

浏览器-客户端

cmd-服务端
必要前提!!!
需要对Linux服务器要有所了解,如果在工作中压根就没使用过服务器,且不知道ssh,那小编劝你暂时先别看这篇文章,可以先去多学一些Python知识,后面随着知识的积累,慢慢的你就会接触到服务器
小编服务器环境
硬件:谷歌云虚拟机实例,1G内存,100G硬盘
系统:64位 Debian,Debian GNU/Linux 11
服务器部署流程
在服务器上安装Jupyter notebook,一共分为4步,最终实现在本地电脑来访问
因为Anaconda自带Jupyter notebook,并且可以创建虚拟环境,使用起来非常方便,所以强烈推荐使用Anaconda,可以让你少采坑
第1步:下载Anaconda
Anaconda 下载地址:https://www.anaconda.com/download#downloads
在服务器上直接下载(谷歌服务器下载很快)
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh
第2步:安装Anaconda
在服务器上直接安装Anaconda,在安装中一直点击回车或空格键,在许可条款、最后配置的地方输入 yes 即可
在安装时确保硬盘存储空间要足够,小编在安装是最开始只有10G硬盘资源,一直报错,后来扩大硬盘后解决了
安装完成后,命令行提示符前会有多了个 (base),这个是Anaconda默认的基础虚假环境,小编下载的是截止发文章时最新版Anaconda,里面集成的是 Python 3.11.5
bash Anaconda3-2023.09-0-Linux-x86_64.sh
第3步:对Jupyter notebook进行配置
- 生成配置文件,运行后会显示配置文件的存放位置
jupyter notebook --generate-config

- 对配置文件进行修改
## The IP address the notebook server will listen on.
# Default: 'localhost'
# 设置可以访问的ip, 默认是localhost, 将其改为 '*'
c.NotebookApp.ip = '*'
## The directory to use for notebooks and kernels.
# Default: ''
# 默认打开目录
c.NotebookApp.notebook_dir = '/home/data123share66/python'
## Whether to open in a browser after starting.
# The specific browser used is platform dependent and
# determined by the python standard library `webbrowser`
# module, unless it is overridden using the --browser
# (NotebookApp.browser) configuration option.
# Default: True
# Jupyter notebook启动后是否打开浏览器, 设为 False 即可
c.NotebookApp.open_browser = False
## Hashed password to use for web authentication.
#
# To generate, type in a python/IPython shell:
#
# from notebook.auth import passwd; passwd()
#
# The string should be of the form type:salt:hashed-
# password.
# Default: ''
c.NotebookApp.password = 'argon2:$argon2id$v=19$m=10240,t=10,p=8$Ny6WDdoLBm88cUMyOqgNqg$s3WObP81eU51RT2j8D8DULPM1OAPOnzYfODW8olB0xw'
小编这里在生成密码是用的 datashare ,在输入时屏幕不会显示
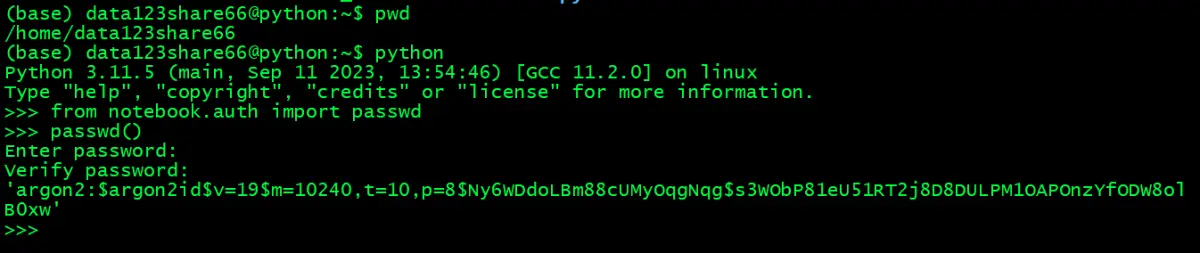
第4步:启动Jupyter notebook,并在本地电脑远程访问
- 1、服务器启动Jupyter notebook
jupyter notebook --ip=0.0.0.0 --port=9999
- 2、在本地电脑浏览器远程访问
在浏览器输入服务器的IP地址:9999,小编这里是
34.81.173.39:9999,访问后,会出现如下页面
然后输入密码 datashare 进行登录,成功登录后界面如下所示:
- 3、创建一个notebook,查看python版本
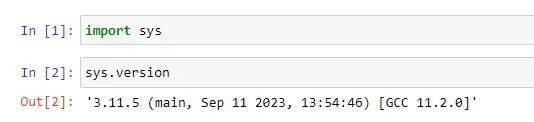
Jupyter 好用的扩展插件
- 1、安装jupyter_contrib_nbextensions 该插件会扩展jupyter的很多功能,如目录,自动补全等,在服务器终端依次运行如下命令
pip install jupyter_contrib_nbextensions
jupyter-contrib-nbextension install --user
打开jupyter会发现多了一个菜单栏 Nbextension
 对Nbextension进行配置,勾选需要的功能
对Nbextension进行配置,勾选需要的功能

- 2、安装nb_conda
conda install nb_conda
安装完成后,需要在服务器重新启动一下Jupyter notebook,会发现多了一个菜单栏 Conda
 在服务器创建一个虚拟环境 python312,然后刷新一下页面,就可以看到虚拟环境 python312
在服务器创建一个虚拟环境 python312,然后刷新一下页面,就可以看到虚拟环境 python312
conda create -n python312 python=3.12
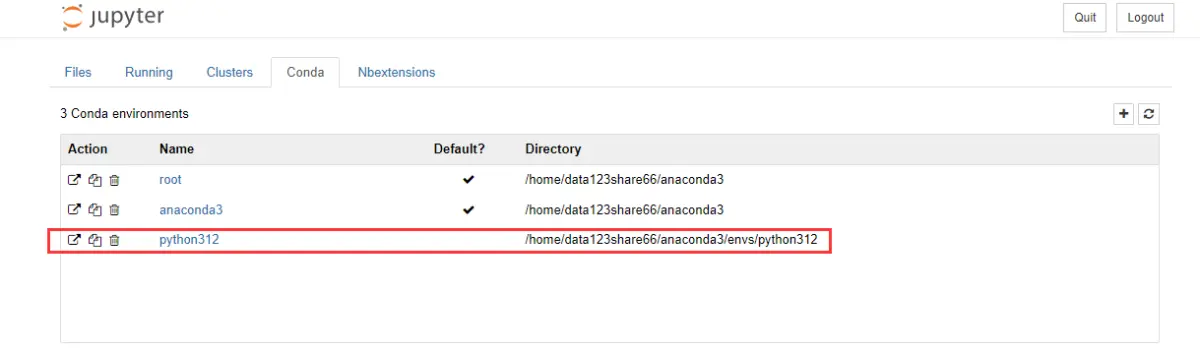
多个Python版本kernel配置
虽然上面已经创建了虚拟环境,并显示出来了,但是在创建新的notebook时并显示python312,因为python312存在不同的虚拟环境里面,这个需要我们再进行配置
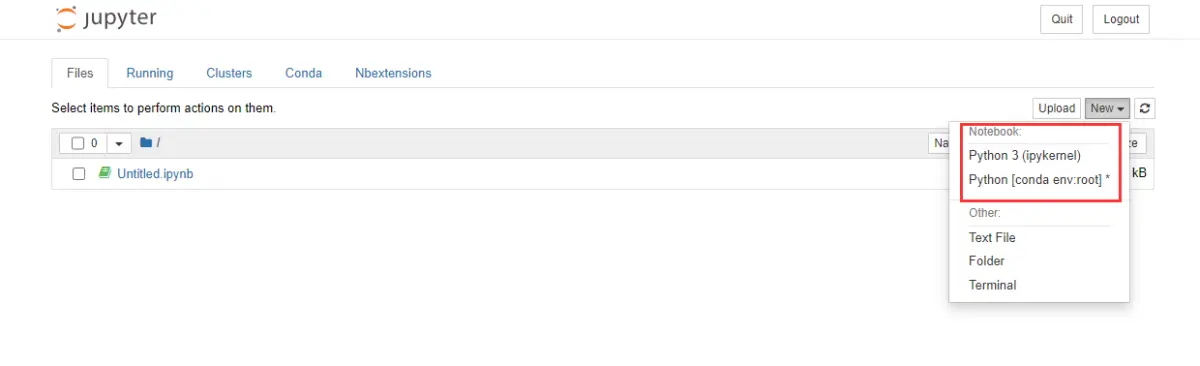
Jupyter Notebook允许用户在同一个notebook中使用多个不同的IPython内核
- 1、安装Jupyter Notebook和IPython内核
conda create -n python312 python=3.12 #上面安装过的可以忽略
conda activate python312
pip install jupyter
pip install ipykernel
pip install ipywidgets
- 2、安装新的kernel内核
conda activate python312 #切换虚拟环境
ipython kernel install --name "python312" --user
- 3、服务器端重新启动Jupyter notebook
建一个python312内核的notebook,查看当前内核的python解释器版本
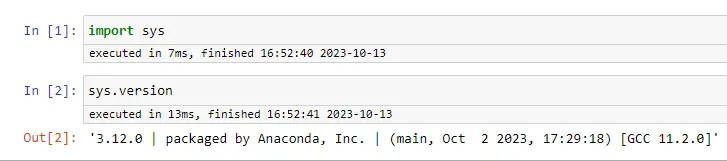
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
离线数据经过 hive 处理后,生成的新数据,有时需要对接至研发侧 clikehouse,供前端用户查询使用,所以会涉及到hive数据同步至clikehouse,因为hive数据底层是存储在 hdfs ,因此只要知道hive的建表语句(元数据),再结合 clikehouse 中的特定表引擎(本质是表映射),即可实现 clikehouse 直接读取hdfs数据
小编环境
操作系统版本 与 Clickhouse 版本
cat /etc/redhat-release
# CentOS Linux release 7.2.1511 (Core)
clickhouse -V
#ClickHouse local version 24.7.2.13 (official build)
hive中建表并插入测试数据
设置字段分割符为 \t
--建表语句
create table test_bigdata.test_hdfs_ck (
uid string comment '用户id',
name string comment '姓名',
age bigint comment '年龄',
dt string comment '注册日期'
)
row format delimited fields terminated by '\t'
stored as textfile
;
--插入数据
insert into table test_bigdata.test_hdfs_ck
values
('uid1','张三','18','20250101'),
('uid2','john','28','20250317'),
('uid3','deepseek','10','20250315')
;
在clikehouse中创建HDFS映射表
前提:需要打通不同服务器之间的网络策略 利用 clikehouse 中的 HDFS 表引擎,指定 hdfs 的路径、hive中表的存储格式,即可创建映射表
--创建HDFS映射表
create table test.test_hdfs_ck (
uid String comment '用户id',
name String comment '姓名',
age UInt16 comment '年龄',
dt Date comment '注册日期'
)
ENGINE = HDFS('hdfs://10.20.1.1:8020/user/hive/warehouse/test_bigdata.db/test_hdfs_ck/*', 'TSV')
;
在clikehouse中创建本地表,并导入数据
用户在查询数据时,需要实时返回,有时效性要求,所以需要把hdfs的映射表数据导入本地表中
--创建本地表
create table test.test_ck (
uid String comment '用户id',
name String comment '姓名',
age UInt16 comment '年龄',
dt Date comment '注册日期'
)
ENGINE=MergeTree
PARTITION BY dt
ORDER BY uid
;
--把映射表数据导入本地表
insert into test.test_ck
select *
from test.test_hdfs_ck
;
注意事项
- 低版本 clickhouse 不支持创建该表类型引擎
- 需要有权限读取hdfs指定路径,默认是clikehouse用户
- 日期格式的解析,clickhouse 中默认可以直接解析
yyyy-MM-dd,但标准规范的8位数字yyyyMMdd在映射时,也可以自动解析
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
小编最近在做一个数据类产品项目,每天涉及到几十亿数据的汇总计算,从不同维度、不同的关联关系进行汇总统计,刚开始时项目组使用的是hive,写好大量的业务SQL计算逻辑后(中间有一些其他程序处理脚本),每天通过定时任务来生成数据,然后把生成的数据推送到研发端的ES(Elasticsearch),研发端基于ES查询数据,给到前端来展示
但是,随着项目的不断深入,产品需求的快速迭代,之前的各种统计指标更新迭代,基于hive数据库的计算方式不能再满足当前快速迭代的场景。项目组经过调研,最终选择Clickhouse数据库,让研发来每天通过查询Clickhouse数据库,来统计生成各种统计指标,并把结果缓存至ES
项目数据架构的大概思路:
- hive每日生成明细数据,把这些明细数据导入Clickhouse
- 在Clickhouse中生成一些中间表,供研发人员查询数据使用,方便进行各种拼接组合
- 研发人员每日基于明细表、中间表,计算统计指标,把结果缓存至ES
小编环境
操作系统版本 与 Clickhouse 版本
cat /etc/redhat-release
# CentOS Linux release 7.2.1511 (Core)
clickhouse -V
#ClickHouse local version 24.7.2.13 (official build)
登录客户端
clickhouse-client -u xxxx --password xxxxxx -m
-u 或者 --user :指定用户名 --password :密码 -m 或者 --multiline :进入客户端后,运行输入多行sql语句
建表
在Clickhouse中,数据既可以存放到单个服务器节点,也可以把数据分散存放到集群中各个节点服务器中,这个需要看数据量大小,来选择合适的表类型
- 创建本地表 如果数据量比较小的话,建议选择本地表,在数据查询时以提高性能,可以节省节点之间数据传输的时间,比如有几千万行数据的表,完全可以选择本地表,但是查询数据时,只能在当前服务器节点查询,其他服务器节点没有该表
下面以用户表为列,进行建表操作:
create table test.user_table (
uid String comment '用户id',
sex String comment '性别',
age UInt16 comment '年龄',
phone String comment '联系电话'
)
engine = MergeTree()
order by uid;
- 数据类型需要注意是大写开头 ,
String、UInt16,表引擎类型也必须大写MergeTree - 如果没有指定主键的话,默认用 order by 指定的字段
- 创建分布式表 分布式表在Clickhouse中,只是一个视图,不实际存放数据,指向实际存放数据的本地表,所以在创建分布式表时,需要在各个服务器节点创建名字一模一样的本地表
--在集群中创建实际存放数据的本地表
create table test.user_event on cluster data_cluster(
uid String comment '用户id',
event String comment '事件名称',
c_time DateTime comment '点击时间',
dt Date comment '日期'
)
engine = MergeTree()
partition by dt
order by uid;
--创建分布式表
create table test.user_event_distributed (
uid String comment '用户id',
event String comment '事件名称',
c_time DateTime comment '点击时间',
dt Date comment '日期'
)
engine = Distributed('data_cluster', 'test', 'user_event', rand())
;
分布式表需要选择 Distributed 表引擎,其中
第1个参数:集群名称
第2个参数:数据库名
第3个参数:数据表名
第3个参数:分片key,数据被到不同服务器依据的字段,相同的值会被分配到同一台服务器
如果在创建分布式表 test.user_event_distributed 时没有指定 on cluster data_cluster,那么创建是本地表,后续的查询只能在建表的那个节点服务器查询数据,这里小编就创建的是一个本地表
查询
Clickhouse 的sql 查询语句和hive的比较类似,使用起来基本没啥差距,只有极个别的函数不支持,下面小编列举一下自己在使用时,遇到的个别函数:
- 没有
nvl函数,需要用coalesce代替 - 支持窗口函数,
row_number等 - 没有
concat_ws,需要用arrayStringConcat代替 - 没有
collect_list,需要用groupArray代替 - 一个好用的函数,
arrayZip,类似python中的zip - 没有
split函数,需要用splitByString代替 arrayMap、arraySum、arraySlice等函数很好用,性能高
表变更
- 删除特定分区
alter table test.user_event on cluster data_cluster drop partition '2024-11-30';
alter table test.user_event on cluster data_cluster delete where dt > '2024-11-15';
alter table test.user_event on cluster data_cluster delete where dt='2024-11-30';
- 删除满足特定条件数据
alter table test.user_event on cluster data_cluster delete where user_id='u00001';
自定义函数
不推荐使用外部语言编写自定义函数,例如:java、python 等,推荐使用自有的函数,逐步组合实现自定义函数,性能高
一个样例:
--分割字符串并把类型转换为整数
create function x_split as (x) ->
(
arrayMap(
y -> toUInt32(y),
splitByString(',', x)
)
);
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
Clickhouse 数据库最近几年在大数据领域应用越来越广,因其卓越的性能,外加支持海量数据存储与处理,国内很多大厂都有在使用。其底层使用C++语言编写,小编在使用时,感觉可以极限压榨CPU性能,计算速度远超 Hive,应用在数据产品领域,基本没啥问题
- 存储的数据量,可以与Hadoop生态持平
- 计算性能,可以与Mysql持平
小编环境
操作系统版本与Clickhouse版本
cat /etc/redhat-release
# CentOS Linux release 7.2.1511 (Core)
clickhouse -V
#ClickHouse local version 24.7.2.13 (official build)
效果展示
提供开始日期、结束日期,生成一个日期序列,返回的是一个数组
select generateSeries_dt('2024-12-01','2024-12-07') as dts;
--['2024-12-01','2024-12-02','2024-12-03','2024-12-04',
--'2024-12-05','2024-12-06','2024-12-07']
生成日期序列自定义函数
因Clickhouse 是用C++语言编写,如果想扩展自定义函数,需要用C++来实现或借助sql方式实现,如果想使用其他语言,则只能进行桥接(把数据输出至系统,在系统中调用其他语言处理数据,然后把系统中输出的结果,拿回到clickhouse)。这里小编借助sql 方式来实现,感觉实现起来和编写python很像
利用Chatgpt的帮助,可以一步一步完成所需要的函数功能
create function generateSeries_dt as (start_dt,end_dt) ->
(
arrayMap(
x -> toDate(start_dt) + x,
range(toUInt32(toDate(end_dt) - toDate(start_dt)) + 1)
)
);
- 将字符串 start_dt 和 end_dt 转换为 Date 类型:
toDate(start_dt)和toDate(end_dt) - 计算日期之间的差值:
toDate(end_dt) - toDate(start_dt),结果是天数 - 使用 range 函数生成从 0 到差值的整数序列:
range(toUInt32(...) + 1) - 使用 arrayMap 遍历序列,将每个整数加到起始日期上,生成完整的日期序列
通过上面的详细解释,感觉是不是和python很像,经过测试,其性能大概是java编写的自定义函数性能100倍
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
标准差这个指标在平时使用比较多,主要是用来计算数据的离散程度,在Excel中有相关的函数,可以直接来计算,其他的编程语言里面也有相关的函数。
Excel中提供了2个函数 stdev.S 和 stdev.P ,都可以用来计算标准差,但这两者应该如何合理使用呢?又有什么区别呢?本篇文章将对这两个函数进行详细的讲解
stdev.S和stdev.P区别
1、先看微软文档给出的解释


2、源自网络文章的理解 当你只知道一小部分样本,想要通过其 【估算】 这部分 【样本代表的总体】 的 【标准差】 ——选择stdev.S(2010版之后叫stdev.S,老版叫stdev。这个S就是sample,样本的意思)
当你拿到的数据已经是 整体数据 了,想要计算这部分数据精确的标准差——选择stdev.P(2010版之后叫stdev.P,老版叫stdevP。这个P我猜是population,在统计学上有“总体”之意)
3、公式对比 stdev.S 计算公式: $$\sqrt{\frac{\sum(x-\overline{x})^2}{n-1}}$$
stdev.P 计算公式: $$\sqrt{\frac{\sum(x-\overline{x})^2}{n}}$$
从计算公式可以看出,唯一的区别就是根号中的分母不一样,这个涉及到自由度的概念(理解起来比较复杂),我们可以直接硬记住这个公式即可
4、总结
- 数据是抽取的样本时用stdev.S 【其他编程语言中用的是这个】
- 数据是全量时用stdev.P
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
在Excel里面数据去重方法比较多,目前用的比较多的有:
1. 数据--筛选---高级筛选
2. 数据透视表
但以上这两种方法都有局限性,比如需要去重的区域是多列数据
下面介绍一种通过VBA编写宏程序来进行数据去重,可以去重多列数据
先把代码呈现出来,再进行解释:
Sub 字典方法()
Dim rng As Range '定义一个区域,用于接收需要去重的单元格区域
Set rng = Application.InputBox("请指定去重区域", "数据源区域", , , , , , 8) '可以是一列,也可以是多列
If rng Is Nothing Then End '如果没有选择区域,则退出,注:是End,不是End IF
Dim arr '定义一个数组,用于存储去重区域的值
arr = rng.value
Dim a
On Error Resume Next '这里需要忽略错误,后面添加重复键值会引发错误
Dim dic As Object
Set dic = CreateObject("scripting.dictionary") '引用字典对象
For Each a In arr
If Len(a) > 0 Then
dic.Add CStr(a), "" '往字典里面添加键值
End If
Next a
Err.Clear
Set rng = Application.InputBox("请指定结果存放区域,单个单元格即可", "存放区域", , , , , , 8)
If Err <> 0 Then End
rng(1).Resize(dic.Count, 1) = WorksheetFunction.Transpose(dic.Keys) '往单元格里面写入去重后的数据
End Sub
这里主要运用的字典的键值唯一性,如果向字典里面添加已经存在的键,则会引发错误,所以中间部分需要忽略错误
数组+字典在VBA里面可以提升程序运行效率,如想提升VBA程序运行效率,可多运用数组、字典
作者:数据人阿多
背景
如今,大家在遇到问题时,都已经学会了先去deepseek一下,然后得到自己需要的答案,这充分体现了大模型在信息检索领域的强大应用。然而,这仅仅是大模型潜力的一个方面。随着大模型技术的持续深化与普及,其影响力必将进一步渗透至各行各业。
近期,谷歌开源的 gemini-cli 工具,无疑为开发者社区带来了显著利好,
经过小编试用,感觉大模型在编程应用方面,又迈上了一个新台阶
小编环境
系统:Win10 系统
网络:魔法上网工具
俄罗斯方块效果
安装大概流程
开启魔法上网:。。。。。。
官方安装教程:https://github.com/google-gemini/gemini-cli
获取api key:https://aistudio.google.com/apikey
注意点:
- 在使用gemini时,魔法上网需要开启
Tun模式 - 获取的key,添加到系统环境变量,在登录认证时选择api 认证方式
开发俄罗斯方块
在桌面新建一个 Test文件夹,在该文件夹中打开终端,输入 gemini 命令后,然后选择编码风格和认证方式登录后,进入gemini,在提示框中输入相应的需求话术
发送需求后,等待gemini回答,并自行创建文件,这里会创建3个文件,index.html,style.css,script.js
完成之后,会提示怎么进行操作
在文件夹中,打开index.html 即可看到俄罗斯方块界面
整体使用起来比较顺畅,类似端到端的感觉,gemini直接把文件创建好,让你运行即可
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
背景
经过一段使用DeepSeek后,感觉使用体验和ChatGPT基本差不多,问答问题的质量略有提升,因DeepSeek已开源,它的模型、模型权重参数从网上都可以下载到,所以可以基于开源的模型,在本地构建一个自己的知识库,小编这里使用的是蒸馏后的模型权重 deepseek-r1:1.5b
RAG (Retrieval-Augmented Generation)检索增强生成,是一种通过整合外部知识库来增强大模型(LLM)回答问题质量的模式。最简单的理解,可以认为是给大模型外挂了一个知识库。
很多大模型的问题,多数是由于数据缺失造成的,企业中解决这类数据确实的问题,通常的方案是采取企业向量知识库的方式,在应用Prompt的时候,先从企业知识库中检索与Prompt关联的知识,然后把领域知识和原始Prompt整合在一起,最后作为大模型的输入。
这样大模型就了解了领域专业知识,也能更好的回答问题。
小编环境
基于Win10中的Linux子系统进行部署安装 子系统:Ubuntu 22.04.5 LTS
python -V
# Python 3.11.11
uname -a
# Linux DESKTOP-KREEAFH 5.15.167.4-microsoft-standard-WSL2 #1
# SMP Tue Nov 5 00:21:55 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux
lsb_release -a
# No LSB modules are available.
# Distributor ID: Ubuntu
# Description: Ubuntu 22.04.5 LTS
# Release: 22.04
# Codename: jammy
安装Ollama,并下载deepseek模型
官网地址:https://ollama.com/download
官网命令:curl -fsSL https://ollama.com/install.sh | sh
因该网站是国外服务器,所以都懂得,按官网命令进行安装,基本都不会成功,所有需要魔改安装脚本 install.sh
1. 在Linux下载 install.sh 安装脚本文件到本地
curl -fsSL https://ollama.com/install.sh -o install.sh
2. 修改安装脚本文件,需要开启魔法上网 在83行增加curl命令的代理参数,前面ip地址为Win10的网络地址,端口需要查看自己本地魔法上网的软件端口,小编使用的是 v2rayN,因为是Linux子系统中使用,需要使用局域网的http端口
curl --fail --show-error --location --progress-bar \
--proxy http://192.168.21.121:10811 \
"https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}" | \
$SUDO tar -xzf - -C "$OLLAMA_INSTALL_DIR"

3. 开启魔法上网,执行安装脚本文件
bash install.sh
4. 下载模型参数权重文件
ollama pull deepseek-r1:1.5b
安装Python环境依赖包
新建requirements.txt 文件,需要把以下内容放入该文件
langchain
langchain-community
langchain_experimental
streamlit
pdfplumber
semantic-chunkers
open-text-embeddings
ollama
prompt-template
sentence-transformers
faiss-cpu
安装上面列出的所有三方库:
pip install -r requirements.txt
Web完整代码
app.py文件
import streamlit as st
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_community.llms import Ollama
import os
def initialize_interface():
# 定义 CSS 样式
st.markdown(
"""
<style>
.text-color {
color: grey; /* 设置字体颜色为灰色 */
font-size: 25px; /* 设置字体大小为 20px */
}
</style>
""",
unsafe_allow_html=True
)
st.markdown(
"""
<h1 style="text-align:center;">
个人本地知识库 <span class="text-color">@DeepSeek </span>
</h1>
""",
unsafe_allow_html=True
)
def load_documents(folder_path):
documents = []
for file_name in os.listdir(folder_path):
file_path = os.path.join(folder_path, file_name)
loader = TextLoader(file_path)
documents.extend(loader.load()) # 读取本地文件的內容
return documents
def create_vectorstore(documents, model_name="deepseek-r1:1.5b"):
embeddings = OllamaEmbeddings(model=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
return vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 3})
def initialize_qa_chain(retriever, model_name="deepseek-r1:1.5b"):
llm = Ollama(model=model_name)
return RetrievalQA.from_chain_type(llm, retriever=retriever)
def main():
initialize_interface() # 初始化web
documents = load_documents("data") # 加载本地文件内容
retriever = create_vectorstore(documents) # 创建RAG
qa_chain = initialize_qa_chain(retriever) # 初始化问答
query = st.text_area("请输入要搜索问题:",height=80)
if query:
response = qa_chain.run(query)
st.write("💡 回答:", response)
if __name__ == "__main__":
main()
项目文件结构
需要把个人的知识库内容放入data目录下面,目前支持text文件
启动Web程序
启动Web程序,按照提示打开浏览器,稍等几分钟后(根据个人的电脑配置),就可以提问
streamlit run ./rag/app.py
参考文章
- https://sebastian-petrus.medium.com/developing-rag-systems-with-deepseek-r1-ollama-f2f561cfda97
- https://zhuanlan.zhihu.com/p/17210266424
- https://github.com/henry3556108/rag
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多 日期:2026年3月13日
小编体验结论
- 配置有点复杂
- 太消耗 tokens
- 不同模型的使用效果有差异
下面分别就以上几点体验进行详细阐述,网上现在已经有大量的安装教程,小编这里不再赘述
小编环境
- Windows11
- WSL2 Ubuntu-24.04
- OpenClaw 官方安装,安装文档:https://docs.openclaw.ai/zh-CN/install
配置有点复杂
OpenClaw 大家可以把它当做一个 软件 或者 智能系统 使用,遇到什么问题,那大概率就是配置有问题
国内用户习惯界面UI开关按钮,进行软件控制,但OpenClaw有的配置界面配置太麻烦
配置可以从多个途径进行修改:
-
提供详细的提示词,让智能体自己去修改-----容易自己把自己修改废了
-
在 WebUI中修改配置,可以理解为管理后台-----在保存配置时,OpenClaw会备份之前的配置
-
命令行进行修改,命令有点复杂
-
直接修改配置文件-----修改完需要重启网关
小编这里是WSL2中安装的OpenClaw,对应的文件是
\\wsl.localhost\Ubuntu-24.04\home\datashare\.openclaw\openclaw.json
小编的一些配置,供大家参考:
模型配置
其中 DeepSeek 的模型,OpenClaw配置模型选项中没有,所以需要自己配置
小编体验了不同平台的模型,所以列出的模型配置有点多
"models": {
"mode": "merge",
"providers": {
"deepseek": {
"baseUrl": "https://api.deepseek.com/v1",
"apiKey": "xxx",
"api": "openai-completions",
"models": [
{
"id": "deepseek-chat",
"name": "DeepSeek Chat (V3)"
},
{
"id": "deepseek-reasoner",
"name": "DeepSeek Reasoner (R1)"
}
]
},
"bailian": {
"baseUrl": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"apiKey": "xxx",
"api": "openai-completions",
"models": [
{
"id": "qwen3.5-plus",
"name": "qwen3.5-plus",
"api": "openai-completions",
"reasoning": false,
"input": [
"text",
"image"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 1000000,
"maxTokens": 65536
},
{
"id": "qwen3-max-2026-01-23",
"name": "qwen3-max-2026-01-23",
"api": "openai-completions",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 262144,
"maxTokens": 65536
},
{
"id": "qwen3-coder-next",
"name": "qwen3-coder-next",
"api": "openai-completions",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 262144,
"maxTokens": 65536
},
{
"id": "qwen3-coder-plus",
"name": "qwen3-coder-plus",
"api": "openai-completions",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 1000000,
"maxTokens": 65536
},
{
"id": "MiniMax-M2.5",
"name": "MiniMax-M2.5",
"api": "openai-completions",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 196608,
"maxTokens": 32768
},
{
"id": "glm-5",
"name": "glm-5",
"api": "openai-completions",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 202752,
"maxTokens": 16384
},
{
"id": "glm-4.7",
"name": "glm-4.7",
"api": "openai-completions",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 202752,
"maxTokens": 16384
},
{
"id": "kimi-k2.5",
"name": "kimi-k2.5",
"api": "openai-completions",
"reasoning": false,
"input": [
"text",
"image"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 262144,
"maxTokens": 32768
}
]
},
"zai": {
"baseUrl": "https://open.bigmodel.cn/api/paas/v4",
"api": "openai-completions",
"models": [
{
"id": "glm-5",
"name": "GLM-5",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 204800,
"maxTokens": 131072
},
{
"id": "glm-4.7",
"name": "GLM-4.7",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 204800,
"maxTokens": 131072
},
{
"id": "glm-4.7-flash",
"name": "GLM-4.7 Flash",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 204800,
"maxTokens": 131072
},
{
"id": "glm-4.7-flashx",
"name": "GLM-4.7 FlashX",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 204800,
"maxTokens": 131072
}
]
}
}
}
多智能体配置
默认安装完后是一个 main 智能体,然后小编这里又添加了一个 stock 智能体,这两个智能体是分开的,后期可以各自负责处理不同 主题/领域 的内容,类似垂类的概念
"agents": {
"defaults": {
"model": {
"primary": "deepseek/deepseek-chat",
"fallbacks": [
"bailian/glm-5",
"bailian/glm-4.7",
"bailian/kimi-k2.5",
"deepseek/deepseek-reasoner",
"qwen-portal/coder-model",
"qwen-portal/vision-model",
"bailian/qwen3.5-flash",
"bailian/qwen3.5-plus",
"bailian/qwen3-max-2026-01-23",
"bailian/qwen3-coder-next",
"bailian/qwen3-coder-plus",
"bailian/MiniMax-M2.5"
]
},
"models": {
"deepseek/deepseek-chat": {
"alias": "deepseek-v3"
},
"deepseek/deepseek-reasoner": {
"alias": "deepseek-r1"
},
"qwen-portal/coder-model": {
"alias": "qwen"
},
"qwen-portal/vision-model": {},
"bailian/qwen3.5-flash": {},
"bailian/qwen3.5-plus": {},
"bailian/qwen3-max-2026-01-23": {},
"bailian/qwen3-coder-next": {},
"bailian/qwen3-coder-plus": {},
"bailian/MiniMax-M2.5": {},
"bailian/glm-5": {},
"bailian/glm-4.7": {},
"bailian/kimi-k2.5": {},
"zai/glm-4.7": {
"alias": "GLM-4.7"
},
"zai/glm-5": {
"alias": "GLM"
}
},
"workspace": "/home/datashare/.openclaw/workspace",
"compaction": {
"mode": "safeguard",
"reserveTokensFloor": 20000,
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 4000,
"prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store.",
"systemPrompt": "Session nearing compaction. Store durable memories now."
}
},
"maxConcurrent": 4,
"subagents": {
"maxConcurrent": 8
}
},
"list": [
{
"id": "main"
},
{
"id": "stock",
"name": "stock",
"workspace": "/home/datashare/.openclaw/workspace-stock",
"agentDir": "/home/datashare/.openclaw/agents/stock/agent",
"model": "deepseek/deepseek-chat"
}
]
}
消息渠道选择的是 qqbot
qqbot 注册地址:https://q.qq.com/qqbot/openclaw/login.html
"channels": {
"qqbot": {
"enabled": true,
"accounts": {
"bot1": {
"enabled": true,
"allowFrom": [
"*"
],
"appId": "xxx",
"clientSecret": "xxx"
},
"bot2": {
"enabled": true,
"allowFrom": [
"*"
],
"appId": "xxx",
"clientSecret": "xxx"
}
}
}
}
多智能体路由配置
main 智能体通过 bot1 进行通讯,stock 智能体通过 bot2 进行通讯
"bindings": [
{
"agentId": "main",
"match": {
"channel": "qqbot",
"accountId": "bot1"
}
},
{
"agentId": "stock",
"match": {
"channel": "qqbot",
"accountId": "bot2"
}
}
]
定时任务配置
定时任务配置文件:\\wsl.localhost\Ubuntu-24.04\home\datashare\.openclaw\cron\jobs.json
其中 delivery.to 的值,qqbot 有点坑,这里的值不是qqbot 的 appId ,而是在管理后台(http://127.0.0.1:18789/sessions)会话中 Key 字段下面的小字 qqbot:c2c:xxx 中的 xxx 部分,这样定时任务执行完后,可以把信息发送到 qqbot
{
"version": 1,
"jobs": [
{
"id": "d38bd60a-8b9e-467e-a3b3-5d782ccfdb93",
"agentId": "main",
"name": "test",
"enabled": true,
"deleteAfterRun": false,
"createdAtMs": 1773303832101,
"updatedAtMs": 1773306448965,
"schedule": {
"kind": "every",
"everyMs": 300000,
"anchorMs": 1773306272809
},
"sessionTarget": "isolated",
"wakeMode": "now",
"payload": {
"kind": "agentTurn",
"message": "总结今日主要的新闻,分为国内、国外主题",
"model": "deepseek-chat",
"thinking": "high"
},
"delivery": {
"mode": "announce",
"channel": "qqbot",
"to": "xxx",
"accountId": "bot1",
"bestEffort": true
},
"failureAlert": false,
"state": {
"lastRunAtMs": 1773306329473,
"lastRunStatus": "ok",
"lastStatus": "ok",
"lastDurationMs": 54914,
"lastDelivered": true,
"lastDeliveryStatus": "delivered",
"consecutiveErrors": 0
}
}
]
}
太消耗 tokens
小编是在 deepseek 充值了 10元 ,刚开始使用了一会,后来切换为智普的模型,因注册智普的账号,送了一些模型的tokens,其中700万 tokens 用了不到1天,提示没有了
小编创建的2个智能体,主要使用内容如下:
main 智能体
- 学习了小编的github博客:https://datashare-duo.github.io/datashare
- 让智能体把学习到的内容保存到记忆Memory里面,学习到的技能也保存到SKILL里面
- 考试智能体学习到的关于 pandas 的知识点
stock 智能体
- 分析了中国电信、北京文化,2个股票的技术走势,何时进行调整
- 创建定时任务用于实时跟进盘中走势
不同模型的使用效果有差异
因智普送的tokens,是低阶模型GLM-4.7,回答的股票分析数据有明显错误:
- 中国电信,2026-03-12的收盘价格不是6.05元,而是6.00元
- 北京文化,2026-03-12的收盘价格不是4.15元,而是4.17元
后来把模型切换为 DeepSeek ,再次让大模型回答,数据正确的
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多 日期:2026年3月13日
你负责想象,AI负责搬砖
如果你还认为编程是程序员的专利,需要背诵枯燥的语法、配置复杂的环境,那么这个概念可能会颠覆你的认知
2026年,科技圈最火热的词汇莫过于 Vibe Coding。这个词由OpenAI联合创始人Andrej Karpathy带火,直译过来是“氛围编程”或“感觉编程”。它描述的是一种全新的开发范式:开发者不再逐行敲击代码,而是像指挥官一样,用自然语言向AI描述需求,让AI完成从代码生成到调试部署的绝大部分工作
简单来说,过去我们是“搬砖的”,现在我们是“总建筑师”
一、什么是Vibe Coding?从“砌砖”到“点菜”
在传统的编程世界里,开发者就像建筑工人,必须一块砖一块砖地精确垒砌,任何一个分号出错,整面墙都可能倒塌
而在Vibe Coding的世界里,你更像是一位在餐厅点菜的顾客。你不需要知道厨师放了几克盐、如何颠勺,你只需要清晰地说:“我要一道鱼香肉丝,少放辣,多放葱。”AI厨师便会立刻端出一盘菜
如果尝了一口觉得淡了,你不需要自己去后厨加盐,只需要告诉AI:“再加点盐。”它便会自动调整配方(代码)。至于那盘菜(软件)背后的几千行代码长什么样?只要味道对,谁在乎呢?
这种转变,本质上是一次开发流程的重构:
| 传统编程模式 | Vibe Coding模式 |
|---|---|
| 设计 → 编码 → 测试 → 调试 | 用自然语言描述想法 → AI生成代码 → 运行测试 → 如果不对,再用自然语言告诉AI哪里错了,让它修改 → 重复直到功能实现 |
这就是Vibe Coding的核心:把“如何做”交给AI,把“想要什么”留给自己
二、Vibe Coding的工具生态:三大类别,各司其职
要实现这种“凭感觉编程”,背后需要强大的工具支持。目前市面上的工具百花齐放,但它们的定位和角色完全不同。我们可以把它们分为三大类别:
类别一:通用编码智能体 —— 你的“结对编程大师”
这一类的工具,目标非常明确:帮你写代码、改代码、理解代码库。它们是Vibe Coding的主力军,直接与代码打交道
1. Cursor:AI原生IDE的领跑者
- 定位:深度集成AI的独立集成开发环境。它把自己伪装成了一个你熟悉的编辑器(基于VS Code),但实际上,AI才是它的灵魂
- 典型用法:你像往常一样打开编辑器写代码,但可以和AI结对编程、让它帮你重构整个文件。它强大的代码库感知能力,让它能理解整个项目的上下文
- 最新动态:Cursor推出了 Composer 2 模型,具备“长周期智能体编程”能力,可以自主处理涉及数百个操作的复杂任务。它最新版本还支持多智能体并行,可以同时跑多个代理帮你干活
2. Claude Code:终端里的极简编码专家
- 定位:Anthropic官方推出的命令行工具。它的设计哲学是“用完即走”,你不需要打开庞大的IDE,在终端里就能和AI对话
- 典型用法:在项目目录下敲入
claude命令,然后说“帮我修复这个bug”或“写一个React组件”。它离你的Shell、Git和测试环境最近,能端到端地拆解需求、编写代码、执行测试并修复问题 - 独特优势:采用“分而治之”的设计哲学,通过SubAgents并行处理任务,被认为是“代理式编程”的鼻祖。随着Claude模型更新,它拥有了超长上下文和更强的自我纠错能力
类别二:平台级智能体运行时 —— 驱动一切的“操作系统”
这一类的工具,不直接帮你写代码,而是为所有AI智能体提供运行的基础设施。Codex 就是这一类的代表
Codex:AI智能体的“操作系统”
- 定位:这是OpenAI推出的底层智能体运行时平台。它不是Cursor那样的编辑器插件,也不是Claude Code那样的命令行工具,而是一个协议和平台。你可以把它理解为一个“AI智能体的操作系统”,允许外部程序(指挥台)来调用它的AI编程能力
- 它与其他工具的关系:
- Cursor、Claude Code 可以看作是运行在“Codex操作系统”上的“应用程序”。它们调用Codex提供的底层能力,来为用户提供服务
- 基于Codex的协议,开发者可以构建出各种“指挥台”。例如,独立开发者开发的 CodexMonitor,就是一个典型的“指挥台”。它没有内置文本编辑器,而是可以同时管理多个项目的Codex代理,让你在一个界面里审批AI的修改请求、查看Git Diff、管理对话
- 核心价值:Codex揭示了Vibe Coding的未来——你不再需要编辑器,你需要的是调度AI的指挥中心
类别三:自主代理框架 —— 7x24小时待命的“数字员工”
这一类的工具,目标最为宏大:不仅要帮你写代码,还要成为能自主完成各种线上任务的“人”。它与前两类有着本质的不同
OpenClaw:开源的全能数字员工
-
定位:一个开源、可私有化部署的自主代理框架。你可以把它想象成一个能24小时运行、通过聊天软件与你交互、能调用各种工具的“数字员工”
-
与前两者的区别:
- Cursor/Claude Code 是“工具”,你需要主动去用它,用完即走
- Codex 是“基础设施”,为工具提供底层能力
- OpenClaw 是“员工”,你给它安排任务,它自己规划、执行、汇报
-
典型用法:你把它部署在服务器上,给它配置好API密钥,然后在聊天软件里对它说:“盯住这个GitHub仓库,有新Issue就总结并发我邮件”或“每天早上8点汇总行业新闻发到群里”
-
关键能力:持续在线、长期记忆、多模型支持、多场景覆盖(不限于写代码,还能处理邮件、日程、文档等)
三、一张图看懂Vibe Coding工具生态
为了更直观地理解这些工具的关系,我们可以把它们放在一个清晰的框架中:
| 工具 | 核心定位 | 一句话总结它的角色 | 它与“Vibe Coding”的关系 |
|---|---|---|---|
| Cursor | 通用编码智能体 (IDE) | 住在编辑器里的“结对编程大师” | 主力军:直接帮你写代码 |
| Claude Code | 通用编码智能体 (命令行) | 藏在终端里的“极简编码专家” | 主力军:直接帮你写代码 |
| Codex | 平台级智能体运行时 | AI智能体的“操作系统” | 基础设施:为所有工具提供底层能力 |
| OpenClaw | 自主代理框架 | 7x24小时待命的“全能数字员工” | 进化的方向:从“工具”到“同事” |
四、Vibe Coding的真相:效率背后的四大陷阱
尽管Vibe Coding看起来很美好,但业内专家指出,目前对“全民研发”的热潮仍需保持冷静。在享受效率提升的同时,我们必须正视它带来的风险:
1. 代码质量不可控
AI可能生成难以维护、性能低下或包含安全漏洞的代码。过度依赖可能导致“技术债”的快速积累。今天的“快速原型”,明天可能变成无人敢碰的“屎山”
2. 理解深度不足
长期“凭感觉编程”可能导致开发者对底层原理的理解变浅。当遇到AI无法解决的复杂问题时(比如框架底层bug、极端性能优化),可能会束手无策。你可能会发现自己变成了一个只会“喊话”的指挥官,却失去了亲自上阵的能力
3. 调试困难
当AI生成的代码出错时,理解和定位问题可能比阅读自己写的代码更困难。因为你并不完全理解它的实现逻辑。调试的过程变成了“复制错误信息给AI,让它改,再试,再错”的循环,有时比手动重写还慢
4. “垃圾进,垃圾出”
如果需求描述不清,AI生成的代码也必然不符合要求。反复沟通、反复修正的时间成本,可能会抵消效率优势。更可怕的是,AI会在你模糊的需求上“自由发挥”,生成一个看似能跑、但逻辑完全跑偏的系统
五、给Vibe Coding新手的忠告:先学基础,再凭感觉
对于想要尝试Vibe Coding的人来说,有一个重要的提醒:先学会扎实的编程基础,再去“凭感觉”
只有当你真正理解代码如何运作时,你才能准确地判断AI给出的答案是好是坏,才能真正驾驭这种强大的新范式,而不是被它“带偏”
Vibe Coding不是让你躺平,而是要求你转型。你不再是一个码农,而是一个兼具产品经理视野、架构师逻辑和测试员敏锐度的指挥官。你需要:
- 清晰地描述愿景——AI只能执行,不能替你思考
- 拆解复杂的任务——把大问题切成AI能消化的小块
- 严格地验收成果——读懂AI生成的代码,判断它是否真的符合意图
- 在AI迷茫时,指明方向——当AI陷入死循环,你需要知道问题出在哪一层
六、未来已来
Vibe Coding的出现,把创造的权力从少数技术精英手中,交还给了每一个有想法的普通人
就像现在很少有人会写汇编语言一样,未来,精通某种特定语法可能不再是核心竞争力。真正的壁垒在于想象力、批判性思维,以及驾驭AI的能力
所以,如果你有一个藏在心里很久的点子,别再因为不会写代码而搁置了。打开今天介绍的任意一款工具,试着对它说出你的第一句指令吧
毕竟,在这个时代,只要你敢想,AI就能帮你去创造
如果您觉得这篇文章有帮助,欢迎点赞、在看、转发,让更多人了解Vibe Coding的真相与未来
作者:数据人阿多 日期:2026年3月27日
不需要精通编程,只需要一份清晰的需求文档,AI就能帮你把脑海里的想法变成真实可用的产品。本文分享小编用Vibe Coding开发小程序的真实体验,从0到1,全程干货
项目缘起:为什么想做这样一个小程序?
现代人的生活节奏越来越快,忙碌之余,我们常常忽略了对自己情绪的关照。做一个记录情绪的工具,这个想法在小编心里酝酿了很久
于是,Feeling Log(心情打卡)小程序 应运而生。它不只是一个记录工具,更是一个帮助你觉察情绪、理解自己的温暖伙伴
核心功能一览:
- 📝 每日心情打卡:选择Emoji,配上简短的文字记录,每天几秒钟留存情绪瞬间。记录可公开,也可仅自己可见
- 🌟 心情广场:看看别人今天的心情如何,点赞、互动,在共鸣中感受“你并不孤单”
- 📊 数据统计:近一年的心情分布一目了然,帮你看见情绪的起伏变化,更了解自己
- 👥 轻社交互动:关注有趣的人,接收点赞与评论通知,构建一个温暖而不打扰的小圈子
开发方式: AI辅助编程(Vibe Coding)
开发工具: QClaw
先看效果:小程序长这样
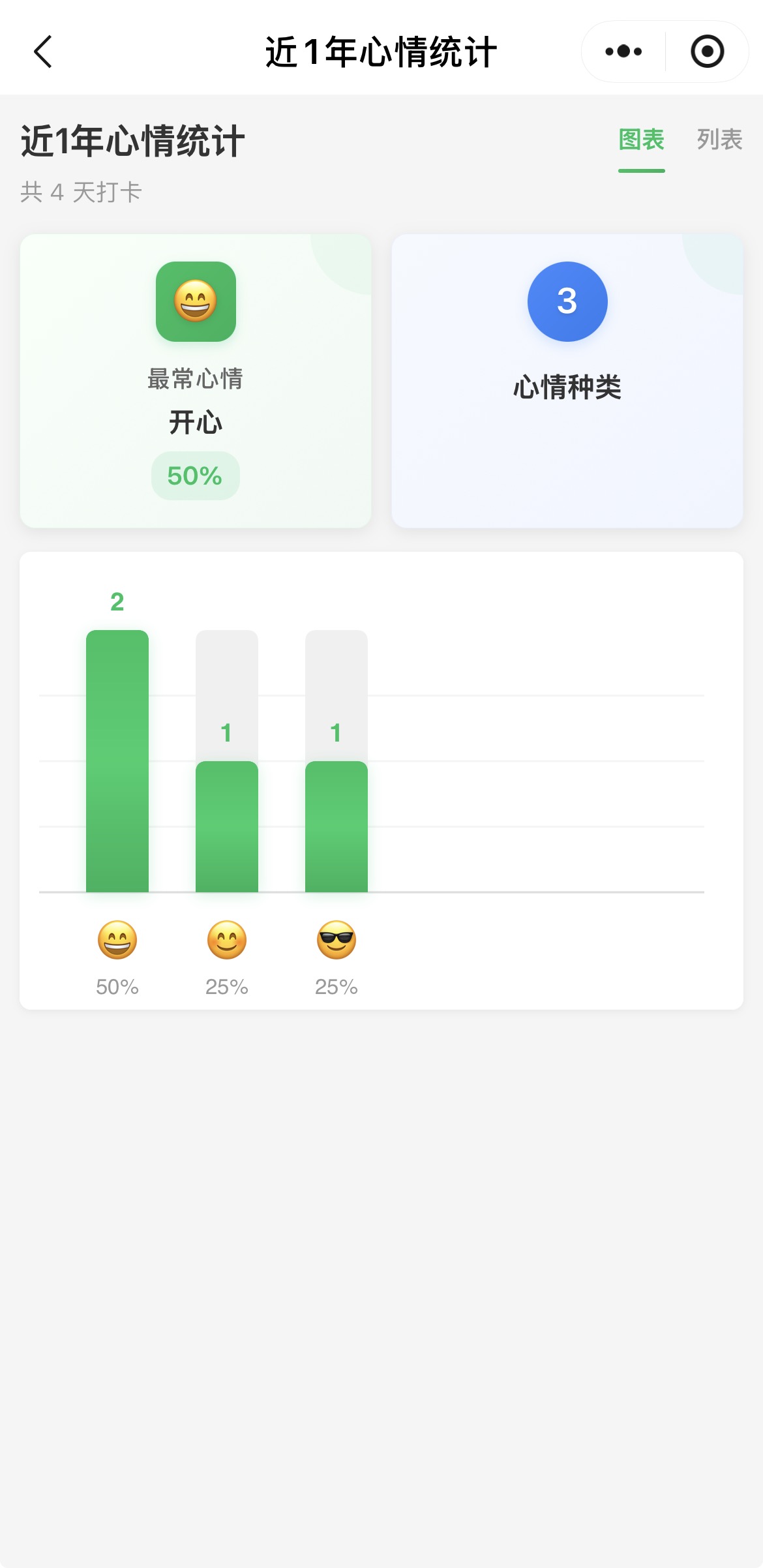
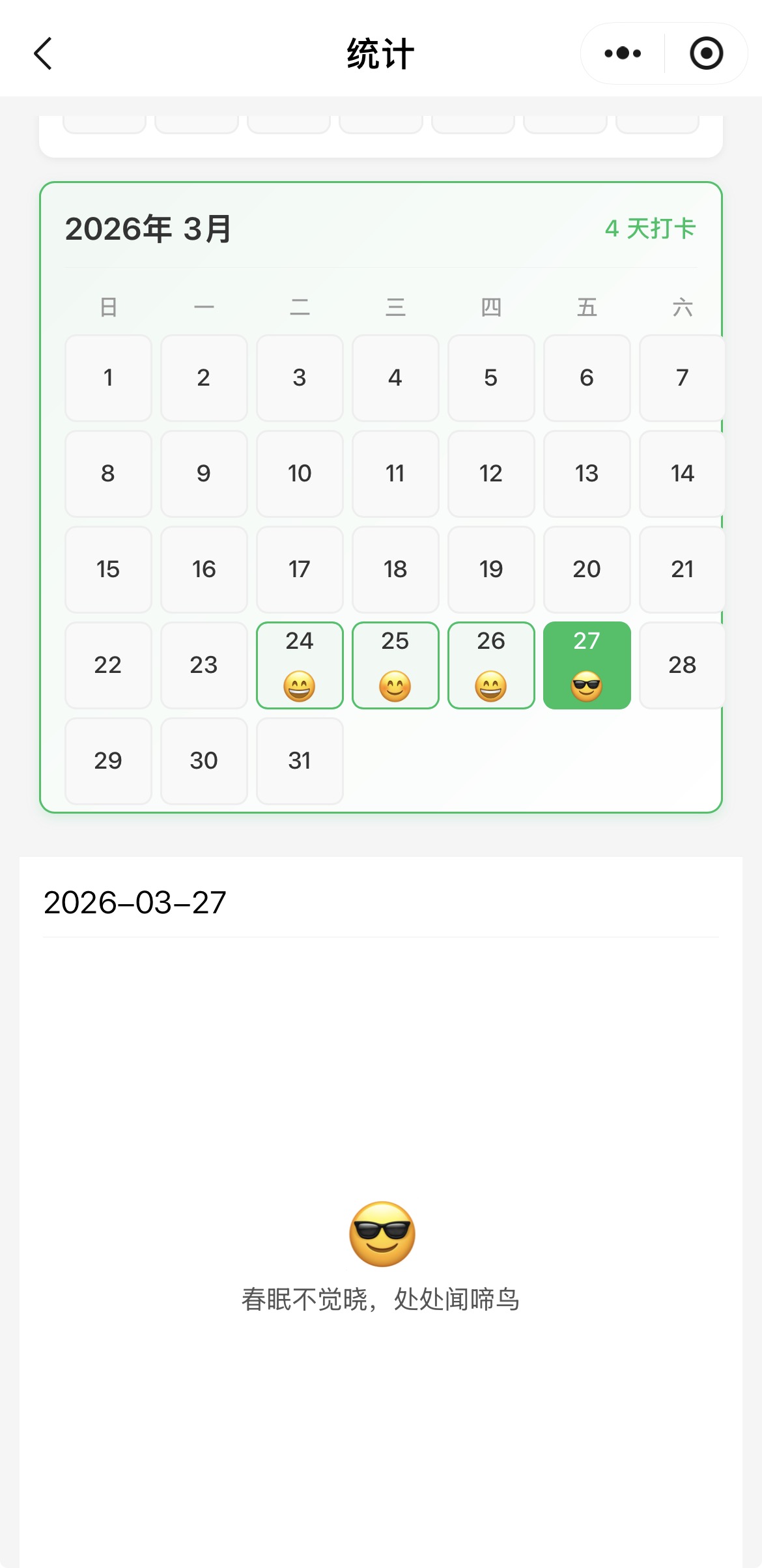
Vibe Coding是什么?颠覆传统的开发新范式
1. 传统开发 vs Vibe Coding
传统开发流程:
需求分析 → 技术选型 → 架构设计 → 编码实现 →
调试修复 → 性能优化 → 测试上线
每一个环节都需要专业技能,周期长,门槛高
Vibe Coding流程:
需求文档反复打磨 → 与AI详细沟通需求 → AI生成代码 → 验证测试 → 完成
你只需要说清楚“要什么”,AI负责解决“怎么实现”
2. Vibe Coding的核心特点
1️⃣ 需求驱动
你不是在写代码,而是在“描述产品”。你负责想清楚做什么,AI负责技术实现。
2️⃣ 对话式开发
全程以对话的方式推进。遇到问题,直接描述给AI,AI帮你分析、修复,像有一个全栈工程师随时待命。
3️⃣ 快速迭代
需求有变更?告诉AI,立即调整。发现Bug?描述现象,AI快速修复。试错成本极低,想法能更快落地
开发流程:分“两步走”实战策略
第一步:打磨需求文档——让AI当评审员
这一步至关重要。需求文档写得越清晰、越细致,AI生成的代码质量就越高,返工就越少
我的做法是:先把自己想到的功能需求写下来,然后扔给AI,让它以“评审员”的身份挑问题、提建议。根据AI的反馈反复优化、补充细节
就这样,需求文档从最初的100多字,一路细化到了1000多字,这1000字,就是后面顺利开发的基石
第二步:开发与迭代:让AI当全栈工程师
需求文档确定后,我把文档交给QClaw,它自动完成了:
- 项目结构创建
- 所有前端页面和功能实现
- 编写云函数
而我需要做的,只剩下:
- 在开发者工具中编译运行
- 测试功能是否符合预期
- 发现问题后,直接告诉AI
- 配置云开发环境
整个过程,我从 “写代码的人” 变成了 “提需求的人”和“验收产品的人”
开发中遇到的问题
🔁 1. 需求不清晰,反复修改
前端UI的布局和样式描述不够具体,导致反复调整了好几版
反而是后端接口,因为逻辑清晰,AI实现得非常顺畅,基本没怎么返工
经验: 对UI的描述要尽量详细
🗣️ 2. 同一个意思,换个词效果天差地别
在实现“用户必须先登录才能进入小程序”这个功能时,一开始怎么跟AI沟通都无法彻底解决,总是会自动登录
后来我把提示词从“用户需要登录”改成了 “必须强制用户登录” ,仅仅加了“强制”两个字,AI就准确理解并修复了这个问题
经验: 跟AI沟通时,用词要准确、坚决,避免模糊表达
🤖 3. 切换模型,解决疑难Bug
QClaw默认的大模型,解决BUG时有时不够深入,切换为DeepSeek后便能解决
💸 4. QClaw的每日4000万免费tokens不够用
随着功能的增加,会把之前已经做好的功能给修改错了,导致反复修改,从而tokens消耗很快
写在最后
Vibe Coding确实让“从想法到产品”的路径变得更短、更平了。AI是强大的助手,但它不是万能的
几点真心建议:
-
需求文档是成功的关键——花时间打磨它,值得
-
理解比使用更重要——懂一点技术原理,能让你更好地驾驭AI
-
沟通要精准——用词模糊,AI就会“自由发挥”。人与人之间沟通尚且容易误解,何况是与一个生成随机结果的AI对话
-
适时切换模型——让不同的AI发挥各自的优势
如果你也有一个酝酿已久的产品想法,不妨试试Vibe Coding。也许,你的第一个产品,就在不远处等你
历史相关文章
作者:数据人阿多
俗话说的好,磨刀不误砍柴工,对于以技术来吃饭的人来说,好用的工具、好用的网站、好用的代码、好用的方法(函数),都是技术人所必须的。
使用过Chatgpt后,大家是不是都坐不住了,甚至会赞叹到这么牛逼,但目前国内还不能用,经过各大厂商在昼夜加班制作模型后,截止当前小编就成功使用上了阿里的通义千问,百度的申请已不知道提了有多久,目前还没通过
撇开大模型这个工具之外,平时使用最多的也就是搜索引擎工具,但国内目前只能使用必应,(如果你平时使用的是百度,请忽略,小编感觉它是个广告器),如果有条件的话,大家也可以用谷歌,(别对小编说信息安全,看看百度的广告就知道了)
搜索引擎相对更准确是谷歌,举个不恰当的例子:从搜一个问题到找到满意的答案时间,谷歌大概需要1分钟,必应需要3分钟,百度需要1个小时,足见效率的高低了
工欲善其事必先利其器,如果你当前浏览器的默认搜索引擎还是百度,赶紧切换为必应吧
作者:数据人阿多
递推 vs 递归
递推
我们都熟知的正向思维,从前往后、从小到大、由易到难、由局部到整体 比如5的阶乘,要从小到大一个个乘起来,即 5!= 1 × 2 × 3 × 4 × 5
这种计算思维是我们从小学到初中,到高中一直培养的习惯,甚至到现在的编程算法,我们大部分人也是运用这种思维来解决问题,比如大家面试经常遇到的问题,要求编写一个斐波那契函数f(n),计算给定 n 的函数值
递归
递归属于逆向思维,需要倒过来思考问题,从大到小、由整体到局部的思维,例如上面求 5 的阶乘,先假定4!是已知的,然后再乘以 5 即可。当然,大家会问,那 4! 怎么计算呢? 很简单,采用同样的方法,3!× 4,只要计算出 3!乘以 4 即可。同样的方法,来计算 3!,直到最后的 1!,我们知道它就等于 1 。接下来,就是倒推回所有的结果,从 1!、2!一直倒推回 5!
递归的思想有两个明显的妙处:
1、只要解决当前一步的问题,就能解决全部的问题
2、复制同一个过程,就能得到结果
要把问题通过递归的细想来解决,必须满足两个前提条件:
1、每一个问题在形式上都是相同的,否则无法通过同一个过程完成不同阶段的计算(也就是必须要满足过程可复制)
2、必须确定好结束条件,否则就像 “从前有座山” 那个故事里的情节,永远无法结束
吴军老师的原话:很多人在学计算课程时非常不喜欢递归这种不直观的逆向思维,觉得像阶乘运算这种从小到大一个个相乘就可以了,何必那么复杂地倒着计算呢?原因很简单,很多问题只有倒着才能想清楚。这一关如果过不了,在计算机领域做一辈子技术也出不了师。
小编见解:递归的思维,用到的地方其实很多,比如,数据分析里面,我们正着去分析可能就不通,但我们反向去思考可能就解决了
信息编码的重要性
计算机中的所有内容都是以二进制进行编码的,比如看到的文字,在硬盘、内存、网络传输时中都是以编码形式存储的,如我们熟悉的UTF-8编码,还有最开始学计算机编程时了解的ASCII (American Standard Code for Information Interchange) 等,都是编码在计算机中的应用。信息的编码和有效表示是计算机科学和工程的基础,所以我们要理解这些基础的原理,这样有助于我们深入了解计算机。
当然,二进制编码对于人类来讲很不直观,便产生了很多便于人类辨识的等价代码,比如在MIPS处理器中,用 001000 代表加法运算,如果这样写程序几乎没有人能记住,出错也很难以检查,于是人们就将 ADD 这三个字母和 001000 这条代码对应起来。
下面以书中的案例,来更深入的向大家介绍编码的重要性,这道题 吴军老师说也是面试题,大家不妨把自己当作面试者,也一起思考下怎么来解答
案例---分割黄金问题:
泰勒是一位雇主,雇用鲍尼为自己新建的房子铺设院子里的地砖,这是一个七天工作量的活。泰勒答应一共支付一根金条作为报酬,但是鲍尼每天支付他 1/7 的工资,泰勒答应了。现在,请问你如何在金条上切两刀,保证每天正好能支付鲍尼 1/7 的工资?
(思考2分钟,再往下看)
小编看了这道题也没有想出来怎么切分,但看了答案感觉确实妙不可言,里面巧妙的运用了编码的思想,下面就给出答案
在金条的 1/7 的地方切一刀,在 3/7 的地方再切一刀,这样金条就变成了三个小金块,质量分别是 1/7、2/7、4/7 的金条质量。接下来,我们就要用1、2、4 这三个数字表示出 1 ~ 7 这七个数字,具体的表示方法如下:
1 = 1
2 = 2
3 = 2 + 1
4 = 4
5 = 4 + 1
6 = 4 + 2
7 = 4 + 2 + 1
利用上面的公式,在发工资时,泰勒第一天给鲍尼 1/7 金条质量的那一块黄金;第二天给鲍尼 2/7 的那一块,并要求对方交回先前 1/7 的那一块;第三天,再给鲍尼 1/7 的那一块,这样鲍尼就得到了 3/7 金条质量的黄金;第四天,给鲍尼 4/7 的那一块,但是要求他将之前给的那两小块金条交回;............到了第七天,把所有的黄金都给鲍尼即可。
这道题解法的关键是 1、2、4 这三个数字能够表达 1 ~ 7 的所有数字。那为什么 1、2、4可以呢?因为它们分别是二进制的 “个位数”、“十位数”、“百位数”。因为二进制只有 0、1 两个数字,所以每一个进位是 0 或者是 1 的组合,就能表示各种数字。我们不妨再用二进制把前面七个等式重写一遍就一清二楚了(二进制以 0b 开头)
1 = 0b001
2 = 0b010
3 = 0b011 = 0b010 + 0b001
4 = 0b100
5 = 0b101 = 0b100 + 0b001
6 = 0b110 = 0b100 + 0b010
7 = 0b111 = 0b100 + 0b010 + 0b001
通过这道案例题,大家是不是对编码有了更进一步的了解,原来编码这么重要,其实大家在编程时可能已经运用过,只是没有深入思考而已,以下摘自微软开发者文档,文件的操作:
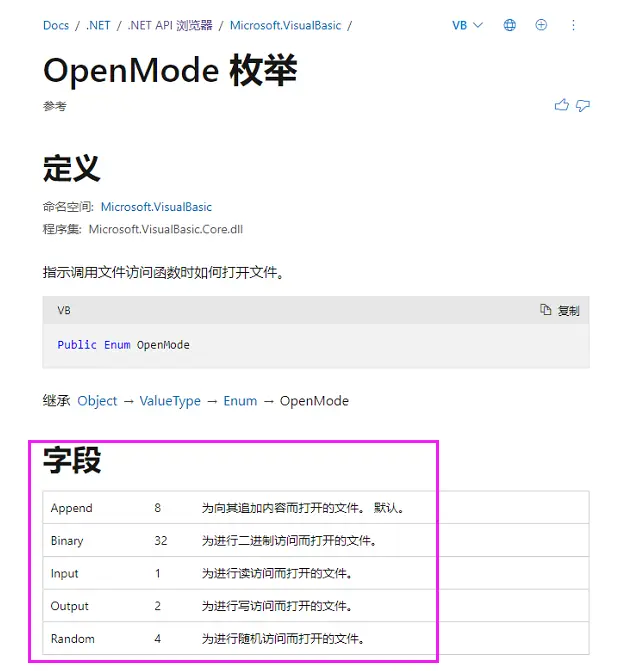
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
去年春节过后,ChatGPT成为了科技领域的热议话题,而今年过完年后,DeepSeek同样火爆异常,引发了广泛的讨论。随着大量文章的涌现,DeepSeek的功能和潜力成为了焦点。在这一波技术革新的浪潮中,这里小编也评论一下哪些行业和职业将会受到影响?
DeepSeek类工具:集各种技能于一身的“专家”
1. 搜索引擎 毫无疑问,搜索引擎行业可能会受到DeepSeek的巨大冲击。无论是国内的百度,还是国外的Google,传统的搜索引擎模式似乎在面对像ChatGPT和DeepSeek这样的智能工具时,显得有些力不从心。DeepSeek等工具不仅可以提供深度的回答和专业解析,而且它们能够以更高效的方式为用户解决问题,且没有繁杂的广告和推销信息。这种“所问即得”的方式,几乎提供了最优解,而这正是传统搜索引擎难以提供的服务。如果DeepSeek与搜索引擎结合,或许会在未来形成一种无敌的组合,改变信息获取的方式。
2. 教育行业 对于国内的应试教育而言,DeepSeek这样的智能工具无疑是一个理想的“超级老师”。传统的因材施教问题,在这个平台上似乎变得不再那么重要。DeepSeek能够根据学生的个性化需求和难题,提供精准的解答和学习指导
文科类知识,它可以帮助学生深入理解文学作品的核心思想,剖析文本的细节,凝练出语言的艺术;理科类问题,它能够逐步解释解题的每一个步骤,不仅仅是给出答案,而是帮助学生深入理解解题思路
对于学生而言,DeepSeek是一个无所不知、耐心十足的学习伙伴,合理利用好DeepSeek,将起到事半功倍的效果
3. 法律行业 法律领域也将在很大程度上受到DeepSeek的影响。由于法律条文大多是固定的,普通人在面对一些基础的法律问题时,往往需要寻找专业的法律咨询
而DeepSeek作为一个智能法律助手,能够为用户提供初步的法律建议和解答,免去寻找律师的繁琐流程。在一些简单的法律事务中,DeepSeek能够提供准确的解决方案,帮助用户快速了解自己在法律上的权利与义务,甚至在某些情况下,能够有效降低法律咨询的成本
4. 医疗行业 医疗领域可能是DeepSeek能够发挥巨大潜力的另一个行业。如果能够结合大量的医疗案例数据,DeepSeek可以帮助医生从海量的信息中提炼出最有效的治疗方案。通过智能算法,DeepSeek能够快速识别和分析病情,提出精准的诊疗建议,甚至对一些疾病的预测也能够提供支持。
尤其是在一些复杂病例中,DeepSeek能为医生提供参考和思路,提升诊疗的准确性。当然,DeepSeek不能替代医生的临床判断和经验,但它无疑是一个有效的辅助工具,提升了医疗行业的效率和精准度。
5. 程序员职业 对程序员来说,DeepSeek无疑是一款颠覆性的工具。只需提供具体的需求和编程语言,DeepSeek就能够快速生成代码片段,帮助程序员快速实现功能
在目前的技术水平下,DeepSeek生成的代码经过简单调试后,就能够投入使用。这不仅节省了程序员大量的时间,还可以大大提高工作效率
随着技术的发展,未来或许会有更高级的智能编程工具出现,能够根据不同的需求自动优化代码,甚至将一些编程工作变得更为智能化。尤其是像Python这样的解释型语言,可能会变成更加智能的解释器,进一步推动编程行业的进步
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多
本文摘自《深层认知:深层洞悉事物的商业逻辑》,小编感觉讲的挺有道理,分享出来供大家品读。小编读后感到,国内公司在管理水平提升方面仍任重道远,未来的道路依然漫长且充满挑战。
在中国企业家里,最懂“用人之道”和“管人之方”的,估计非任正非莫属。他对管理的认知极其深刻,甚至早已超越了企业的范畴,值得我们认真品味。
要知道,华为近20万名员工都是有文化的聪明人,如何把这一群聪明能干的人拧成一股绳,形成一个完善的协作机制,围绕既定目标,相互信任和协作,而不是相互猜忌和拉扯,是一件极富挑战的事。任正非卓越的领导能力在这件事上得到了淋漓尽致的体现。
任正非的管理方法总结下来就四句话,可谓一语中的:砍掉高层的“手脚”,砍掉中层的“屁股”,砍掉基层的“脑袋”,砍掉全身的“赘肉”。
砍掉高层的“手脚”
为什么要砍掉高层干部的“手脚”呢?
我们知道,传统社会讲究裙带关系。很多高层管理者喜欢有自己的亲信,把他们安插在企业的各个部门,所谓高层的“手脚”就是他们的爪牙。
如果高层管理者的爪牙太多,就会给自己谋私利,容易假公济私,形成内部派别。因此要砍掉他们的“手脚”,只留下“脑袋”用来运筹帷幄,洞察大局。
另外一层意思就是,高层可以总揽全局甚至仰望星空,但不能深扎到具体性的事务中去,高层的满腔热忱不能体现在自己卷着袖子和裤脚去下地干活上,要把一切精力和智慧都放在指挥和掌舵上。
高层管理者就是要确保公司的战略和目标是对的,要保证企业的发展节奏是合理的,确保资源配置是最优的。
所以高层有两大忌讳:第一是滥用手里的权力,安插大量爪牙和亲信;第二是用手脚上的勤快掩盖思想上的懒惰。
砍掉中层的“屁股”
为什么要砍掉中层干部的“屁股”呢?
中层干部的作用是承上启下,就是要跑上跑下,中层干部最忌讳慵懒,上下逃避责任,滋生官僚主义。因此,中层干部不能有“屁股”,人一有“屁股”就想坐着。坐在那里一动不动,有个词叫坐以待毙。
中层干部要跑起来,首先要积极地跑到基层部门了解他们的需求和困难,主动向高层干部汇报真实客观的情况,务必保持上下的通畅,杜绝形式主义,这样才能保证整个公司的协调性和一致性。
“如果中层干部天天坐在办公室里喝茶,一边揣摩高层的旨意,一边偷偷压制基层的需求,粉饰太平,明哲保身,那就会出问题。
中层干部的“屁股”不能闲着,不仅要承上启下,还得左右打通,即不谋全局者不足以谋一域,要做好和平行部门的衔接工作,坚决杜绝各人自扫门前雪的中级干部。
中层干部的承上启下,还体现在敢于直面各种责任和指标上,对高层要敢于“扛指标”,对基层要敢于“下指标”。
砍掉基层的“脑袋”
所谓基层的“脑袋”,就是指基层的各种想法。
一般来说那些初入公司的人都是基层,基层的人最需要做的是执行,一定要放弃各种想法,抛弃一切幻想,埋头往前冲。
曾经有个新员工是北大的高才生,刚到公司就给任正非写了封万言书,对公司发表了慷慨激昂的陈词,但任正非这样批复:此人假若有神经病,建议送医院治疗;若是没病,建议辞退。
马云也曾说过,刚来公司不到一年的人,千万别给我写战略陈述,千万别瞎提阿里发展大计,你成了三年的阿里人后,你讲的话我必然洗耳恭听。
也就是说,当你还是一名基层员工的时候,你只需用你的执行能力来证明自己的价值。基层员工最忌想法太多,对公司战略指手画脚,在公司制造各种负面情绪。
华为的基层员工也是社会上的佼佼者,但不管你是硕士、博士,还是留学海归,都必须遵守公司的各项制度,不能自作主张,随性发挥。
要砍掉基层的“脑袋”,就是要让团队上下一心,心往一处使,形成一个有机的整体,随时都能应对各种变化,并一步步往上走。
砍掉全身的“赘肉”
砍掉了公司里多余的“手脚”“屁股”“脑袋”,公司才能更加协调。但要想使公司走向强大,还需要最后一步,那便是砍掉全体人员的“赘肉”。
我们都知道华为员工的收入是很高的,人的收入到了一定层次就容易产生安逸的情绪,容易变得越来越懒,丧失斗志。因此,必须有一条无形的鞭子来催促大家不停地奋斗,要扬鞭策马共同迈向宏伟蓝图。
中国人的最大特点就是奋斗。如果用一个词总结中国人上下五千年的核心精神,没有哪个词比“奋斗”更合适。奋斗精神是中华民族最重要的精神财富,也是中华复兴的核心驱动力。
中华民族确实是一个既勤劳又智慧的民族,但同时我们也应该看到,如果没有一个合理的机制把大家拧成一股绳,往往会产生各种内斗和内耗。
公司的经营也是如此,必须让大家放弃投机取巧、不劳而获的幻想,鼓励踏踏实实、勤勤恳恳地去劳动,去创造。这就是华为提出的“以奋斗者为本”的核心价值观,通过各种机制避免人员小富即安的心理。
任正非决不允许出现组织“黑洞”。这个黑洞就是惰怠,不能让它吞噬了我们的光和热,吞噬了活力。
总结
总之一句话,高层要有决策力,中层要有责任感,基层要有执行力,所有人都要有奋斗精神。
不在其位就不谋其职,无论是哪个层级都要做好分内的事情,不能互相越位。而现在的很多企业,经理在埋头做具体的事,主管在上下逃避责任,员工反而在闲谈公司战略的事,这就乱套了。
当然,企业也要保证团队的流动性,要有一个机制确保有能力的人得到提拔,有能力、有抱负的基层员工能一步步往上走。只有同时做到了这一点,才能保证团队的循环和流动性,企业才能做大做强。
华为正是通过这种机制,使近20万名员工紧紧地团结在一起,凝聚成一个会“跳舞”的灵活的巨人,围绕一个核心目标不停地奋斗。
任何一个企业、一个团队、一个群体,都离不开管理。管理的本质在于治人,治人的关键在于抑制人性的阴暗面,发挥人性的光辉面,制度是关键。
华为的这套体系是符合中国企业的治理体系,值得所有的管理者借鉴。
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
作者:数据人阿多 日期:2026年4月21日
技术浪潮从来不只是带来冲击,更多时候,它送来的是镜子
焦虑之所以蔓延,很大程度上是因为我们在镜子里看到了自己曾经浮在表面上的技能轮廓。当大模型和形形色色的 Agent 能够自动生成大段代码、自动搭建项目脚手架时,那个只会调用框架、拼接 API 的自己,确实显得脆弱。但这不是终点,而是一个重新确认价值的契机
我们不妨先坦诚地面对一个事实:过去很长一段时间里,许多技术人员——包括你我——所谓的“技术能力”,其实包含了大量的模式化重复和表层组装。写 Python 脚本,很多时候是查文档、找库、复制修改示例代码。这种熟练度虽然撑起了日常工作,但它并不等同于对底层原理的透彻理解,也不等同于面对复杂非标问题时的拆解与重构能力。AI 目前所擅长的,恰恰就是吃掉这部分表层工作
于是问题变成了:当 AI 能更快地完成那部分工作时,我们的位置在哪里?答案藏在一个很容易被忽略的细节里:AI 生成的内容需要人来 Review,而且是对抗性地、审视性地 Review
这里的 Review 不是走马观花地看一遍缩进是否对齐,而是一种带有掌控感的技术审查与逻辑校验。AI 写出来的 Python 代码可能运行通过,但它对并发安全性的处理是否严谨?它对内存的隐性消耗在数据量变大后会不会成为灾难?它选用的那个第三方库是否存在尚未暴露的许可风险或维护停滞问题?它给出的架构建议是不是在用一个短期的便利去交换长期的维护成本?这些问题的答案,AI 不会主动告诉你,甚至当你询问它时,它还会用极其自信的口吻编织出一套看似逻辑自洽的谎言——这就是业内常说的“AI 幻觉”
现阶段的核心竞争力,恰恰是你是否具备一眼看穿这种“幻觉”的能力
如果一个人只是把 AI 当作输出结果的打字机,那他确实在被取代的队列里;但如果一个人把 AI 当作一个语速极快、但性格有些轻浮的技术助理,那情况就完全不同了。你需要有能力去管控它,而不是被它的“巧舌如簧”忽悠得团团转
这也引出了我想说的第二层意思:现在恰恰是借助 AI 沉下去钻研技术的最好时机
回想一下,以前想要深入搞懂某个 Python 底层的 C 扩展实现,或者想要研究异步事件循环的调度细节,最大的阻碍往往不是智力门槛,而是繁琐的准备工作和庞大的代码阅读量带来的畏难情绪
现在有了 AI,这种摩擦成本被极大降低了。你可以让它帮你瞬间画出调用图,让它用最直白的语言解释那段晦涩的 C 扩展是如何与 Python 对象交互的,让它帮你把复杂的代码块拆解成逻辑单元。但注意,AI 负责的是把路铺平,走路的必须是你自己 AI 解释了内存管理的机制,你需要亲自去验证它说的对不对,去思考为什么设计者要这样选择而不是另一种方式。这个过程,才是真正的技术沉淀
对于掌握 Python 的开发者而言,这门语言本身的动态特性和丰富的生态,既是 AI 辅助开发的优势区,也是学习深水区的绝佳入口。以前浮在表面时,你可能只关心 pip install 之后那个函数怎么调用;现在你有了一个不知疲倦的讲解员,你有条件去关心那个函数在操作系统层面到底发生了什么,去关心 GIL 锁在 IO 密集和 CPU 密集场景下的微观表现差异
所以,不用去焦虑那个会写代码的 Agent。那个 Agent 无法承担事故责任,无法理解业务背后的隐性规则,更无法在凌晨三点系统崩溃时拥有那种基于深层理解的、直觉般的修复嗅觉
焦虑的解药从来不是去和机器比速度,而是利用机器的速度,把自己托举到它够不着的地方。沉下心来,把 AI 当作你的加速器,去钻研那些因为繁琐而被你长期搁置的底层知识。当你对技术的理解能够穿透 API 的皮肤、直达骨骼与神经时,你会发现,你不仅不用担心被 AI 裁员,你反而成为了那个能够驾驭 AI、定义 AI 工作边界的人。那个位置,永远缺人
作者:数据人阿多 日期:2026年5月6日
1度电,到底能炼多少Token?这将是大模型定价的终极锚点
现在的AI圈有一个怪现象:同样的100万Token,有的厂商卖几十块,有的只卖几毛钱,还有人直接免费送 价格体系极度混乱,似乎全凭一张嘴在喊
这背后暴露了一个刺眼的真相——大模型商业落地的根基是Token,但Token的定价,至今仍然缺少一把公认的“标尺”
其实,任何可以大规模生产的数字商品,最终都会向其边际成本收敛。而Token这种商品,刨开研发摊销、硬件折旧之后,最硬的成本底线只有一个:电
所以笔者越来越强烈地感到:在不远的将来,“1度电可以生成多少Token”,将成为所有Token定价的终极极限 整条AI商业链,本质上都是在围绕这个“电-信息”的转换效率下注
01 混乱的Token定价:缺一把共同的尺子
这两年,各种Agent被包装成无所不能的数字员工,看起来百花齐放,但所有Agent归根到底只做一件事——燃烧Token来换智能 你每一次思维链、每一次调用工具、每一轮对话,背后都是Token在流动
然而奇怪的是,对于这种硬通货,全行业至今没有统一的成本衡量标准
同一个量级的模型,GPT-4o、Claude 3.5、DeepSeek、通义千问……有些按百万Token报价高达几十元,有些已经逼近几分钱。折价程度之大,显然早已超出了“技术代差”所能解释的范畴
造成这种混乱的深层原因很简单:Token定价现在根本不是基于成本,而是基于博弈 有人赌生态,先烧钱占住开发者;有人吃品牌溢价,把模型当奢侈品卖;还有人干脆把Token当引流品,赔本赚吆喝
但只要是赌局,就总有见光的时候。当潮水退去,活下来的玩家一定会问同一个问题:生产Token的物理底线,到底在哪里?
这个问题的答案,就藏在1度电里
02 Token生产的现实:1度电,目前能炼多少Token?
要找出这个底线,我们不妨先从现实世界算一笔账
以目前主流的AI推理硬件NVIDIA H100为例:一块H100在推理大模型时,实际功耗约500瓦左右,每秒大约可以生成2000个高质量Token(不同模型和精度下有所浮动,我们取一个典型的保守值)
这样算下来:
- 生成1个Token耗能 ≈ 500焦耳/秒 ÷ 2000 Token/秒 = 0.25焦耳
- 1度电 = 360万焦耳
- 1度电可生成Token数 ≈ 360万 ÷ 0.25 = 1440万Token
也就是说,现阶段以H100为标准,1度电大约可以炼出1400多万个Token 按居民电价0.5元/度折算,每百万Token的纯电力成本约为0.035元人民币
可是,你现在买过任何主流模型的API吗?哪怕是以价格战闻名的国产模型,每百万Token的公然售价也普遍在0.5-1元人民币以上,有些海外厂商更是高出几十倍电力成本在终端定价中的占比,目前只有百分之几到十几分之一
这就意味着,Token的定价里面,挤满了大量的品牌溢价、研发摊销、芯片折旧——以及,相当厚的“超额利润”
但这只是当下。当算力像自来水一样被更高效、更廉价的芯片大规模供给时,利润率必然被压缩,Token价格将不可逆转地向电力成本滑落
03 物理学天花板:兰道尔极限下的Token产能
如果我们把目光放得更远,回到物理规则本身,就会发现:1度电的Token产能,还存在一个令人窒息的理论天花板
1961年,IBM物理学家罗尔夫·兰道尔提出了一条著名的极限:在常温(300K)下,计算设备擦除1比特信息所必须消耗的最小能量约为2.75×10⁻²¹焦耳,这就是兰道尔极限
这条定律冷酷地宣告了:计算不是免费的,信息本身就是一种物理存在,创造信息就需要消耗能量
那么想象一个极端场景:未来某一天,芯片的效率逼近兰道尔极限,运行的是可以近乎完全回收中间能量的可逆计算。生成一个Token,哪怕只需要执行几百次到上千次基本的比特操作,那么:
- 每Token最低能耗 ≈ 2.75×10⁻²¹焦耳 × 1000次 = 2.75×10⁻¹⁸焦耳
- 1度电 = 3.6×10⁶焦耳
- 1度电理论极限可生成Token数 ≈ 3.6×10⁶ ÷ 2.75×10⁻¹⁸ ≈ 1.3×10²⁴个Token
这是一个天文数字。虽然现实中我们绝无可能达到这个理论值,它的意义不在于追求那个极端数字,而在于告诉我们一件事:相较于理论极限,今天1度电产1400万Token的效率,落后了十几个数量级
这中间的每一寸效率提升,都意味着“1度电能生成多少Token”这个数字会被不断改写,也意味着Token的生产成本还有极其恐怖的下降空间
04 Token定价的终极锚点:“电本位”时代正在逼近
当我们想清楚这个逻辑之后,就会发现,未来Token的定价必须回答一个核心问题:此时此刻,1度电到底能生成多少Token?
因为当算力供给足够充沛、模型能力进入同质化竞争时,谁的生产成本更低,谁就能在商业上存活下来。而那个“极限成本”,永远绕不开电费账单
届时,AI产业很可能会形成一套类似“金本位”的新定价范式——电本位Token定价,公有云上会公开标注一个透明指标:TpKWh(Token per KWh),也就是“每度电产出Token数”
这就像今天你看燃油车百公里油耗一样,会成为衡量模型、芯片甚至Agent应用的核心参数。每调用一次Agent,你知道它烧掉了多少“电当量”的Token,就能算出真正的物理成本
到那时候,Token的报价不再是杂乱无章的数字游戏,而是会变成一道简单的公式:
Token价格 = 电价 ÷ TpKWh + 边际折旧
各种Agent依然是工具,但驱动工具运转的Token,终于找到了自己的物理根基
谁能在1度电里炼出更多的Token,谁就握住了通往AI商业终极王座的钥匙
写在最后
今天我们说大模型是“电力吞噬兽”,1度电炼1400万Token也许还是赔本买卖;但如果过几年,1度电能炼出14亿、1400亿Token呢?
那将不是一回事。那将是AI真正像水电一样流进千行百业的时刻
AI商业化的所有喧嚣,最终都会回归一个朴素的问题:1度电,到底能领悟多少个Token的智能?
这个答案,就是Token定价的极限
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货